

This article introduces several papers that improve the pretraining process of BERT, including Pre-Training with Whole Word Masking for Chinese BERT, ERNIE: Enhanced Representation through Knowledge Integration, and ERNIE 2.0: A Continual Pre-training Framework for Language Understanding.
Note: These papers all implement different improvements to the masking of BERT’s pretraining phase, but do not modify the BERT model itself (based on Mask LM pretraining, Transformer model, and fine-tuning).
Therefore, for users who do not need pretraining, they can simply replace the initial model provided by Google with these models to directly enjoy their improvements (Baidu’s ERNIE and ERNIE 2.0 are based on PaddlePaddle, while TensorFlow and PyTorch users need to use third-party tools for conversion).
Before reading this article, readers need to understand the basic concepts of BERT. Unfamiliar readers can first study the BERT course [1], BERT model details [2], and BERT code reading [3].
Whole Word Masking


Basic Idea
Note: Although I am introducing the paper from Harbin Institute of Technology and iFlytek Pre-Training with Whole Word Masking for Chinese BERT, the Whole Word Mask was actually proposed by the authors of BERT. They did not publish a paper as it is a very simple (but effective) improvement.
Due to the specificity of Chinese, BERT did not provide a good Whole Word Masking model for Chinese pretraining.The Chinese Pretraining Whole Word Masking model can be downloaded here:
https://github.com/ymcui/Chinese-BERT-wwm
To solve the OOV problem, we usually segment a word into finer-grained WordPieces (unfamiliar readers can refer to Machine Translation · Word Segmentation [4] and WordpieceTokenizer [5]).BERT randomly masks these WordPieces during pretraining, which can lead to situations where only part of a word is masked. For example:

▲ Fig. Example of the Whole Word Mask model
The word probability is segmented into “pro”, “#babi”, and “#lity” three WordPieces. One possible random mask is to mask “#babi”, while “pro” and “#lity” are not masked. This prediction task becomes easier because between “pro” and “#lity” it can only be “#babi”. Thus, it only needs to remember a few words (the sequence of WordPieces) to complete the task, rather than predicting based on the semantic relationship of the context.
Similarly, the Chinese word “模型” may also be partially masked (actually, using the example of “琵琶” might be better because these two characters can only appear together and not separately), which also makes the prediction easier.
To solve this problem, a natural idea is to either mask the whole word or not mask it at all, which is called Whole Word Masking. This is a very simple idea, requiring very few modifications to the BERT code, just modifying some of the masking code. For English, tokenization is a (relatively) simple problem. The paper from Harbin Institute of Technology and iFlytek segmented Chinese and conducted some experiments.
Implementation Details
Data Preprocessing
Pretraining
Whole Word Masking can be seen as an improvement to the original BERT model, a method to increase task difficulty. Therefore, we are not pretraining from scratch, but continuing to train based on the original Chinese model released by Google (I feel another reason is that there is not enough computing resources to start from scratch).
Here, a batch size of 2,560 was used, with a maximum length of 128, trained for 100k steps, with an initial learning rate of 1e-4 (warm-up ratio is 10%). Then, with a maximum length of 512 (batch size reduced to 384), it was trained for another 100k steps, allowing it to learn longer-distance dependencies and positional encoding.
The original BERT code uses AdamWeightDecayOptimizer; here it was replaced with the LAMB optimizer because it performs better for long texts.
Fine-tuning
The fine-tuning code does not require any modifications; it simply replaces the initial model from the original WordPiece-based pretraining model to the Whole Word Masking-based pretraining model.
Experimental Results
Reading Comprehension Task
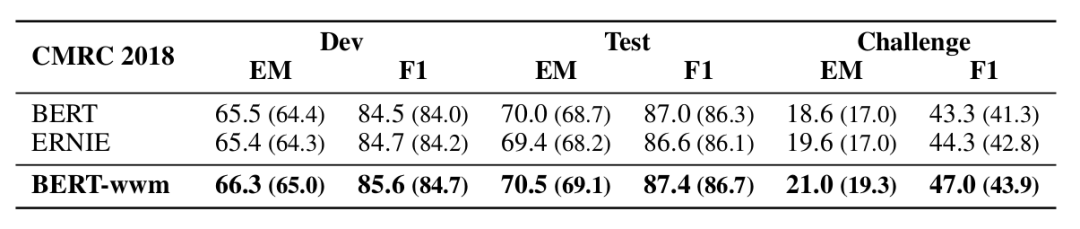
▲ Fig. Experimental results on the CMRC 2018 dataset
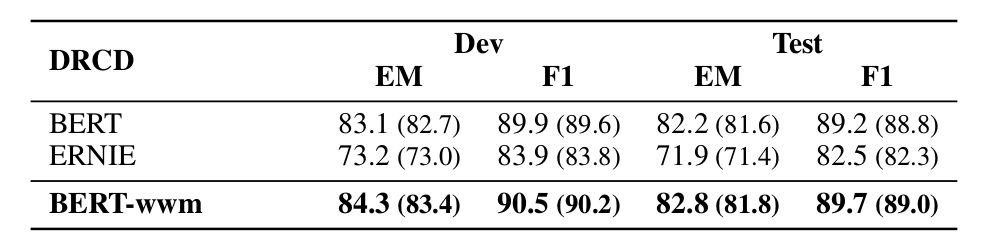
▲ Fig. Experimental results on the DRCD dataset
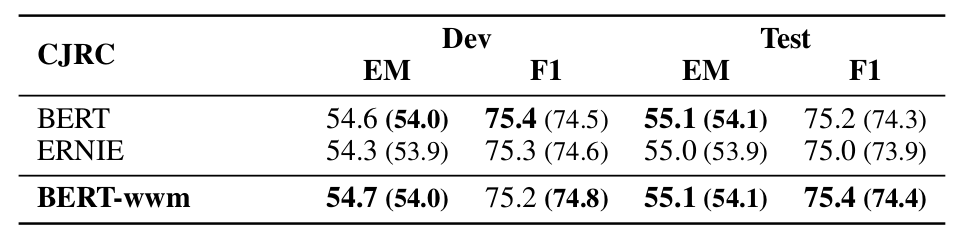
▲ Fig. Experimental results on the CJRC dataset
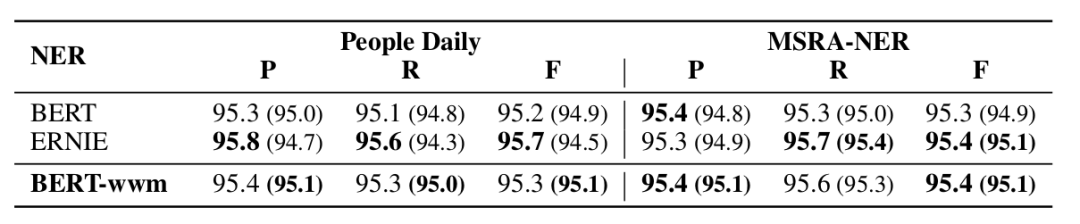
▲ Fig. Experimental results of the NER task
Natural Language Inference
Experiments were conducted on the Chinese data of the XNLI natural language inference task, with the following results.
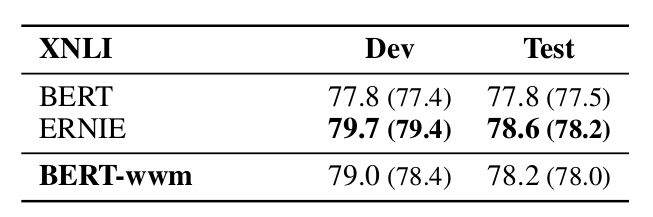
▲ Fig. Experimental results on the XNLI Chinese dataset
Sentiment Classification
Experiments were conducted on the ChnSentiCorp and Sina Weibo datasets, with the following results.
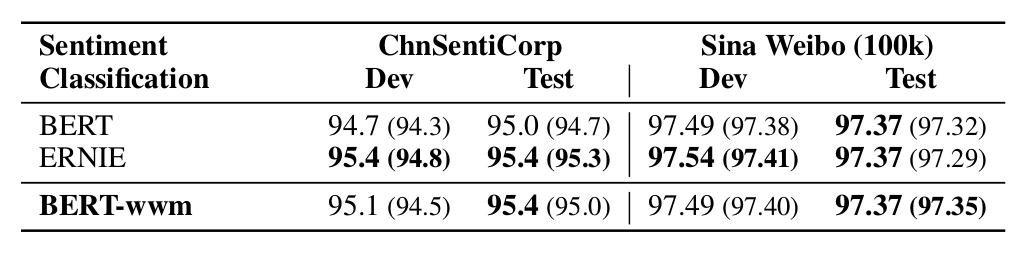
▲ Fig. Experimental results of the sentiment classification task
Sentence Pair Matching
Experiments were conducted on the LCQMC and BQ Corpus datasets, with the following results:
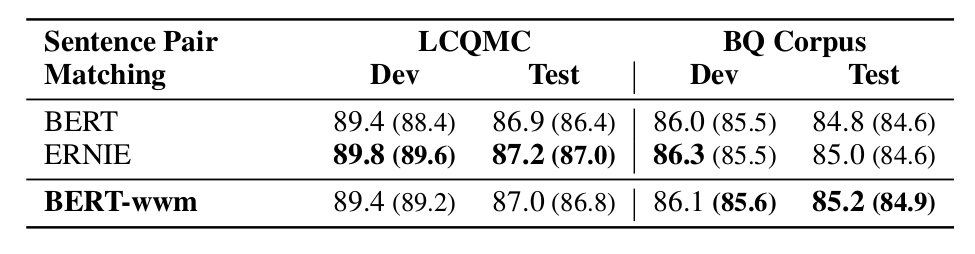
▲ Fig. Experimental results of the sentence pair matching task
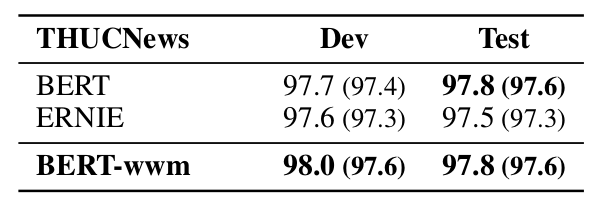
▲ Fig. Experimental results on the THUCNews dataset
Some Tips
Below are some tips summarized by the authors during implementation:
-
The initial learning rate is the most important hyperparameter, so it must be properly tuned.
-
The learning rates for BERT and BERT-wwm are the same, but if using ERNIE, adjustments are needed.
-
BERT and BERT-wwm are trained on Wiki, so they perform well on more formal and standardized datasets. Baidu’s ERNIE, however, uses data from web pages and forums, performing better in informal contexts.
-
For long texts, such as reading comprehension and document classification tasks, it is recommended to use BERT and BERT-wwm.
-
If the domain of the task is significantly different from Wiki and we have a lot of unlabeled data, it is recommended to use domain data for pretraining.
-
For Chinese (both simplified and traditional), it is recommended to use the BERT-wwm (rather than BERT) pretraining model.
Update
ERNIE


Basic Idea
ERNIE is a model proposed by Baidu in the paper ERNIE: Enhanced Representation through Knowledge Integration, which actually introduced the masking method at the phrase and entity level earlier than Whole Word Masking.
Although its name is somewhat grand: Enhanced Representation through Knowledge Integration (ERNIE), its idea is actually very similar to the previous Whole Word Masking, just expanding the masking unit from words to phrases and entities.
The publication date of this paper is actually earlier than that of Whole Word Masking, so we can consider that Whole Word Masking may have drawn inspiration from its ideas (the arXiv paper was published on 2019/4/19, while the update of the English Whole Word Masking model for BERT was on 2019/5/31). I place it here later for the purpose of grouping Baidu’s two papers together.
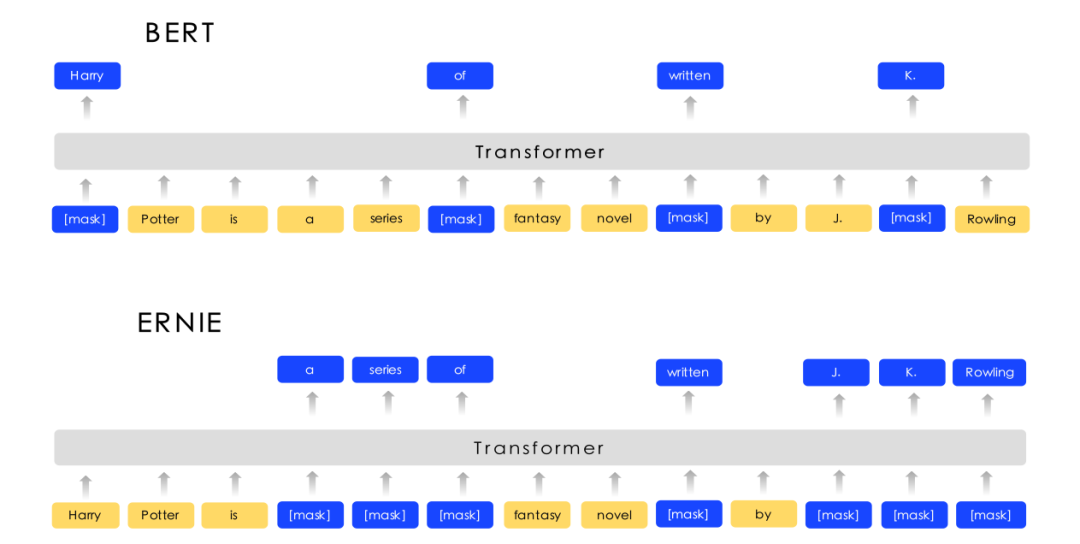
▲ Fig. Comparison of ERNIE and BERT
As shown in the figure, ERNIE masks the phrase “a series of” and the entity “J. K. Rowling” as a whole (or not mask them).
Of course, NLP tools are required to identify phrases and entities. For English phrases, chunking tools can be used, while for Chinese, Baidu has its own tool for identifying phrases. The details of the entity recognition tool are not mentioned in the paper.
Pretraining Data
The training data includes Chinese Wiki, Baidu Encyclopedia, Baidu News, and Baidu Tieba data, with sentence counts of 21M, 51M, 47M, and 54M respectively, totaling 173M sentences.
Additionally, all traditional Chinese was converted to simplified Chinese, and English was converted to lowercase. The model’s vocabulary size is 17,964.
Multi-level Mask Training
ERNIE does not use WordPiece, but treats words as basic units. It includes three levels of masking: basic, phrase, and entity, as shown in the figure below.

▲ Fig. Different levels of masking for a sentence
During training, it first trains based on the basic level of masking. For English, words are separated by spaces; for Chinese, it is by characters. The basic level for English is similar to BERT’s Whole Word Masking, but for Chinese, it is equivalent to the original BERT.
Next, it trains based on the phrase level of masking, allowing it to learn higher-level semantics such as phrases. Finally, it trains using entity-level masking.
Dialogue Language Model
In addition to Mask LM, for dialogue data (forums), ERNIE also trained what is called a Dialogue LM, as shown in the figure below.
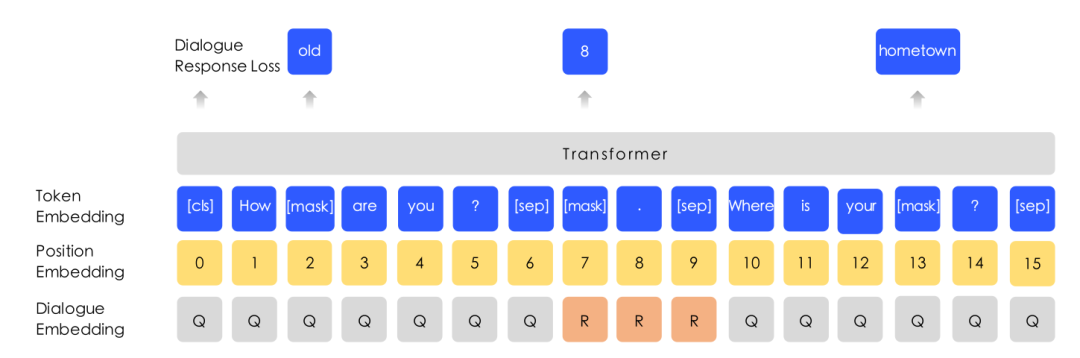
▲ Fig. Dialogue Language Model
The original dialogue consists of three sentences: “How old are you?”, “8.” and “Where is your hometown?”. The model’s input consists of three sentences (instead of two as in BERT), separated by SEP, and each represented by Dialogue Embedding Q and R for Query and Response, respectively. This embedding is similar to BERT’s Segment Embedding, but it involves three sentences, which can lead to combinations like QRQ, QRR, QQR, etc.
Experiments
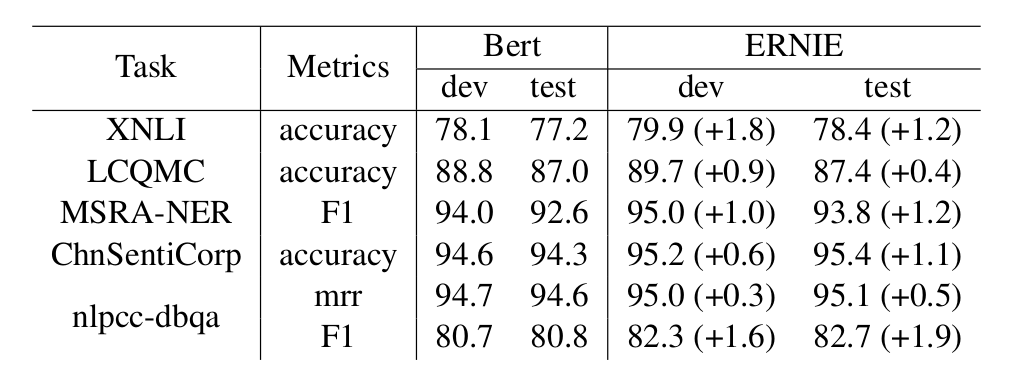
The paper conducted comparative experiments on five Chinese NLP tasks, including XNLI, LCQMC, MSRA-NER, ChnSentiCorp, and NLPCC-DBQA, against BERT, as shown in the table below:
Ablation Analysis
The paper used 10% of the data for analysis, as shown in the table below:

▲ Fig. Ablation analysis of different masking strategies
Using only the basic level (characters in Chinese), the result on the test set is 76.8%. After using the phrase, it improves by 0.5% to 77.3%, and after adding the entity, it can increase to 77.6%.
To verify the effectiveness of the Dialog LM, the paper compared three data extraction methods for 10% of the data, including extracting all from the encyclopedia, encyclopedia (84%) + news (16%), and encyclopedia (71.2%) + news (13%) + forums (15.7%). The comparison results for the XLNI task are as follows:

▲ Fig. Ablation analysis of the effect of Dialog LM
It can be seen that Dialog LM is very helpful for inference tasks like XLNI. Note: I believe this experiment has some issues; the improvement may be due to the data (forums) rather than the Dialog LM itself. A better experiment might involve training another model with data from the encyclopedia (84%) + news (16%) and encyclopedia (71.2%) + news (13%) + forums (15.7%), but this time without training the Dialog LM, instead using a regular Mask LM, to see the results of this model and determine the contribution of the Dialog LM.
Fill-in-the-blank Comparison
Additionally, the paper compared the fill-in-the-blank task between BERT and ERNIE models. This involves removing entities from some test sentences and having the model predict the most likely words. Below are some examples (not sure if they were carefully chosen):
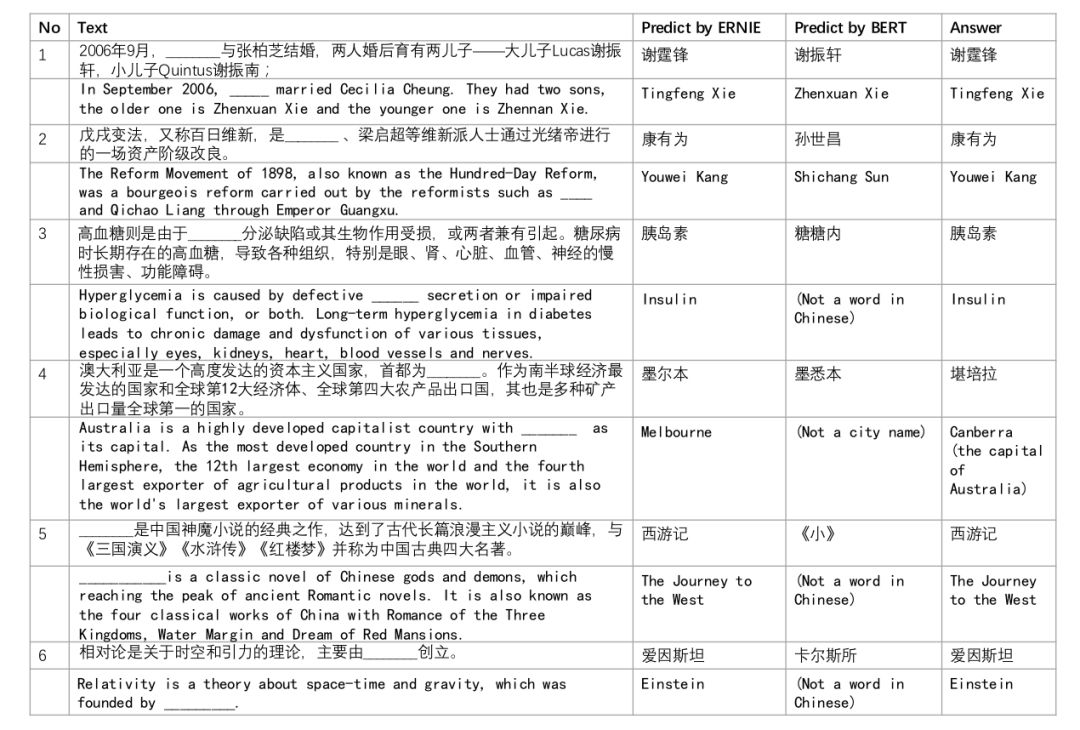
▲ Fig. Ablation analysis of the effect of Dialog LM
ERNIE 2.0


Basic Idea
ERNIE 2.0 has a new name: A Continual Pre-training framework for Language Understanding. This name is more low-key and pragmatic, but seems to have little relation to the acronym ERNIE.
The authors believe that previous models, such as BERT, only use the co-occurrence of words as statistical information to learn context-related word embeddings by training language models. ERNIE 2.0 hopes to utilize various unsupervised (weakly supervised) tasks to learn lexical, syntactic, and semantic information, rather than just the co-occurrence of words.
Since many new tasks are introduced, it is a natural idea to train them together as multi-task learning. However, training all tasks simultaneously may be difficult (this is just my guess), so using an incremental approach would be simpler: first train one task; then add a new task to form multi-task learning; then increase to three tasks for multi-task learning…
ERNIE 2.0 Framework
Based on the previous introduction, ERNIE 2.0 is actually a framework (method), and it can use either Transformer or RNN; of course, based on the experience with BERT, using Transformer is better. The core of the ERNIE 2.0 framework is the following two points: Construct multiple unsupervised tasks to learn lexical, syntactic, and semantic information; Incremental approach for multi-task learning.
The ERNIE 2.0 framework is shown in the figure below:
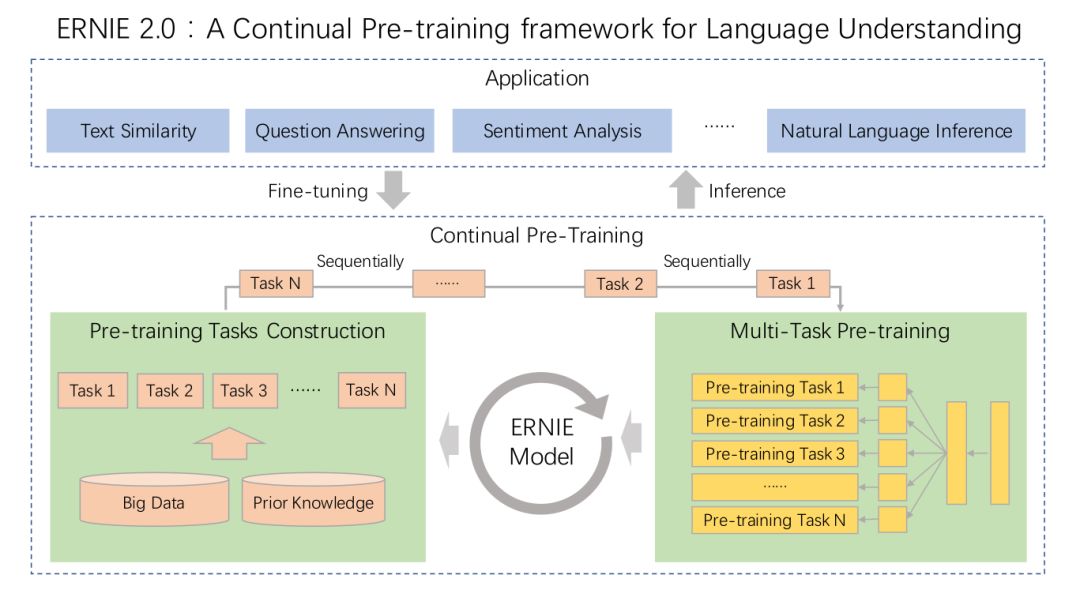
▲ Fig. ERNIE 2.0 framework
The continual pretraining process includes two steps. The first step is to continuously construct unsupervised tasks through large data and prior knowledge. The second step is to incrementally update the ERNIE model through multi-task learning.
For pre-training tasks, we will construct different types of tasks, including word-aware, structure-aware, and semantic-aware tasks, to learn lexical, syntactic, and semantic information. All these tasks rely only on self-supervised or weakly supervised signals, which can be obtained from large amounts of data without manual labeling.
For multi-task pre-training, ERNIE 2.0 uses an incremental continual learning approach for training. Specifically, we first train an initial model with a simple task, then introduce new tasks to update the model. When a new task is added, we initialize the current model using the parameters of the previous model.
After introducing new tasks, it does not only use the new task for training; instead, it learns both the previous tasks and the newly added tasks through multi-task learning, so it has to learn new information while not forgetting old information. Through this approach, ERNIE 2.0 can continuously learn and accumulate all the knowledge learned during this process, thus achieving better results on new downstream tasks.
As shown in the figure below, during continual pre-training, different tasks use the same network structure to encode contextual text information, allowing shared learning of the acquired knowledge. We can use RNN or deep Transformer models, and these parameters will be updated across all pre-training tasks.
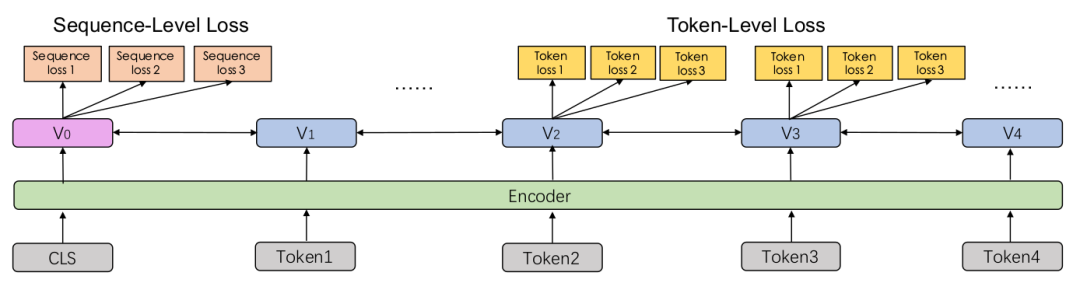
▲ Fig: Multi-task learning architecture of the ERNIE 2.0 framework
As shown in the figure, our framework has two types of loss functions. One is the sequence-level loss, calculated using the output of CLS; the other is the token-level loss, where each token has an expected output, allowing us to calculate the loss based on the predicted and expected values of the model. Different pre-training tasks have their own loss functions, and the loss functions of multiple tasks are combined as the loss for this multi-task pre-training.
Model Network Structure
The model samples a Transformer Encoder model similar to BERT. To allow the model to learn task-specific information, ERNIE 2.0 also introduces Task Embedding. Each task has an ID, and each task is encoded into a learnable vector, allowing the model to learn information related to a specific task.
The network results are shown in the figure below:
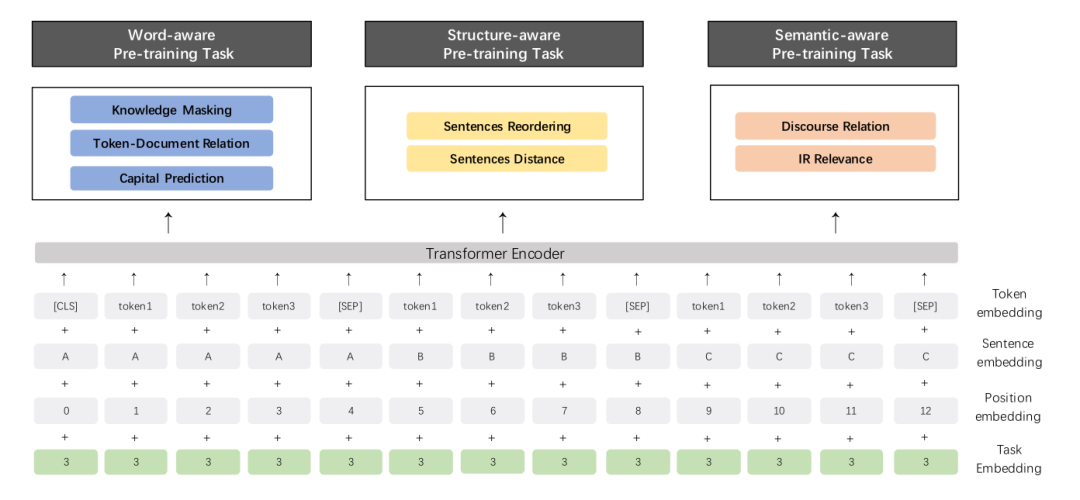
▲ Fig: Network structure of the ERNIE 2.0 framework
In addition to BERT’s Word Embedding, Position Embedding, and Sentence Embedding (basically equivalent to Segment Embedding), the figure also includes a Task Embedding. Additionally, the Encoder’s output will be used for multi-task learning across multiple tasks (including word-aware, structural-aware, and semantic-aware), rather than just for a Mask LM and next sentence prediction as in BERT (and XLNet only has one Permutation LM).
Pre-training Tasks
Word-aware Tasks
1. Knowledge Masking Task:This is actually the task from ERNIE 1.0, including tasks obtained from word, phrase, and entity-level masking.
2. Capitalization Prediction Task:Predicting whether a word is capitalized. For English, capitalized words often indicate named entities, so this task can learn some entity knowledge.
3. Token-Document Relation Task:Predicting whether the current word appears in other documents. A word that appears in multiple documents is either a common word or a word shared by the themes of the two documents. This task allows it to learn the common themes across multiple documents.
Structure-aware Tasks
1. Sentence Reordering Task:Given a paragraph, it is first randomly divided into 1 to m segments. Then, the segments are randomly shuffled (the words within segments are not shuffled), and the model is tasked with restoring them. How to restore? A very simple classification method is used, with a total of  categories.This is a classification task that allows the model to learn paragraph structure information.
categories.This is a classification task that allows the model to learn paragraph structure information.
2. Sentence Distance Task:A task regarding the “distance” between two sentences, with three possible relationships (3-class classification task): they are adjacent sentences; they are not adjacent but belong to the same document; they belong to different documents.
Semantic-aware Tasks
1. Discourse Relation Task:This task asks the model to predict the semantic or rhetorical relationship between two sentences, following the work of Mining discourse markers for unsupervised sentence representation learning [9] that interested readers can refer to.
2. IR Relevance Task:This utilizes data from search engines (Baidu’s advantage) to classify given queries and search results (which can be considered summaries of relevant web pages) into three categories: highly relevant, weakly relevant, and completely irrelevant.
Experiments
The paper conducted comparative experiments on English using the GLUE dataset against BERT and XLNet, and on Chinese datasets against BERT and ERNIE 1.0.
Pretraining Data
The English data used Wiki and BookCorpus, the same as BERT, and also crawled some Reddit data. Additionally, the Discovery dataset was used for discourse structure relationship data. For Chinese, data from encyclopedias, news, dialogues, searches, and discourse structure relationships were used. Detailed information is shown in the table below:

▲ Fig. Details of pretraining data
Pretraining Settings
To compare with BERT, we use exactly the same settings. The basic (base) model contains 12 layers, each with 12 self-attention heads, and a hidden unit size of 768. The large model contains 24 layers, 16 self-attention heads, and a hidden unit size of 1024. The XLNet model settings are the same as BERT’s.
ERNIE 2.0’s base model uses 48 NVIDIA v100 GPUs for training, while the large model uses 64 v100 GPUs for training. ERNIE 2.0 is implemented using PaddlePaddle, a deep learning platform open-sourced by Baidu.
The paper used the Adam optimizer, with β1=0.9, β2=0.98, and a batch size of 393216 tokens.The learning rate for English is 5e-5, while for Chinese it is 1.28e-4. The learning rate decay strategy is noam [10], with a warmup for the first 4000 steps.To save memory, float16 is used. Each pretraining is trained until convergence.
Experimental Tasks
The English experiments used the GLUE [11]; while the Chinese tasks are similar to the previous Whole Word Masking, which will not be detailed here. Interested readers can refer to the paper or code.
Experimental Results
The English results are shown in the table below:
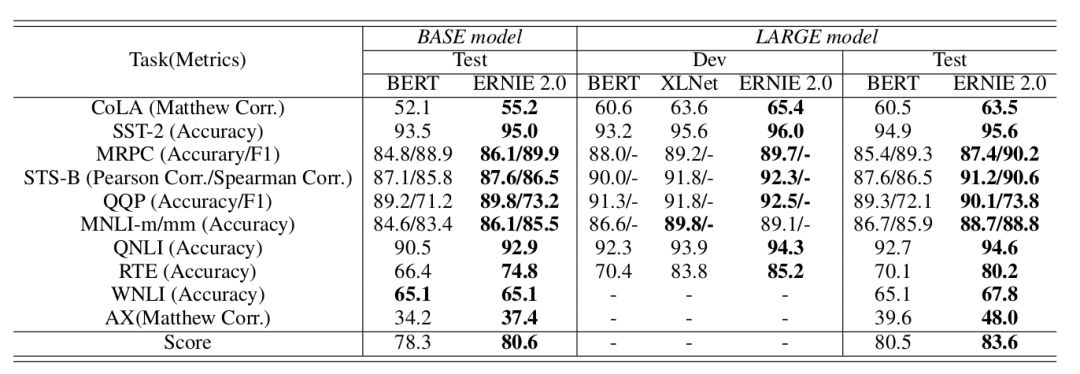
▲ Fig. Experimental results on the GLUE dataset
We can see that both the basic and large models of ERNIE 2.0 achieve SOTA results on the test set.
The Chinese results are shown in the table below:
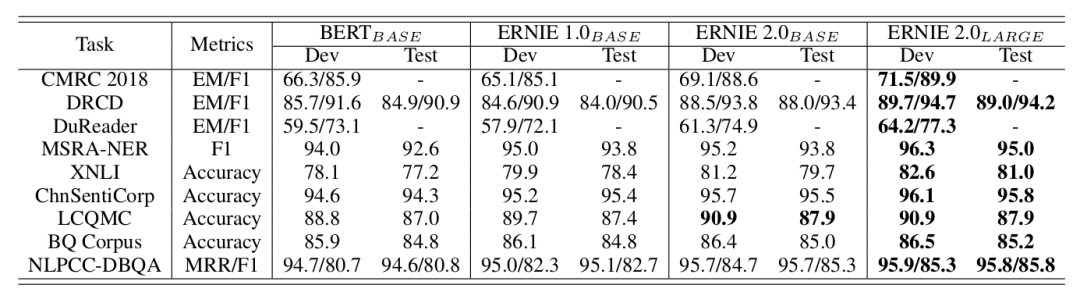
▲ Fig. Experimental results on Chinese datasets
Code
Interested readers can download the pre-trained ERNIE 2.0 model and fine-tuning code (but not the pre-training code and data):
https://github.com/PaddlePaddle/ERNIE
Outlook
As we enter 2019, unsupervised contextual word embedding has become the hottest research direction in the NLP field, and it won’t be long before new models emerge to top the charts. This indicates that a wealth of useful semantic knowledge is contained in the vast amounts of unlabeled text, and we hope to leverage this data for unsupervised pre-training.
From the success of ERNIE 2.0, constructing more tasks allows the model to learn more knowledge, and the key to success is how to construct the supervisory signals for these tasks (which obviously cannot be manually labeled).
Moreover, whether this behavior of simply relying on model size and training data to top the charts is sustainable has recently attracted ongoing attention in the academic community. This direction can only be played by a few commercial companies with data and computational resources, and many papers do not actually demonstrate significant innovation.
Additionally, many conclusions in papers may actually be contradictory. For example, Facebook’s recent RoBERTa: A Robustly Optimized BERT Pretraining Approach [12] does not involve any model structure, merely improving the pretraining method, yet it outperforms XLNet on certain datasets, raising questions about whether XLNet’s improvements are due to the Permutation LM or simply because it was trained more effectively than BERT.
Including the so-called Knowledge proposed by ERNIE 1.0 (which refers to phrases and entities), but the simple Whole Word Masking model from Harbin Institute of Technology and iFlytek performed better than ERNIE 1.0, which also raises doubts about whether the improvements of ERNIE 1.0 stemmed from its data (which included data from Baidu Encyclopedia, news, and forums beyond just Wikipedia).
On the other hand, if everyone focuses on topping the charts rather than considering the fundamental issues of NLP or even AI, simply waiting for hardware improvements is also quite concerning. Does the success of BERT rely on spurious statistical cues? In an article, I also analyzed the academic community’s concerns about this kind of brute-force aesthetics, which interested readers can also read.
Related Links
[1] https://fancyerii.github.io/2019/03/05/bert-prerequisites/
[2] https://fancyerii.github.io/2019/03/09/bert-theory/
[3] https://fancyerii.github.io/2019/03/09/bert-codes/
[4] https://fancyerii.github.io/books/mt/#%E5%88%86%E8%AF%8D
[5] https://fancyerii.github.io/2019/03/09/bert-codes/#wordpiecetokenizer
[6] https://dumps.wikimedia.org/zhwiki/latest/
[7] https://github.com/attardi/wikiextractor/blob/master/WikiExtractor.py
[8] http://ltp.ai/
[9] https://arxiv.org/pdf/1903.11850.pdf
[10] https://arxiv.org/pdf/1706.03762
[11] https://gluebenchmark.com/
[12] https://arxiv.org/pdf/1907.11692
Click the title below to see more past content:
-
Lightweight Information Extraction Model Based on DGCNN and Probabilistic Graph
-
ACL 2019 | Knowledge-enhanced Language Representation Models
-
Pre-training Methods for Language Models in Natural Language Processing
-
A Bunch of Chinese (BERT, etc.) Pre-trained Models Waiting for You!
-
When Bert Meets Keras: This Might Be the Easiest Way to Open Bert
-
NLP Newcomers Standing on BERT’s Shoulders: XLMs, MASS, and UNILM
-
Intent Recognition Cold Start Based on Few-shot Learning
 #Book Recommendations#
#Book Recommendations#
Deep Learning Theory and Practice: Basic Edition

Compiled by Li Li
This book not only covers the basics of artificial intelligence, machine learning, and deep learning, such as convolutional neural networks, recurrent neural networks, and generative adversarial networks, but also includes a small amount of knowledge on how to use the three mainstream deep learning frameworks: TensorFlow, PyTorch, and Keras; it provides in-depth explanations of relevant theories and practical techniques, including common optimization techniques, multi-GPU training, debugging programs, and deploying models to production systems.
The book aims to balance theory and practice, allowing readers to deeply understand theoretical knowledge while applying it in practice. Therefore, after introducing each model, the book will also introduce its implementation, enabling readers to run, read, and modify the related code after reading the introduction of a model, thus gaining a deeper understanding of the theoretical knowledge.

Long press to recognize the QR code for details
🔍
Now, you can also find us on “Zhihu”
Search for “PaperWeekly” on the Zhihu homepage
Click “Follow” to subscribe to our column
About PaperWeekly
PaperWeekly is an academic platform for recommending, interpreting, discussing, and reporting cutting-edge research papers in artificial intelligence. If you are researching or working in the AI field, you are welcome to click “Discussion Group” in the WeChat public account backend, and the assistant will take you into the PaperWeekly discussion group.

▽ Click | Read the original text | Visit the author’s blog