I have read some papers and training data on Qwen2.5 Coder and summarized them.
Paper link:
https://arxiv.org/pdf/2409.12186
1. Introduction
The Qwen2.5-Coder series is a major upgrade from its predecessor CodeQwen1.5, aimed at achieving top-notch code task performance across various model sizes. This series includes six models:
-
Qwen2.5-Coder-0.5B
-
Qwen2.5-Coder-1.5B
-
Qwen2.5-Coder-3B
-
Qwen2.5-Coder-7B
-
Qwen2.5-Coder-14B
-
Qwen2.5-Coder-32B
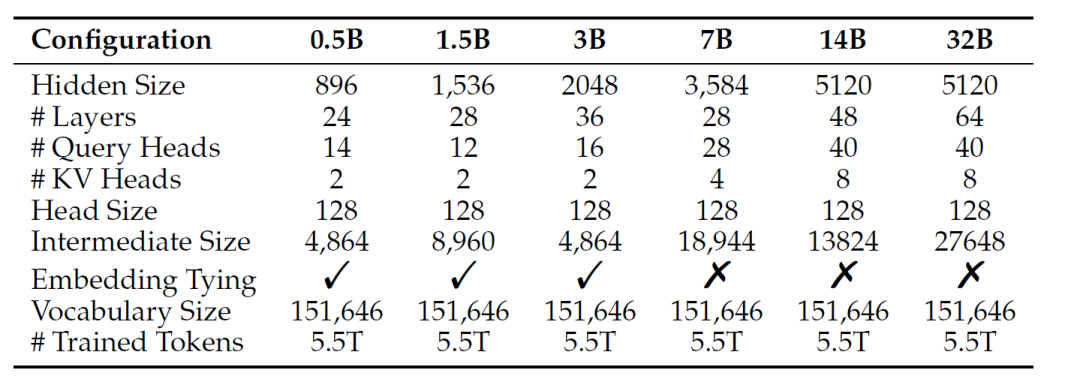

The architecture of Qwen2.5-Coder directly inherits from Qwen2.5. Different model sizes have adjustments in hidden layer size, number of layers, and number of heads to meet different performance and resource requirements. For instance, smaller models utilize embedding sharing techniques while larger models do not. Moreover, all these models support a maximum context length of 128K, enabling them to handle ultra-long code sequences.
2. Pre-training Data
To build a robust foundational model, Qwen2.5-Coder has been pre-trained on a large amount of diverse and high-quality data:
-
Source Code Data: Collected public code repositories created on GitHub before February 2024, covering 92 programming languages. A series of rule-based filters were applied to ensure data quality.
-
Text-Code Mixed Data: Extracted documents, tutorials, blogs, etc., related to code from Common Crawl. A coarse-to-fine hierarchical filtering strategy was employed, using small models for refinement, ensuring data relevance and quality.
-
Synthetic Data: Generated large-scale synthetic code data using the previous generation model CodeQwen1.5, and verified the executability of the code through executors to reduce hallucination risks.
-
Mathematical Data: Introduced pre-training corpora from Qwen2.5-Math to enhance the model’s mathematical reasoning capabilities.
-
General Text Data: Included high-quality general natural language data to ensure that the model retains good general language understanding and generation capabilities while preserving coding abilities.

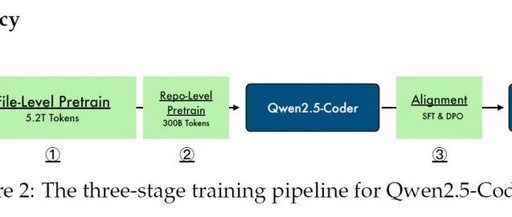
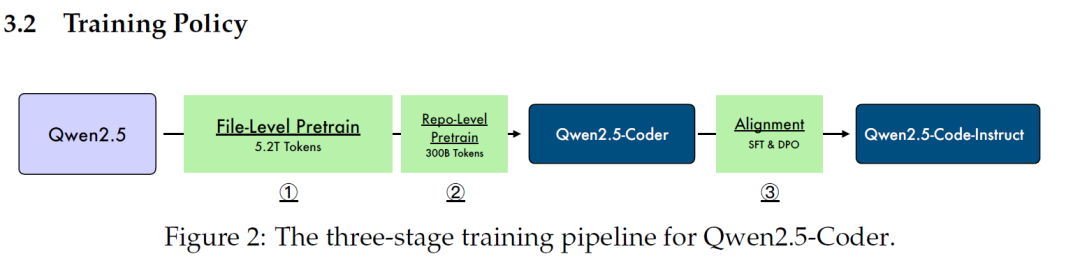
3. Training Strategy
Qwen2.5-Coder adopts a three-stage training strategy:
-
File-Level Pre-training: Focuses on learning single code files with a sequence length of 8,192 tokens, mainly aiming at next token prediction and Fill-in-the-Middle (FIM).

Example:

-
Repository-Level Pre-training: Extends the context length to 32,768 tokens and adjusts the RoPE positional encoding parameters. Through the YARN mechanism, the model can handle sequences of up to 131,072 tokens.


-
Instruction Fine-tuning: Constructed a high-quality code instruction dataset, including multilingual code generation, fixing, and understanding tasks. Through mixed fine-tuning and Direct Preference Optimization (DPO), the model is adjusted to become a powerful code assistant.
4. Practical Applications
The Qwen2.5-Coder series models have shown great potential in practical applications:
-
Code Assistant and Editing: The model can understand natural language instructions, perform code generation, fixing, and optimization, helping developers improve efficiency.
-
Cross-Language Code Generation: Supports code generation and understanding in multiple programming languages, adapting to different development needs.
-
Long Context Handling: Supports ultra-long sequences, enabling it to handle large codebases and complex projects, providing new possibilities for code analysis and understanding.
5. Training Material Reference
https://github.com/QwenLM/Qwen2.5-Coder
-
Evaluation Data and Result Files:
These files are located in the
<span>qwencoder-eval</span>directory under<span>base</span>, mostly existing evaluation benchmark datasets such as HumanEval, CruxEval, BigCodeBench, etc. These datasets are generally used for evaluating model performance, not for pre-training.<span>outptus</span>directory files may contain model outputs and evaluation metrics on these evaluation datasets.
-
<span>./qwencoder-eval/base/eval_cache/evalplus/HumanEvalPlus-v0.1.9.jsonl</span> -
<span>./qwencoder-eval/base/benchmarks/cruxeval/data/cruxeval.jsonl</span> -
<span>./qwencoder-eval/base/benchmarks/bigcodebench/data/bigcodebench_full.json</span> -
<span>./qwencoder-eval/base/outptus/qwen2.5-coder/*/bigcodebench/*/*.jsonl</span> -
<span>./qwencoder-eval/base/outptus/qwen2.5-coder/*/evalplus/*/*.jsonl</span> -
<span>./qwencoder-eval/base/outptus/qwen2.5-coder/*/cruxeval/*/*.json</span>
Multilingual Evaluation Data:
These files are HumanEval datasets in multiple programming languages, used to evaluate the model’s code generation capability in different languages.
-
<span>./qwencoder-eval/base/benchmarks/multiple-eval/data/humaneval-*.jsonl</span> -
<span>./qwencoder-eval/instruct/multipl_e/chat/data/humaneval/humaneval-*.jsonl</span>
Fill-in-the-Middle (FIM) Evaluation Data:
These files are used to evaluate the model’s Fill-in-the-Middle capability.
-
<span>./qwencoder-eval/base/benchmarks/fim-bench/hm_fim/data/fim_singleline.jsonl</span>
Model Outputs and Evaluation Results:
These files contain the model’s generation results and evaluation results on the evaluation datasets, used to assess the model’s performance on various tasks.
-
<span>./qwencoder-eval/base/outptus/qwen2.5-coder/*</span> -
<span>./qwencoder-eval/instruct/multipl_e/chat/results/*/*.jsonl</span> -
<span>./qwencoder-eval/instruct/livecode_bench/*/*.jsonl</span> -
<span>./qwencoder-eval/instruct/eval_plus/data/*.jsonl</span>
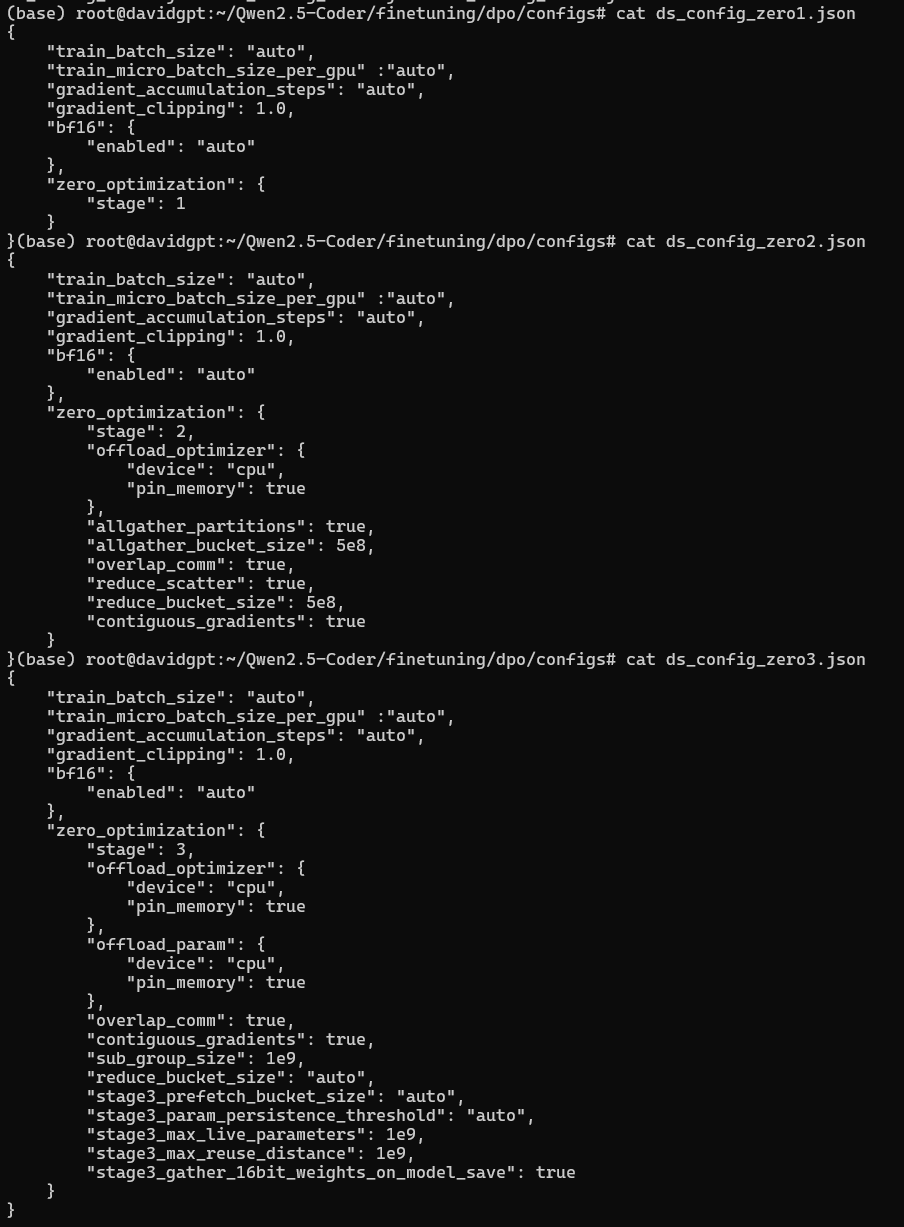
Fine-tuning and DPO Stage Configuration Files:
-
<span>./finetuning/dpo/configs/*.json</span>
-
<span>./finetuning/sft/configs/*.json</span>