
Reported by Machine Heart

-
Section 2 will briefly introduce self-supervised learning, which is the core technology of T-PTLM.
-
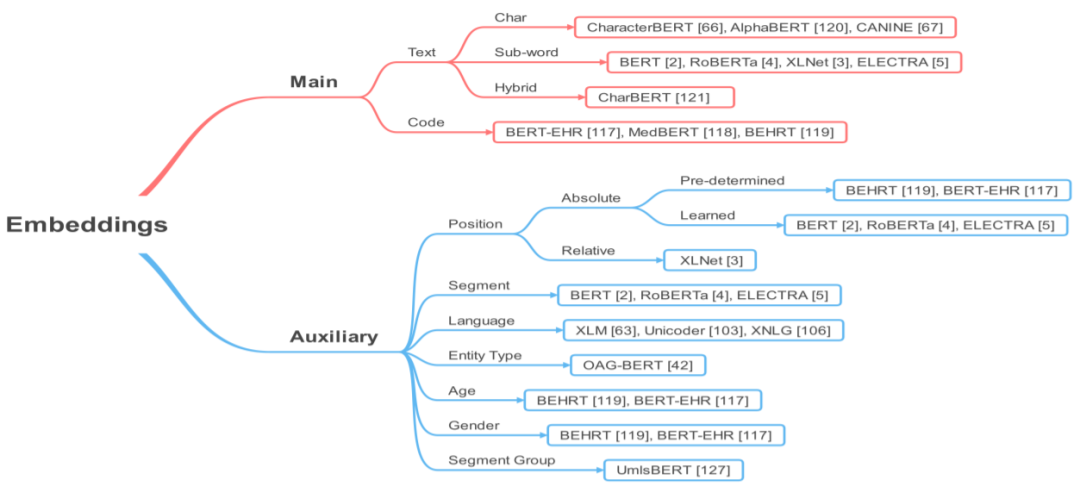
Section 3 will introduce some core concepts related to T-PTLM, including pre-training, pre-training methods, pre-training tasks, embeddings, and downstream adaptation methods.
-
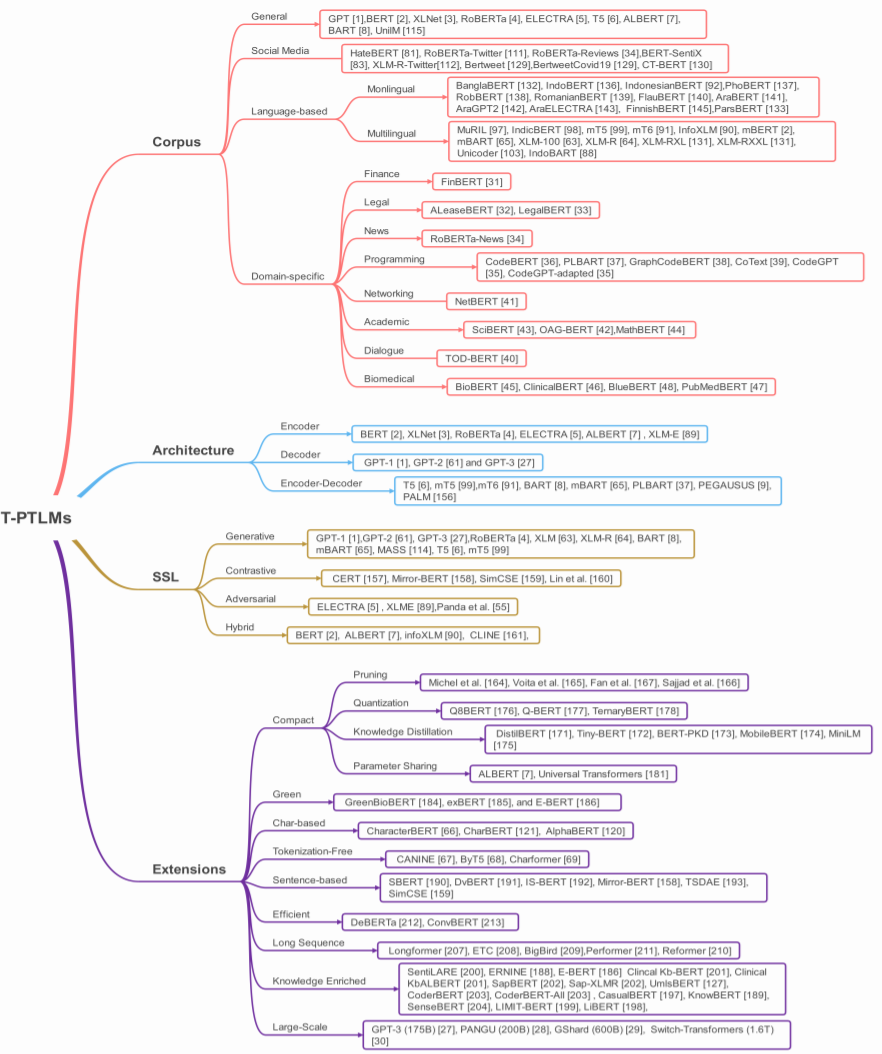
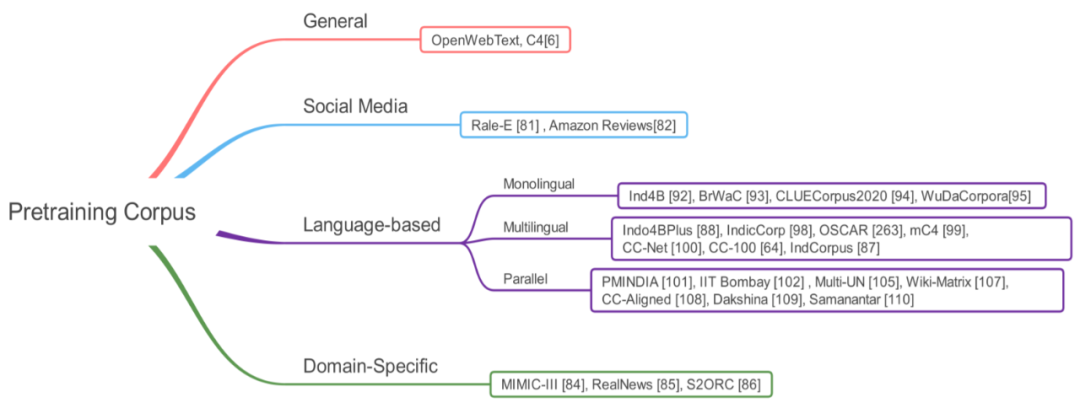
Section 4 will provide a new classification method for T-PTLM. This classification considers four aspects: pre-training corpus, architecture, type of self-supervised learning, and expansion methods.
-
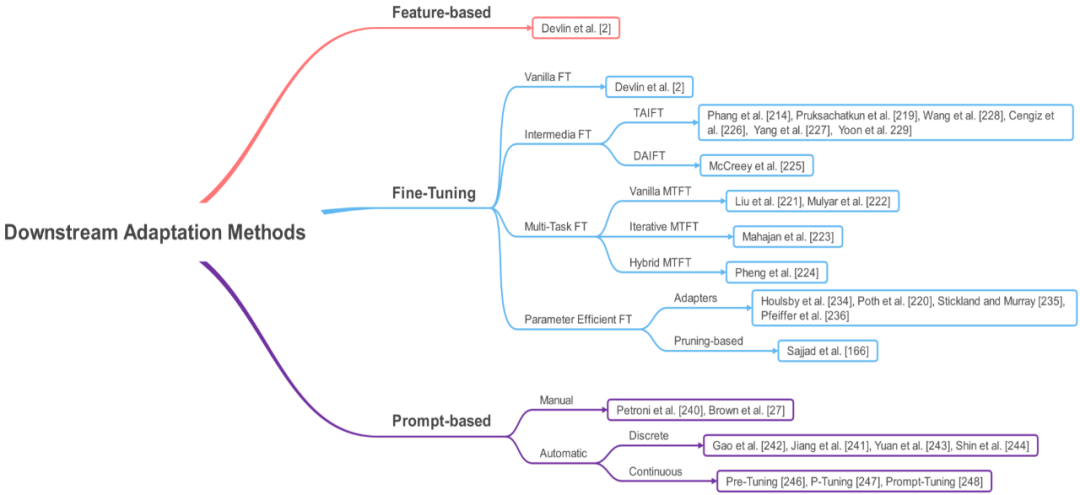
Section 5 will provide a new classification for different downstream adaptation methods and explain each category in detail.
-
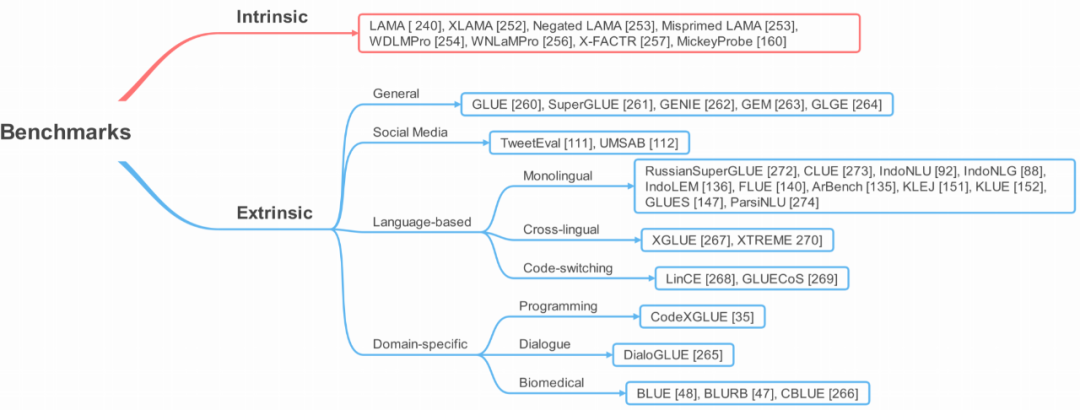
Section 6 will briefly introduce various benchmarks used to evaluate the progress of T-PTLM, including internal and external benchmarks.
-
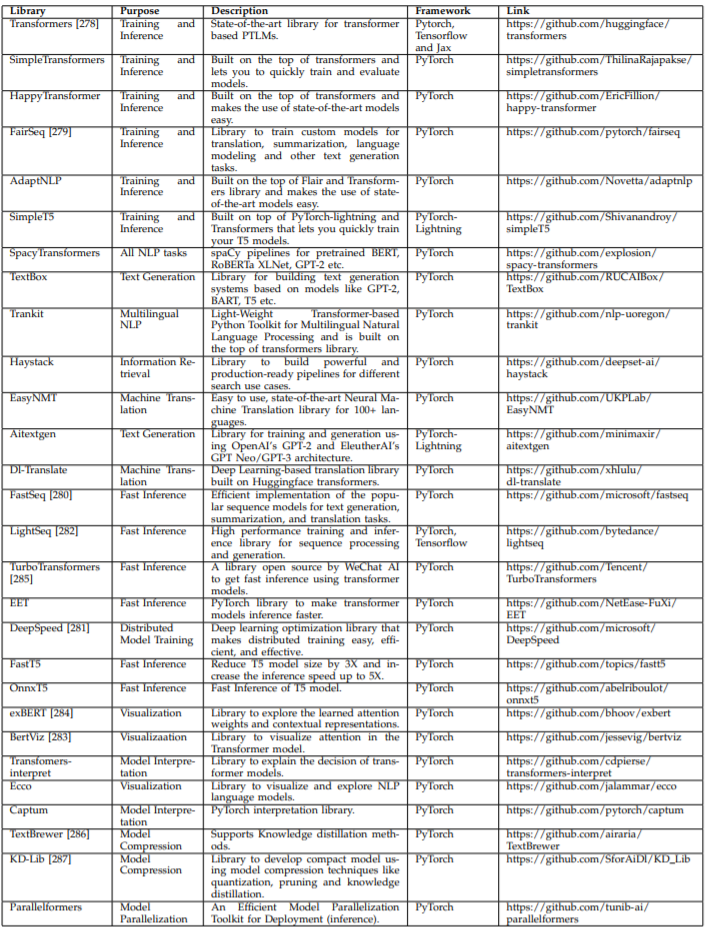
Section 7 will provide some software libraries applicable to T-PTLM, from Huggingface Transformers to Transformer-interpret.
-
Section 8 will briefly discuss some future research directions that may help further improve these models.
-
It heavily relies on human-labeled instances, the acquisition of which is time-consuming and labor-intensive.
-
Lacks generalization ability and is prone to false correlation issues.
-
Many fields, such as healthcare and law, lack labeled data, which limits the application of AI models in these areas.
-
It is difficult to learn from a large amount of freely available unlabeled data.
-
To learn universal language representations that can provide excellent background for downstream models.
-
To achieve better generalization by learning from a large amount of freely available unlabeled text data.
-
By utilizing a large amount of unlabeled text, pre-training helps the model learn universal language representations.
-
Pre-trained models can adapt to downstream tasks with just a couple of additional task-specific layers. Therefore, this provides a good initialization, avoiding the need to train downstream models from scratch (only training task-specific layers).
-
Allows models to achieve better performance with small datasets, thus reducing the need for a large number of labeled instances.
-
Deep learning models tend to overfit when trained on small datasets due to their large number of parameters. Pre-training can provide a good initialization, thus avoiding overfitting on small datasets, making pre-training a form of regularization.
-
Preparing the pre-training corpus
-
Generating the vocabulary
-
Designing pre-training tasks
-
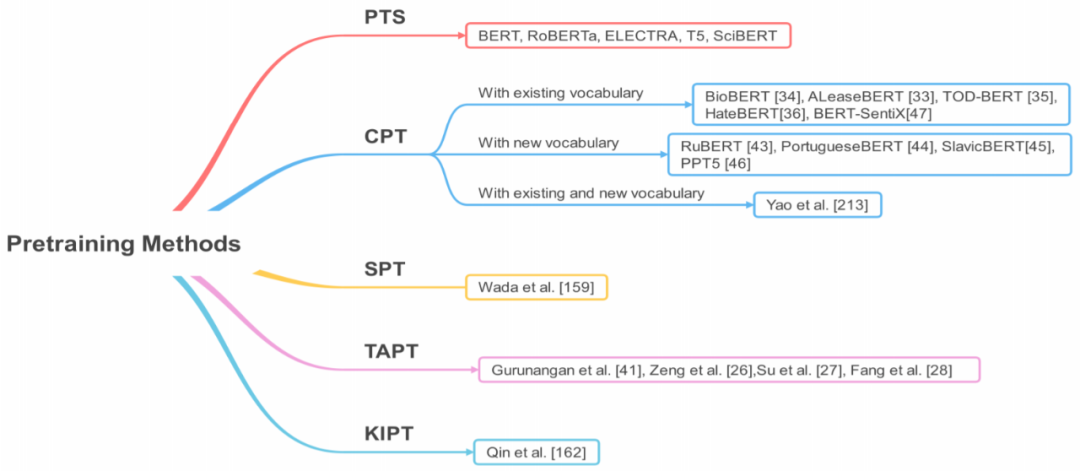
Selecting pre-training methods
-
Selecting pre-training dynamics
-
Casual Language Modeling (CLM)
-
Masked Language Modeling (MLM)
-
Replacement Token Detection (RTD)
-
Shuffled Token Detection (STD)
-
Random Token Substitution (RTS)
-
Swap Language Modeling (SLM)
-
Translation Language Modeling (TLM)
-
Alternative Language Modeling (ALM)
-
Sentence Boundary Objective (SBO)
-
Next Sentence Prediction (NSP)
-
Sentence Order Prediction (SOP)
-
Sequence-to-Sequence Language Modeling (Seq2SeqLM)
-
Denoising Autoencoder (DAE)