Paper Link:https://arxiv.org/pdf/2412.15115
Github Code:
https://github.com/QwenLM/Qwen2.5
The technical report of the Qwen2.5 series large language model launched by Alibaba Cloud has been released, covering improvements in model architecture, pre-training, post-training, evaluation, and more. Today, we will provide a simple interpretation.
1. Core Insights
1.1. Model Improvements
● Architecture and Tokenizer: The Qwen2.5 series includes dense models and MoE models, utilizing a Transformer-based decoder architecture and incorporating various optimization techniques. The tokenizer uses Qwen’s tokenizer, expanding the control token set and enhancing consistency.
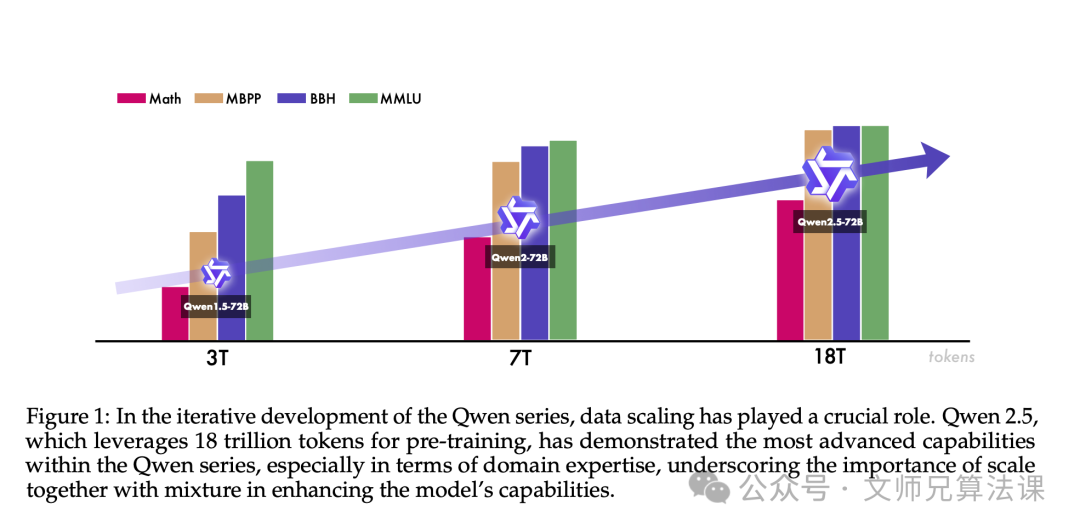
● Pre-training Data: The pre-training data has been increased from 70 trillion to 180 trillion, optimizing data filtering, increasing mathematical and code data, synthesizing high-quality data, and improving data mixing.
● Hyperparameter Scaling Rules: Hyperparameter scaling rules were developed based on pre-training data to determine optimal training parameters for different model architectures.
● Long Text Pre-training: A two-stage pre-training method is adopted, extending context length to 32,768 for all models except Qwen2.5-Turbo, which uses a progressive training strategy to extend context length to 262,144.
● Post-training Optimization: Post-training includes supervised fine-tuning (SFT) and reinforcement learning (RL). SFT utilizes a large amount of high-quality data covering multiple domains; RL is divided into offline and online phases, with offline RL focusing on complex skill training and online RL enhancing output quality through a reward model.
1.2. Model Evaluation
● Benchmark Testing: The pre-trained base model and the post-trained instruction-tuned model undergo multi-dimensional evaluation across natural language understanding, coding, mathematics, reasoning, and multilingual capabilities.
● Internal Automated Evaluation: The model’s performance in knowledge understanding, text generation, coding, etc., is evaluated using internal datasets, including English and Chinese assessments and multilingual capability evaluations.
● Reward Model Evaluation: The reward model of the Qwen2.5 series is evaluated separately using multiple benchmark tests, revealing limitations in current reward model evaluation methods.
● Long Text Processing Ability Evaluation: The model’s long text processing ability is evaluated using benchmarks such as RULER, LV-Eval, and Longbench-Chat, with Qwen2.5 showing excellent performance in long text processing, achieving 100% accuracy in a 1M token password retrieval task with Qwen2.5-Turbo.
2. Model Architecture
2.1. Architecture
● The Qwen2.5 series includes dense models for open-source (e.g., Qwen2.5-0.5B/1.5B/3B/7B/14B/32B/72B) and MoE models for API services (e.g., Qwen2.5-Turbo and Qwen2.5-Plus).
● Dense models adopt a Transformer-based decoder architecture, incorporating technologies such as Grouped Query Attention (GQA), SwiGLU activation function, Rotary Positional Embeddings (RoPE), QKV bias, and RMSNorm.
● MoE models replace standard feed-forward network (FFN) layers with specialized MoE layers, achieving expert segmentation and shared expert routing, enhancing model performance.
2.2. Tokenizer
● Utilizes Qwen’s tokenizer to implement byte-level byte pair encoding (BBPE), with a vocabulary of 151,643 regular tokens.
● Control tokens are expanded from 3 to 22, with new tokens added for tool functionalities, enhancing model capabilities and consistency.
3. Pre-training
3.1. Data Preparation
● Data Filtering: The Qwen2-Instruct model is used as a data quality filter, improving data quality through multi-dimensional analysis of training samples, refining previous filtering methods.
● Mathematical and Code Data: Integrates training data from Qwen2.5-Math and Qwen2.5-Coder, enhancing the model’s capabilities in mathematical reasoning and code generation.
● Synthetic Data: High-quality synthetic data is generated using Qwen2-72B-Instruct and Qwen2-Math-72B-Instruct, strictly filtered through proprietary reward models and the Qwen2-Math-RM-72B model.
● Data Mixing: Uses the Qwen2-Instruct model to classify and balance content from different domains, optimizing data distribution and improving training dataset quality.
3.2. Hyperparameter Optimization
● Hyperparameter scaling rules are developed based on Qwen2.5 pre-training data to determine optimal training parameters (e.g., batch size B and learning rate μ) for different scale models (including dense and MoE models).
● Experimental research investigates the relationship between model architecture and optimal training hyperparameters, including variations in learning rate and batch size with model size and pre-training data size.
3.3. Long Context Pre-training
● Except for Qwen2.5-Turbo, other models extend context length from 4,096 to 32,768 during the later stages of pre-training, simultaneously increasing RoPE’s base frequency; Qwen2.5-Turbo adopts a progressive context length extension strategy, ultimately reaching 262,144.
● To enhance the model’s ability to handle long sequences, YARN and Dual Chunk Attention (DCA) techniques are employed during the inference phase, significantly improving sequence length handling capabilities and model performance.
4. Post-training
4.1. Supervised Fine-tuning (SFT)
● Data Coverage Expansion: Utilizing a dataset of over 1 million high-quality examples for SFT, covering key areas such as long text generation, mathematics, coding, instruction following, structured data understanding, logical reasoning, cross-language transfer, and system instructions.
● Multi-domain Data Augmentation: Specific data processing and generation methods are applied for different domain data, such as long text generation, mathematics, coding, etc., improving data quality and model capabilities.
● Training Parameter Settings: The model undergoes two-stage fine-tuning on sequences of 32,768 tokens, gradually reducing the learning rate and applying weight decay and gradient clipping to optimize learning and prevent overfitting.
4.2. Offline Reinforcement Learning (Offline RL)
● Advantages and Application Areas: Suitable for tasks where standard answers exist but are difficult to evaluate through reward models, such as mathematics, coding, instruction following, and logical reasoning.
● Data Generation and Utilization: New queries are resampled using the SFT model, with quality-checked responses serving as positive or negative examples for DPO training, while combining manual and automated review processes to ensure data quality.
● Training Settings: Single-stage training is conducted using the Online Merging Optimizer, with a learning rate of 7×10⁻⁷.
4.3. Online Reinforcement Learning (Online RL)
● Reward Model Construction: A reward model is constructed based on strict labeling criteria (including authenticity, usefulness, conciseness, relevance, harmlessness, and debiasing) to ensure model outputs meet high-quality and ethical standards.
● Data Sources and Processing: Training data comes from open-source and proprietary datasets, with responses generated from different checkpoints of the Qwen model sampled through various temperature settings, creating preference pairs through manual and automated labeling, and integrating DPO training data.
● Training Strategy: Group Relative Policy Optimization (GRPO) is used to determine the query processing order based on the variance of response scores evaluated by the reward model, sampling 8 responses for each query and training using global batch size and samples.
4.4. Long Context Fine-tuning
● To enhance Qwen2.5-Turbo’s performance on long queries, a two-stage approach is adopted during the SFT phase, first using short instruction fine-tuning, then combining short and long instruction fine-tuning, effectively improving instruction-following capabilities in long context tasks.
● The RL phase focuses on short instruction training, which aligns the model with human preferences while avoiding the high-cost training of long context tasks under limited computational resources.
5. Model Evaluation
5.1. Benchmark Testing
● Base Model Evaluation: The base models of the Qwen2.5 series are comprehensively evaluated in natural language understanding, general question answering, coding, mathematics, scientific knowledge, reasoning, and multilingual capabilities, using multiple datasets (e.g., MMLU, BBH, ARC-C, TruthfulQA, Winogrande, HellaSwag, etc.), demonstrating the performance advantages of Qwen2.5 models across different tasks and scales compared to other leading models.
● Instruction-tuned Model Evaluation: Instruction-tuned models are evaluated in natural language understanding, coding, mathematics, reasoning, etc., using multiple datasets (e.g., MMLU-Pro, MMLU-redux, LiveBench 0831, GPQA, GSM8K, MATH, HumanEval, MBPP, MultiPL-E, LiveCodeBench, IFEval, Arena-Hard, MTbench, etc.), showing excellent performance in multiple benchmark tests compared to other leading models.
5.2. Internal Automated Evaluation
● English and Chinese Evaluation: The model’s performance in knowledge understanding, text generation, coding, etc., is evaluated using internally developed datasets, comparing the Qwen2.5-Instruct model with other leading models (e.g., GPT-4, Claude3.5-sonnet, Qwen2, Llama-3.1, etc.) in English and Chinese, analyzing the impact of model size on performance, and demonstrating the optimizations and improvements of the Qwen2.5 series models across different scales.
● Multilingual Capability Evaluation: The instruction-tuned model’s multilingual capabilities are evaluated by expanding multiple benchmark tests (e.g., IFEval, Knowledge Utilization, MGSM8K, BLEnD, etc.), with the Qwen2.5 model showing competitive performance in multilingual tasks, performing well in instruction following, multilingual knowledge, and mathematical reasoning, but still having room for improvement in capturing cultural nuances.
5.3. Reward Model Evaluation
● The reward models of the Qwen2.5 series are evaluated using multiple benchmark tests (e.g., Reward Bench, RMB, PPE, Human-Preference-Chinese, etc.), comparing with other baseline models (e.g., Nemotron-4-340B-Reward, Llama-3.1-Nemotron-70B-Reward, Athene-RM-70B, etc.), revealing limitations in current reward model evaluation methods, where excessive optimization on a single benchmark may lead to performance degradation in other benchmarks, and the evaluation scores do not fully correlate with the downstream performance of RL models.
5.4. Long Text Processing Ability Evaluation
● The long text processing ability of the models is evaluated using benchmarks such as RULER, LV-Eval, and Longbench-Chat, with the Qwen2.5 model demonstrating excellent performance in long text processing, especially Qwen2.5-72B-Instruct performing strongest across all context lengths, and Qwen2.5-Turbo achieving 100% accuracy in a 1M token password retrieval task.
● By introducing sparse attention mechanisms, Qwen2.5-Turbo significantly improves inference speed in processing long contexts, reducing computational load and enhancing user experience.