

Application of Large-Scale Pre-trained Models in Quantitative Investment (Part 1)
Research Unit: Taiping Asset Management Co., Ltd.
Project Leader: Wang Zhenzhou
Project Team Members: Wang Teng, Yi Chao, Zuo Wenting, Hu Qiang, Yu Hui
Abstract:
This project deeply explores the application of large-scale pre-trained models in the field of quantitative investment, mainly addressing several key issues in quantitative investment, including how to effectively process unstructured data, how to accurately capture market sentiment, how to discover and utilize nonlinear relationships in the market, and how to quickly adapt to market changes.
The innovations of the project are reflected in the following aspects:
(1) API Calling and Text Analysis: By applying the GPT-API, the project proposes a new method for text analysis and information extraction, capable of deeply analyzing financial news and social media content to extract valuable information for investment decisions.
(2) Model Fine-tuning Techniques: The project studies the techniques for fine-tuning large-scale pre-trained models, including supervised fine-tuning and parameter-efficient fine-tuning methods such as P-tuning v2 and LoRA. These techniques enable the model to better adapt to specific tasks in the financial field, enhancing the model’s performance.
(3) Building Knowledge Bases with Langchain: Through Langchain technology, the project achieves the integration of large-scale pre-trained models with localized knowledge bases, expanding the knowledge range of the model and improving its application effectiveness in the financial sector.
(4) Application of Transformer Architecture: The project draws on the Transformer architecture from natural language processing and modifies it to meet the needs of quantitative investment. Through attention mechanisms, Transformer models can capture complex relationships in the financial market, improving prediction accuracy.
(5) AI Code Generation Technology: The project explores the application of AI code generation technology in quantitative investment, including automated web scraping code generation, sentiment analysis, and trading strategy optimization, providing new tools and methods for quantitative investment.
The introduction of these innovative models and methods brings the following breakthroughs to the fintech sector:
(1) Improved the efficiency and market adaptability of developing quantitative investment strategies.
(2) Enhanced the depth and breadth of text analysis, providing more precise text analysis metrics for investment decisions.
(3) Through the Transformer architecture, improved the ability of quantitative models to handle time series data, enhancing the model’s predictive accuracy.
(4) The application of AI code generation technology provides new solutions for the automation and intelligentization of quantitative investment.
The research results of the project have profound implications and significance:
(1) Provides a new perspective by applying advanced technologies from the field of natural language processing to quantitative investment, broadening the research and application scope of quantitative investment.
(2) Empirical cases validate the effectiveness of large-scale pre-trained models in quantitative investment, enhancing the confidence and interest of academia and industry in this direction.
(3) Promotes technological advancement in the fintech sector, stimulating more research and exploration on the application of big data and artificial intelligence in finance.
Overall, the research results of this project are not only innovative academically but also highly valuable in practical applications, positively promoting the development of the fintech sector.
Keywords: Large Language Model, Pre-training, Quantitative Investment, Application Scenarios
Chapter 1 Introduction
Section 1 Research Background
In recent years, Natural Language Processing (NLP) has become a popular branch in the fields of computer science and artificial intelligence, aiming to enable machines to understand human language. On November 30, 2022, OpenAI released ChatGPT, a chatbot program. Within about two months of its launch, the number of active users reached 100 million. Clearly, ChatGPT has become a representative of the new generation of chatbots, poised to bring significant changes to the information industry. In addition to demonstrating basic capabilities such as chatting, poetry writing, translation, and creation, ChatGPT also exhibits impressive performance in code writing, instruction understanding, multi-turn dialogue, and general abilities, even passing some high-difficulty professional tests. As a product of large-scale pre-trained models, ChatGPT has a thinking mode closer to that of the human brain, capable of demonstrating the ability to solve various general problems across multiple domains, providing greater imaginative space for AI + industries.
Quantitative investment is an investment method that systematically models and analyzes financial markets using mathematical and statistical methods, generating trading strategies based on models. Large-scale pre-trained models, as models with powerful semantic understanding capabilities trained on massive datasets, such as GPT and BERT, can learn rich feature representations from unstructured data, providing new possibilities for quantitative investment. The introduction of large-scale pre-trained models in the field of quantitative investment offers new ideas and methods for investment decision-making. Scholars at home and abroad have conducted extensive research on the application of large-scale pre-trained models in quantitative investment, proposing various quantitative investment strategies based on pre-trained models, achieving good results in empirical studies.
Regarding the development paths of large-scale pre-trained models, existing research begins by analyzing the technology of natural language processing and discusses the characteristics and advantages of different development paths. In terms of model research on large-scale pre-trained models, various research directions exist for different types of models, and large-scale pre-trained models for Chinese are also flourishing. However, research on the application of large-scale pre-trained models in quantitative investment is relatively scarce, mainly including: Muhammad T, Aftab A B, Ahsan M, etc. (2022) introduced the Transformer model to predict future prices of stocks on the Dhaka Stock Exchange (DSE); Boyle D, Kalita J, etc. (2023) proposed a new method STST using spatio-temporal Transformer-LSTM models for stock trend prediction, incorporating factors affecting stock prices, including but not limited to financial statements, social and news sentiment, overall market sentiment, political events, and trading psychology into the quantitative scope; Zhang Haoru (2021) combined natural language processing technology with ESG performance evaluation, expanding the scope of examination based on the ESG guidelines of the Hong Kong Stock Exchange and constructing an ESG performance evaluation system; Sun Fuxiong, etc. (2022) learned the common characteristics of stock suspensions of A-share listed companies through pre-trained models, then obtained the characteristics of individual stock suspensions through transfer learning of pre-trained model parameters, and constructed a specific stock suspension prediction model; Chen Tianzeng, etc. (2021) effectively addressed the issue of insufficient input text information through two strategies and further introduced pre-trained models BERT and GPT-2 to solve the challenges of generating long texts in the financial field, such as writing macro research reports and event commentary reports.
This article first organizes the development path of large-scale pre-trained models, discusses the current status of existing large-scale pre-trained models, and points out the importance and necessity of researching large-scale pre-trained models in the field of quantitative investment; then, starting from the model level, analyzes the research content of relevant algorithm technologies involved in large-scale pre-trained models, studying the technical difficulties of large-scale pre-trained models; based on the insights gained from the existing applications of large-scale pre-trained models, analyzes case implementations and future application scenarios in the field of quantitative investment; finally, combined with specific business content, proposes several application scenarios and technical implementations for enhancing quantitative investment using large-scale pre-trained models, including: (1) Factor generation and text processing: using large-scale pre-trained models for individual stock sentiment analysis; (2) Fine-tuning NLP tasks: extracting text and constructing graphs after fine-tuning the model through p-tuning; (3) Financial news tracking: conducting real-time financial analysis and tracking in conjunction with Langchain; (4) Application of underlying models: using Transformer underlying networks for stock time series prediction; (5) Quantitative code generation: utilizing large language models for code writing and other application cases.
Section 2 Research Significance
Researching the application of large-scale pre-trained models in quantitative investment has multiple significances, specifically including:
(1) Helping to provide more accurate predictions: Large-scale pre-trained models possess the ability to process vast amounts of data and learn complex patterns. By applying these models in quantitative investment, more accurate market predictions and price trend analyses can be obtained. This assists investors in making more informed investment decisions, improving investment returns.
(2) Discovering nonlinear relationships: Traditional quantitative investment models usually model based on linear relationship assumptions. However, there exist numerous nonlinear relationships in the market. Large-scale pre-trained models can discover these nonlinear relationships by learning and mining large datasets, providing more comprehensive market insights.
(3) Handling complex data: Financial market data is diverse, including structured data (such as prices and trading volumes) and unstructured data (such as news reports and social media sentiment). Large-scale pre-trained models can effectively handle this complex data and extract valuable information from it. By comprehensively considering various data sources, a more holistic assessment of market risks and opportunities can be achieved.
(4) Reducing human bias: Human investors may be influenced by emotions, personal preferences, and cognitive limitations when making decisions. Large-scale pre-trained models are not affected by these biases when analyzing market data, providing objective market analysis and predictions. This helps to reduce subjectivity in investment decisions and improve the overall effectiveness of investment portfolios.
(5) Rapidly adapting to market changes: Financial markets are characterized by high dynamism and uncertainty. Large-scale pre-trained models can better capture market changes and trends through rapid learning and adaptation to new data. This allows investors to adjust their investment strategies in a timely manner, better adapting to changes in the market environment.
In summary, researching the application of large-scale pre-trained models in quantitative investment is significant for improving prediction accuracy, discovering nonlinear relationships, handling complex data, reducing human bias, and rapidly adapting to market changes. This will provide investors with better decision support, improve investment returns, and gain a competitive advantage in uncertain financial markets.
Section 3 Research Objectives
This article aims to explore the application scenarios and cases of large-scale pre-trained models in quantitative investment by studying the development paths and model research of large-scale pre-trained models at the technical level, further integrating the practical needs of the quantitative investment field, revealing the modes in which large-scale pre-trained models empower quantitative investment, and striving to use large-scale pre-trained models to enhance prediction accuracy, discover nonlinear relationships, handle complex data, reduce human bias, and rapidly adapt to market changes in quantitative investment.
Chapter 2 Natural Language Processing and Large Language Models
Section 1 Overview of Natural Language Processing Research
Natural language processing pre-training technology is the first part of natural language processing. It converts human-recognized language into machine-recognized language, thereby improving model performance. Based on whether neural networks are used for pre-training, pre-training techniques can be divided into traditional pre-training techniques and neural network pre-training techniques. Specifically, pre-processing involves cleaning the raw corpus (including removing whitespace, invalid tags, symbols, stop words, document segmentation, basic error correction, encoding conversion, etc.), tokenization (for Chinese, this applies to independent words), and standardization, transforming the corpus into a machine-readable language.
1. Traditional Pre-training Techniques
Traditional pre-training techniques include: N-gram technology, vector space model technology, Textrank technology, semantic analysis, and other pre-training techniques.
N-gram is a commonly used technique in natural language processing (NLP) and text mining, used to represent sequences of continuous words in text or speech data. Specifically, an N-gram is a sequence composed of N consecutive words or characters, widely applied in various NLP tasks. Its most common use is in statistical language models to predict the probability of the next word. By statistically estimating the frequency of various N-grams appearing in a large amount of text data, the probability of a word appearing in the context of the previous N-1 words can be estimated. Additionally, N-gram is often used for text similarity computation, text classification, spell checking, and other tasks. Although N-gram is a relatively simple technique, it has some limitations. Firstly, it cannot capture long-distance dependencies in sentences well, as it only considers fixed-size windows. Secondly, as N increases, the number of possible N-gram combinations grows exponentially, leading to data sparsity issues.
Table 2-1 Summary of Traditional Pre-training Techniques
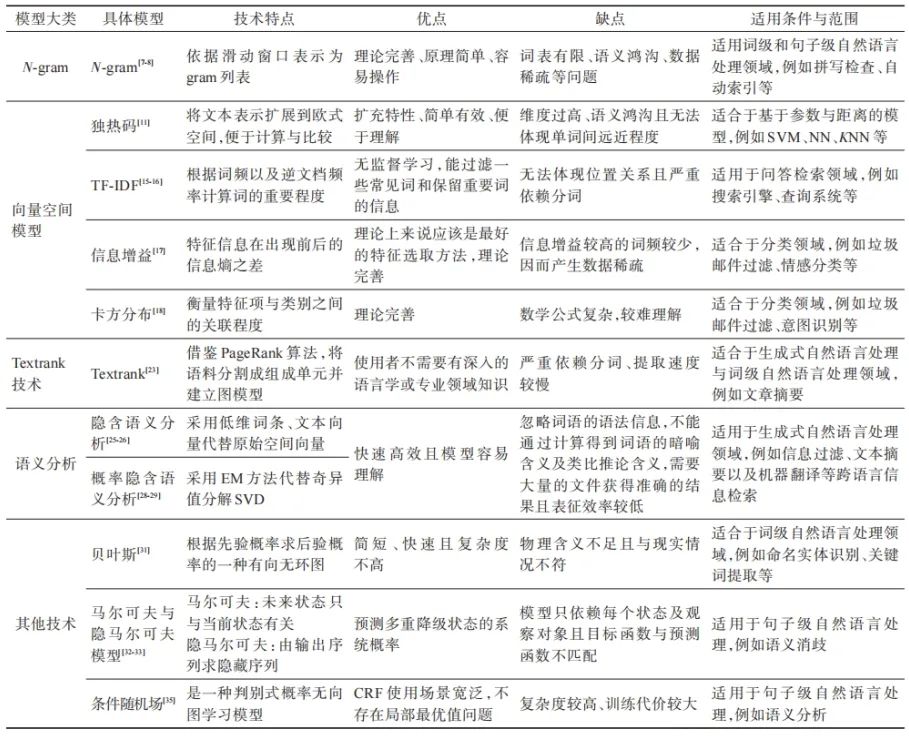
Source: Chen Deguang, Ma Jinlin, Ma Ziping, et al. Overview of Natural Language Processing Pre-training Technology
The vector space model (VSM) is a commonly used technique in information retrieval and natural language processing, used to represent text data as vectors in high-dimensional space. In VSM, text (such as documents or queries) is represented as a vector, with dimensions corresponding to unique vocabulary in the corpus, and the weight of each dimension typically represents the importance or frequency of that word in the text. A core idea of VSM is that semantically similar texts should be close in vector space. Based on this assumption, VSM is widely used for document similarity computation and relevance ranking, particularly in traditional information retrieval systems. Common similarity measures include cosine similarity, which calculates the cosine value of the angle between two vectors. To enhance the model’s representational power and address the word frequency skew issue, the TF-IDF (Term Frequency-Inverse Document Frequency) weighting method is introduced in VSM. TF-IDF considers the frequency of a word in a document (TF) and the inverse document frequency of that word across the entire corpus (IDF). In this way, words that frequently appear in a specific document but are rare in the entire corpus receive higher weights. Although VSM has achieved success in numerous applications, it also has significant limitations, such as the inability to capture word order and semantic relationships.
TextRank is a graph-based ranking algorithm used for natural language processing and text processing tasks, especially suitable for keyword extraction and document summarization. This method was initially developed inspired by Google’s PageRank algorithm. In the TextRank model, units in the text (such as sentences or words) are treated as vertices in a graph, and their similarities or associations establish edge connections. In practice, a graph is constructed based on certain criteria (such as word co-occurrence or semantic similarity), where nodes can be sentences or vocabulary, and edges represent their relationships or similarities. The algorithm then iteratively runs on this graph until a stable score distribution is reached, which is used to rank the nodes. In keyword extraction, words or phrases serve as nodes of the graph, while their co-occurrence relationships in the text form edges. For document summarization, each sentence is treated as a node, and the similarity between sentences establishes edges between them. Notably, TextRank is unsupervised, meaning it does not require pre-labeled training data. This significantly increases its applicability across different fields and languages. Despite providing a concise and effective approach that performs well in many tasks, complex document structures and content may still require the combination of other techniques or algorithms to achieve better results.
Semantic analysis, often referred to as semantic understanding, is a core task in natural language processing (NLP) aimed at understanding and extracting meanings from text. Unlike lexical and syntactic analysis, which focus on word recognition and their structure in sentences, semantic analysis aims to reveal the deeper meanings behind texts. Its main challenges lie in the ambiguity and polysemy of language, as well as complex contextual relationships. The applications of semantic analysis are broad, including but not limited to sentiment analysis, machine translation, question answering systems, and knowledge graph construction. To accomplish these tasks, researchers employ a range of techniques, from traditional rule-based and template-based methods to recent deep learning-based models. In particular, with the popularity of word embeddings and Transformer architectures, significant progress has been made in learning and understanding semantic representations. However, despite many breakthroughs, fully understanding the complexity and richness of natural language remains a long-term pursuit in the NLP field, continuously inspiring new research directions and technological innovations.
These four traditional pre-training techniques have low coupling with models, and there are also some traditional pre-training techniques with high coupling to models. For example, Bayesian classification technology (BC) based on prior probabilities to seek posterior probabilities, Markov models (MM) with multiple degrading states, and hidden Markov models (HMM), and undirected graphical random fields (RF) with discriminative probabilities.
In summary, traditional pre-training techniques have been summarized and organized. The summary of traditional pre-training techniques is shown in Table 2-1. However, traditional pre-training techniques struggle to solve many issues, leading to the introduction of neural network pre-training techniques.
2. Neural Network Pre-training Techniques
To address the shortcomings of traditional natural language pre-training techniques, neural network natural language pre-training techniques have adopted improvements, mainly considering the contextual relationships between words in the actual corpus. Although there have been numerous reviews in this area both domestically and internationally, many focus on neural networks and are overly simplistic. Based on this, this article presents neural network pre-training techniques through the context of fixed word representation and dynamic word representation.
Fixed word representation involves considering the context-related words of the target word, effectively addressing issues of isolated and incoherent word forms. Common fixed word representations include neural network language model techniques (NNLM), C&W (Collobert and Weston), Word2Vec (word to vector), FastText, and GloVe (global vectors for word representation).
The Neural Language Model (NLM) has become a mainstream technique in the field of natural language processing (NLP), especially against the backdrop of abundant text data and significant enhancements in computational power. Unlike traditional n-gram-based statistical language models, neural language models utilize distributed word embeddings to represent vocabulary and leverage deep neural networks to capture long-distance dependencies in word sequences. The core contribution of NLM is its ability to learn a continuous word vector space where semantically similar words are close to each other. These word vectors can provide rich features for various NLP tasks. Furthermore, NLMs based on Transformer architecture, such as BERT and GPT, have proven effective in capturing complex patterns in text and have set new performance benchmarks for many NLP tasks (such as machine translation, question answering, and text classification). Additionally, the pre-training and fine-tuning strategy has further propelled NLM’s widespread use in NLP applications. First, the model undergoes pre-training on a large amount of unlabeled text to learn general patterns of language; subsequently, it can be fine-tuned on labeled data for specific tasks, optimizing it for particular applications. Despite the tremendous success of NLM, computational demands, interpretability issues, and applications in low-resource languages remain hot topics of research.
Collobert and Weston proposed an advanced neural network model in 2008, known as the C&W model, designed specifically for word representation learning in natural language processing (NLP). Unlike mainstream methods at the time, the C&W technique does not rely on complex feature engineering but instead employs a simple neural network structure to learn distributed representations of words directly from large-scale unlabeled text. The C&W model uses a window-based architecture where the center word is predicted based on its context (other words within the window). The key innovation of this method lies in using a neural network to minimize prediction errors, thereby learning word vectors. These word vectors aim to capture semantic and syntactic information, ensuring that semantically similar words are close in vector space. The introduction of this model marked a transition from traditional sparse, high-dimensional, handcrafted-feature-based NLP methods to distributed, low-dimensional, automatically learned word vector representations. Subsequently, this method laid the groundwork for other key technologies such as Word2Vec and GloVe, which further advanced and popularized word embedding techniques.
Word2Vec is a widely used word embedding method in the field of natural language processing (NLP), proposed by Mikolov et al. in 2013. It utilizes a shallow neural network model to learn vector representations of words from large-scale text data. These distributed vector representations aim to capture semantic and syntactic information, ensuring that semantically similar words have similar vectors in vector space. Word2Vec primarily provides two model architectures: the Continuous Bag of Words model (CBOW) and the Skip-Gram model. In CBOW, the model attempts to predict the center word using the context (or words in the window). Conversely, the Skip-Gram model uses the center word to predict its context. In practice, it has been shown that for smaller datasets, Skip-Gram often outperforms CBOW, while the performance of both is nearly identical in larger datasets. Notably, the success of Word2Vec lies not only in its ability to capture similarities between words but also in recognizing semantic relationships, such as “king” minus “man” plus “woman” approximating “queen.” Since its introduction, the concept of Word2Vec has broadly influenced various aspects of natural language processing and has spawned a series of subsequent word embedding techniques, such as FastText, GloVe, and models based on Transformers like BERT. These methods continue to expand and refine the ability to automatically learn meaningful word vector representations from text data.
FastText, proposed by Facebook’s AI research team in 2016, is a word embedding and text classification method. Unlike predecessor models like Word2Vec, FastText’s core innovation lies in considering subword information in addition to words when processing text. This allows the model to capture internal structural information of words, thus better handling morphologically rich languages and out-of-vocabulary words. The FastText model represents each word as the sum of vectors of its subwords. Subwords are typically character n-grams of the word, for example, the 3-grams of “apple” include “app”, “ppl”, “ple”, etc. This way, morphologically similar words, even if they have never appeared in the training data, may have similar vector representations. Additionally, FastText is designed as an efficient text classification tool. By averaging all word vectors in the text and directly applying a linear classifier on this basis, FastText achieves rapid and effective text classification. This subword approach of FastText is particularly valuable for many non-English languages, especially those with rich morphology and compound words. Due to its efficiency and robustness, FastText is widely applied in various NLP tasks, including semantic similarity computation, sentiment analysis, and text classification. The introduction of this technology not only enriches the research field of word embedding techniques but also provides new ideas and tools for handling morphological complexity.
GloVe (Global Vectors for Word Representation) is a method for generating vector representations of vocabulary, proposed by Pennington, Socher, and Manning in 2014. Unlike traditional local context window methods, GloVe learns word vectors based on global statistical information, particularly word co-occurrence statistics, in large corpora. The core idea is that semantic information of vocabulary can be extracted from co-occurrence statistics across the entire corpus. The goal of GloVe is to learn word vectors such that the dot product of two word vectors relates to their co-occurrence probabilities in the corpus. To achieve this, the model first constructs a co-occurrence matrix, where each element represents the co-occurrence counts of two words within a specific context window. Then, GloVe employs a special loss function to decompose this co-occurrence matrix to obtain compact vector representations. The GloVe model has demonstrated performance comparable to or superior to other state-of-the-art word vector methods in various evaluation tasks, particularly in word similarity and analogy tasks. Notably, the GloVe model captures not only linear semantic relationships between words but also handles large corpora well, quickly generating high-quality word embeddings. Overall, GloVe provides an effective and scalable framework for capturing the rich semantic relationships of vocabulary and has been widely applied in the field of natural language processing.

Source: https://leovan.me/cn/2020/03/pre-trained-model-for-nlp/
Figure 2-1 Different Classifications of Pre-trained Models
Dynamic word representation considers the context-related words of the target word during the pre-training phase and also considers the context of the target word when dealing with specific sentences, effectively addressing issues of isolated word forms and polysemy. Common examples include ELMo (embeddings from language models), GPT (generative pre-training), and BERT models.
ELMo (Embeddings from Language Models) is a deep contextualized word embedding method proposed by Peters et al. at the Allen Institute for Artificial Intelligence in 2018. Unlike traditional word embedding methods like Word2Vec or GloVe, which generate static vector representations for vocabulary, ELMo provides contextually dynamic word embeddings. The ELMo model is trained based on a bidirectional long short-term memory network (BiLSTM) language model, considering the preceding and following context of a word when generating its representation in a specific sentence. This deep contextualized embedding method allows the model to generate different vector representations for the same vocabulary in different contexts, capturing its multiple meanings. A core feature of this method is that ELMo provides a specific representation for downstream tasks by linearly combining hidden states from different layers of the BiLSTM. This combination method enables ELMo to customize word embeddings for various NLP tasks (such as question answering, named entity recognition, and sentiment analysis). The introduction of ELMo marks a transition in the NLP field towards contextualized word representations, paving the way for subsequent models like BERT and Transformers. Experiments have shown that integrating ELMo embeddings into various NLP tasks can significantly improve model performance, highlighting the potential of deep contextualized word embeddings in capturing the complex semantics of words.
The GPT (Generative Pre-trained Transformer) model was first introduced by OpenAI in 2018, marking a shift in the field of natural language processing towards large, deep Transformer architectures. GPT is built on the Transformer architecture, which was initially introduced by Vaswani et al. in 2017 and has proven superior in handling sequential data. The training process of GPT consists of two stages: pre-training and fine-tuning. In the pre-training stage, the model undergoes self-supervised learning on a large amount of unlabeled text, aiming to predict the next word given the context. This allows the model to learn rich language representations, including syntactic, semantic, and common sense knowledge. In the fine-tuning stage, the model is trained on specific NLP task data in a supervised manner, such as text classification, question answering, or text generation. The emergence of GPT and its subsequent versions (like GPT-2 and GPT-3) have broken performance records across multiple natural language processing tasks. Its uniqueness lies in providing a unified, highly generalized model for various tasks through the pre-training and fine-tuning strategy, compared to traditional task-specific models. Furthermore, the GPT model is particularly renowned for its text generation capabilities, capable of producing coherent, natural, and high-quality text, which to some extent reflects the model’s deep understanding of language. Overall, GPT and its subsequent versions provide new ideas and methods for NLP research and applications, leading a wave of research trends based on large Transformer models.
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained deep learning model proposed by the Google AI team in 2018. Its core innovation lies in utilizing the Transformer architecture for bidirectional contextual word representation learning, enabling BERT to capture deeper contextual information in texts compared to previous unidirectional or shallow bidirectional models. The training process of the BERT model includes two main tasks: masked language modeling (Masked Language Model) and next sentence prediction (Next Sentence Prediction). In the masked language modeling task, BERT randomly masks certain words in the corpus and attempts to accurately predict these masked words, thereby learning the contextual representation of words in the sentence. The next sentence prediction task allows the model to learn how to understand the relationships between sentences. After pre-training, BERT can quickly adapt to various NLP tasks through fine-tuning on labeled data for specific tasks, such as text classification, named entity recognition, question answering, and semantic similarity judgment. Importantly, BERT has achieved state-of-the-art performance on multiple mainstream NLP benchmark tests. The emergence of BERT marks a significant turning point in the NLP field, laying the foundation for subsequent bidirectional pre-trained models such as RoBERTa and ALBERT. Its deep, bidirectional characteristics and pre-training-fine-tuning strategy provide new directions for understanding complex language structures and capturing contextual semantic information.
Progress in natural language processing can be demonstrated at three levels: vocabulary, sentences, and discourse. Specific application areas include named entity recognition, intelligent question answering, machine translation, text generation, and multimodal fields.
Among these, named entity recognition (NER) was first proposed at the MUC-6 conference in 1996. It is a cornerstone of the natural language processing field. Intelligent question answering (QA) is an advanced form of information retrieval, which can fulfill users’ information retrieval needs through dialogue. Currently, ChatGPT is a typical representative of this. Machine translation (MT), also known as automatic translation, has developed in parallel with natural language processing, driven by human needs to convert different languages, propelling the development of natural language processing. Text classification (TC) relies on natural language processing, data mining, and pattern recognition techniques to classify different texts. Its application scenarios are very broad, such as spam detection, etc. Text generation (TG) mainly includes automatic summarization, information extraction, and machine translation. Similarly, ChatGPT is also a typical representative of text generation. In addition to the above application areas, the multimodal field is also a significant application area for natural language processing. The types of data generated in human daily life include videos, images, etc. Therefore, this naturally leads to multimodal data.
Section 2 Overview of Large-Scale Pre-trained Models
1. Current Status of Large Models
In recent years, large language models (LLMs) have achieved breakthrough progress in the field of artificial intelligence, leading to rapid development in technology and applications. On November 30, 2022, OpenAI released ChatGPT, an impressive general conversational AI tool. Its powerful language processing capabilities attracted over 100 million active users within just two months of its launch, making it one of the fastest-growing consumer applications in history.
As time progresses, LLMs continue to innovate. On March 15, 2023, OpenAI launched GPT-4, a multimodal pre-trained large language model capable of simultaneously processing image and text inputs, demonstrating improvements in multiple aspects. Subsequently, the enterprise-level Azure OpenAI GPT-4 service was also released. Meanwhile, Google’s Bard project, based on the PaLM 2 model, focuses on human-computer collaborative efforts, showcasing its pursuit of advancements in LLM technology. Meta released Llama 2, significantly impacting the open-source large model field with its three parameter scale variants, demonstrating excellent performance in multiple external benchmark tests.
In the financial sector, the application of large models has also made significant breakthroughs. BloombergGPT has become the first publicly released large language model in the financial sector, built on the BLOOM model and combining general capabilities with specific domain methods, leveraging Bloomberg’s 40 years of data accumulation to bring new perspectives and methods to financial natural language processing technology. Du Xiaoman launched the “Xuanyuan”, a trillion-level Chinese financial large model, demonstrating significant advantages in financial tasks. Liu Xiao-Yang’s team open-sourced the large language model “FinGPT” in July 2023, achieving full-process automated investment research decision-making, providing more efficient and intelligent solutions for financial business.
The development of these large models at home and abroad has brought tremendous innovation and potential to the fields of finance, natural language processing, and artificial intelligence. From quantitative investment to sentiment analysis, from predicting stock trends to creating new trading signals, large models are driving the financial industry towards a smarter future.
2. Domestic and International Large Models
On November 30, 2022, OpenAI launched a conversational general artificial intelligence tool called ChatGPT. Due to its outstanding language processing capabilities, ChatGPT quickly gained popularity among users after its release. Within just two months of its launch, the number of active users surpassed 100 million, making it the fastest-growing consumer application in history, attracting widespread attention in the industry. By March 15, 2023, OpenAI further released the multimodal pre-trained large language model GPT-4, which can process both image and text inputs, achieving performance improvements in multiple aspects. Just a week later, on March 22, the enterprise-level Azure OpenAI GPT-4 (International Preview) service was also released. ChatGPT is a large-parameter pre-trained natural language generation model, where GPT stands for “Generative Pre-trained Transformer.” After training on a vast corpus from the internet, the GPT model can generate corresponding text responses based on user input, thus achieving a common chat Q&A pattern. ChatGPT was produced after multiple iterations and improvements of the GPT model. The parameter count grew from 117 million in the original model to 175 billion in GPT-3, while the training data volume increased from 5GB to 45TB. The powerful capabilities of ChatGPT stem from the accumulation of various technical models, including machine learning, neural network models, and Transformer architectures. ChatGPT, based on previous models, possesses a larger corpus, stronger computational power, more generalized pre-training, and enhanced self-learning capabilities. It also features unique characteristics such as “daring to question”, “acknowledging ignorance”, “supporting continuous multi-turn dialogue”, and “actively admitting mistakes”.
Bard is an experimental project launched by Google, with its core support coming from Google’s PaLM 2 model. The project aims to enable users to collaborate with generative AI. Since OpenAI released ChatGPT in November 2022, Google has been striving to catch up with the development of AI technology. In May 2023, at the Google I/O annual conference, Google made substantial presentations. During this two-hour keynote, Google CEO Sundar Pichai and other executives frequently mentioned “generative AI”. Although Bard’s user numbers have yet to reach the scale of ChatGPT, its recent growth momentum is evident. Google hopes to further promote Bard’s growth through continuous updates.
On July 19, Meta released Llama 2, a free and commercially usable version, significantly impacting the open-source large model field. The Llama 2 model series offers three parameter scale variants of 7 billion, 13 billion, and 70 billion. Compared to the previous generation, the training data for Llama 2 increased by 40%. In various external benchmark tests, such as reasoning, coding, proficiency, and knowledge tests, Llama 2 has demonstrated excellent performance. Although Llama 2 supports multiple languages, its corpus is predominantly English, accounting for 89.7%, while the proportion of Chinese is only 0.13%. This limitation may lead to Llama 2 struggling to achieve fluency and depth in Chinese dialogue. Notably, the day after Meta open-sourced the Llama 2 model, the open-source community launched the first downloadable and runnable open-source Chinese LLaMA2 model, named “Chinese Llama 2 7B”, introduced by a domestic AI startup LinkSoul.Al.
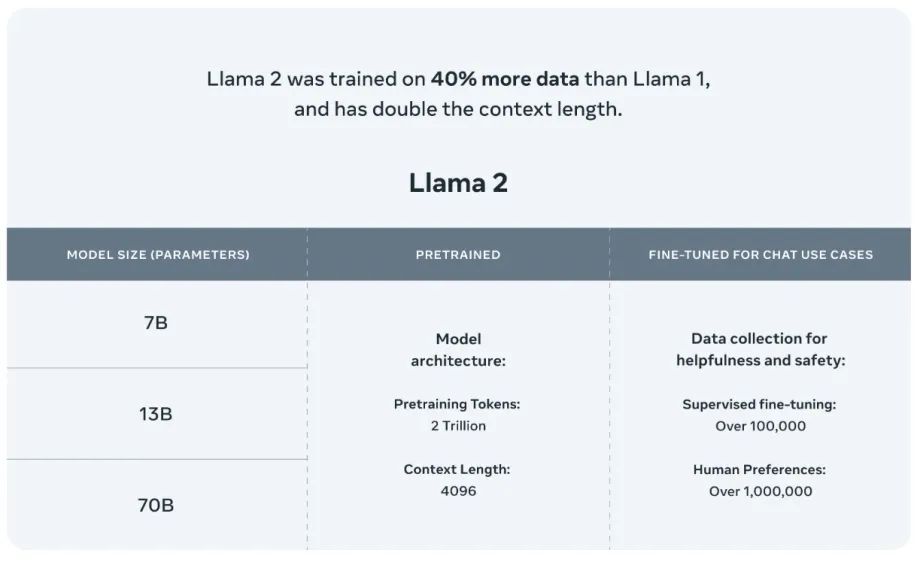
Source: Meta Official Website
Figure 2-2 Introduction to the Llama 2 Model
ChatGLM-6B and its upgraded version ChatGLM2-6B released by Tsinghua University have attracted widespread attention, surpassing 3 million since their release on March 14, 2023. Compared to the original model, ChatGLM2-6B has shown improvements in various dimensions, including mathematical logic, knowledge reasoning, and long document understanding. New features have also been introduced: more powerful performance, longer context, more efficient reasoning, and more open protocols. As a new participant, the Falcon model has emerged in the Hugging Face ecosystem. Falcon includes two foundational models: Falcon-40B and Falcon-7B, demonstrating outstanding performance and reasoning techniques. Falcon-40B performs exceptionally well in the Open LLM leaderboard, while Falcon-7B reduces memory requirements and supports efficient text generation. Furthermore, Falcon-7B has a Core ML version available on M1 MacBook Pro, providing greater flexibility.
3. Application of Large Models in Quantitative Investment
Large language models (LLMs) are experiencing unprecedented development in the financial sector. BloombergGPT is mentioned in a paper publicly released by Bloomberg on March 30, 2023, as the first publicly released large language model in the financial sector. BloombergGPT is a large language model with 50 billion parameters, built on the BLOOM model, combining general capabilities with specific domain methods. To achieve this, BloombergGPT utilizes Bloomberg’s 40 years of data accumulation to construct the largest financial dataset currently available. The research of BloombergGPT provides new perspectives and methods for natural language processing technology in the financial sector, with promising prospects for further development in the field. Du Xiaoman has launched the first domestic trillion-level Chinese financial large model “Xuanyuan”, fine-tuned based on the 176 billion parameter BLOOM model. Xuanyuan focuses on financial tasks, such as understanding financial terminology, market commentary, data analysis, and news comprehension. Xuanyuan exhibits excellent performance in financial scenarios, surpassing mainstream open-source models in the market, demonstrating strong advantages in the financial field. Through the accumulated trillion-level financial dataset and fine-tuning techniques, Xuanyuan not only performs excellently in terms of generality but also shows significant improvements in specialized tasks within the financial vertical. Liu Xiao-Yang et al. released “FinGPT: Democratizing Internet-scale Data for Financial Large Language Models” on arXiv on July 19, 2023, and open-sourced it on GitHub. This is the first open-source large language model in the financial sector, achieving fully automated decision-making from information to investment, supporting machine advisory, sentiment analysis, low-code development, and more. Based on pre-trained Transformer technology, FinGPT has achieved applications in automated investment frameworks and quantitative trading through fine-tuning to learn financial domain tasks. The application of these large language models in the financial sector provides new possibilities for automated investment research, sentiment analysis, and full-process investment decision-making, injecting new vitality into the development of the financial field. By integrating large-scale financial data with advanced natural language processing technology, these models not only enhance general performance but also excel in specialized tasks, promising to drive the financial industry towards a more intelligent and efficient direction.
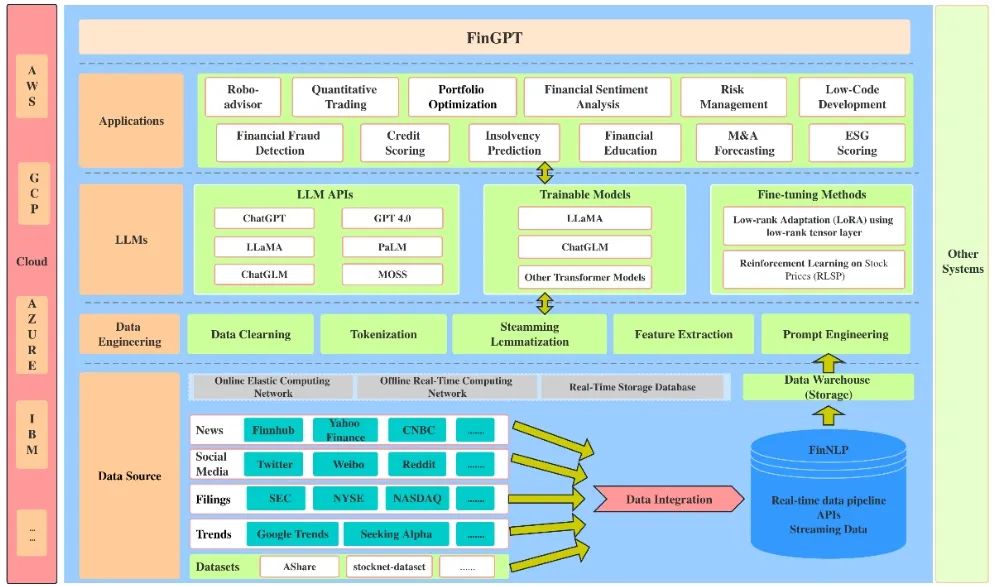
Source: GitHub
Figure 2-3 FinGPT Architecture Diagram
With the breakthrough progress of large language models (LLMs) in the field of natural language processing, their application in quantitative investment is receiving increasing attention. Zihan Chen et al. (2023) demonstrated the exceptional capabilities of ChatGPT in natural language processing tasks, particularly its potential in inferring dynamic network structures from time series text data (such as financial news). The research introduces a novel framework that combines ChatGPT’s graph inference capabilities with graph neural networks (GNN) to extract evolving network structures from text data, outperforming traditional deep learning methods and excelling in stock movement prediction and portfolio construction. Xinli Yu et al. (2023) discuss the application of LLMs in interpretable financial time series prediction. This research focuses on stocks in the Nasdaq 100 index, utilizing historical stock prices, company metadata, and economic/financial news data, demonstrating the potential of LLMs in addressing cross-sequence reasoning, multimodal signal fusion, and result interpretation. Experimental results show that LLM-based methods outperform traditional methods across multiple tasks, providing insightful support for quantitative decision-making. Saizhuo Wang et al. (2023) propose a new human-computer interactive alpha mining paradigm. Traditional alpha mining methods are limited by inherent constraints; this research innovatively combines human-computer interaction with the capabilities of large language models to mine trading signals (alpha). The Alpha-GPT system framework outputs creative, insightful, and effective alpha by understanding the thoughts of quantitative researchers, proving its advantages in improving alpha mining efficiency. Haohan Zhang et al. (2023) explore the potential of LLMs in predicting Chinese stock price trends, particularly extracting sentiment factors from news text. Through benchmarking tests, the research compares the performance of various LLM types in sentiment factor extraction and quantitative trading strategy construction, providing insights into the key factors influencing sentiment factors in LLMs. These studies enrich our understanding of the application of LLMs in quantitative finance, showcasing their potential in prediction, decision-making, and innovation. As technology continues to advance, LLMs are expected to bring more opportunities and breakthroughs to the field of quantitative investment.
— To Be Continued, Stay Tuned —

“China Insurance Asset Management” (Bimonthly)

“China Insurance Asset Management” (Bimonthly) is guided by the National Financial Supervision and Administration, founded by the China Insurance Asset Management Association, and is the only publication focused on the basic theories and business research in the field of large asset management, insurance asset management, and insurance fund utilization, holding the internal material publication approval certificate issued by the Beijing Municipal Bureau of Press and Publication.
The publication officially started in September 2015, publishing 2 issues in 2015 (quarterly), and changed to bimonthly from 2016. It has published 50 regular issues, 2 special issues, and 7 compiled volumes.
The publication includes 12 major columns: Foreword, Cover Article, Special Planning, Chief Observation, Policy Interpretation, Macro Research, Investment Trends, Business Discussion, Global Vision, Era of Big Asset Management, Light and Shadow World, Member Style.
The publication is mainly sent to regulatory agencies, association member units, relevant government departments, banks, securities firms, funds, and other financial institutions and research institutions, with increasing influence.
Contact: Research Planning Department, Teacher Yu, Teacher Li
Phone: 010-83361689 83361693
Email: [email protected]
