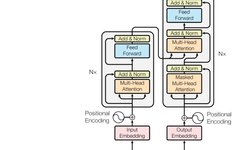
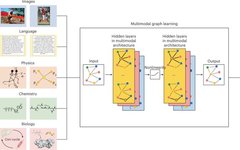
Significant Advances in Multimodal Reinforcement Learning
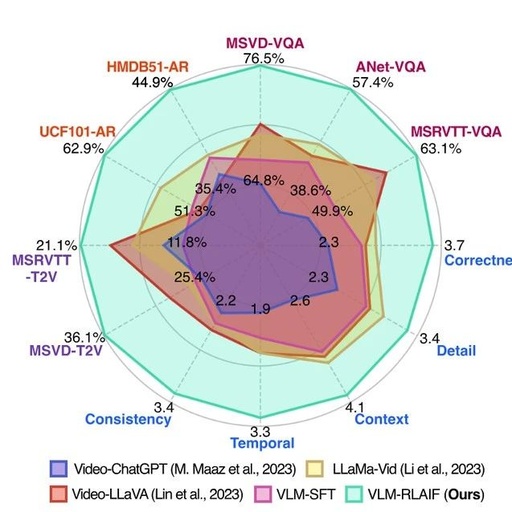
In 2024, significant progress has been made in the field of “multimodal + reinforcement learning”. Researchers have proposed various innovative methods to integrate data from different modalities to enhance the performance and applicability of reinforcement learning algorithms. For example, methods mentioned in the literature include utilizing Masked Multimodal Learning to achieve the fusion of visual … Read more