
Follow the public account “ML_NLP“

Written by | Lao Tao (Researcher from a certain company, hereditary parameter tuning)
Translated by | Beautiful person with meticulous thoughts
Introduction
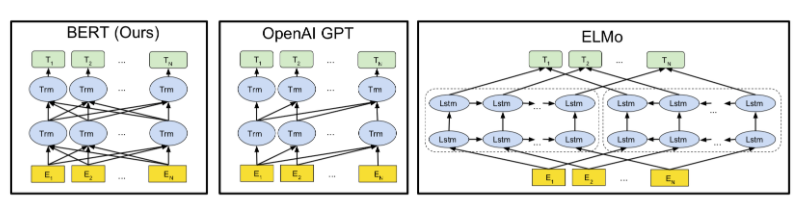
As the hottest topic in NLP over the past two years, the language pre-training technologies represented by ELMo/BERT are already familiar to everyone. Let’s briefly review several important works in pre-training since 2018:
-
ELMo first proposed the pre-training technology based on language models, successfully validating the effectiveness of self-supervised learning on large-scale corpora. -
GPT proposed that NLP pre-training technology should be fine-tuned in downstream tasks like CV pre-training technology, achieving breakthroughs on the GLUE leaderboard. -
BERT built on GPT, proposing an improved bidirectional language model learning technique called Mask Language Model. Compared to traditional language models, Mask Language Model (aka MLM) can utilize contextual information more effectively, especially in a transformer learning model that relies on a global attention representation mechanism. BERT significantly refreshed benchmark levels in the General Language Understanding Evaluation (GLUE), breaking 11 NLP records and becoming a masterpiece of the new generation of language pre-training technology.
The publication of BERT sparked great enthusiasm in the NLP academic and industrial communities for language pre-training technology, leading to a series of improvements to BERT emerging like mushrooms after rain. ERNIE (Baidu)/SpanBert improved the masking mechanism of the MLM task, UniLM jointly trained GPT/BERT to achieve unified language pre-training, and XLM extended BERT pre-training technology to multiple languages.
However, while MLM solved the problem of traditional language models being able to only see unidirectional text information, it had to introduce a significant proportion of [MASK] mask ID placeholders during the pre-training phase. This leads to information loss in language model learning (masked tokens are not visible to each other). At the same time, the sample construction method of MLM has a gap with the training samples in the fine-tuning phase, which may affect the performance in downstream tasks. To address these two issues, XLNet proposed the Permuted Language Modeling (aka PLM) pre-training task. To implement PLM, the authors proposed a dual-stream mechanism, which also inspired more applications and improvements to the dual-stream mechanism.
This article will start from XLNet’s dual-stream mechanism and take a look at some recent outstanding works, including Baidu’s ERNIE-GEN, Microsoft’s ProphetNet, UniLMv2, and MPNet.
XLNet: PLM and Dual-Stream Mechanism
PLM Task
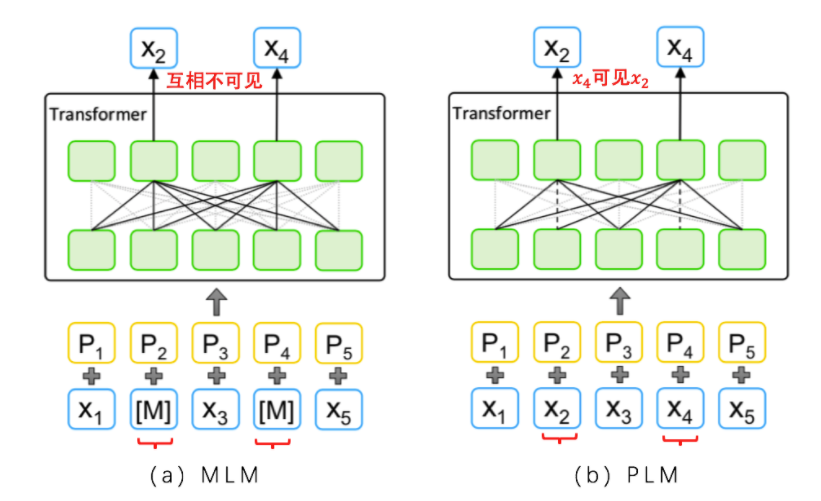
The approach of PLM is to shuffle the input order, for example, changing “Xiao Yao’s cute selling house” to “House Xiao Yao’s cute selling” for unidirectional language model training. In this way, when predicting “cute”, the information from “House Xiao Yao’s” can be used, effectively utilizing the context.
-
In terms of input, the tokens to be predicted in MLM ([M]) can only see positional information (solid line connection). In PLM, the token x_2 to be predicted cannot see the token x_4 (dashed line connection), but the token x_4 can see the token x_2 (solid line connection). -
At a 15% masking ratio, MLM retains 100% positional information and 85% token information, while PLM retains (expected) 92.5% positional information and 92.5% token information.
For PLM, given a text x = (x1,x2,··· ,xn), there are n factorial permutations. In the ideal world of PLM, although the language model can only see the unidirectional text (the preceding context) for a specific sequence of text x_i, the preceding sequence may contain all combinations of the entire text, thus PLM is capable of modeling contextual information.
We can describe MLM and PLM in a “unified view”:

XLNet proposed the dual-stream mechanism to implement PLM. It can be seen that the PLM task is learned through the Query stream.
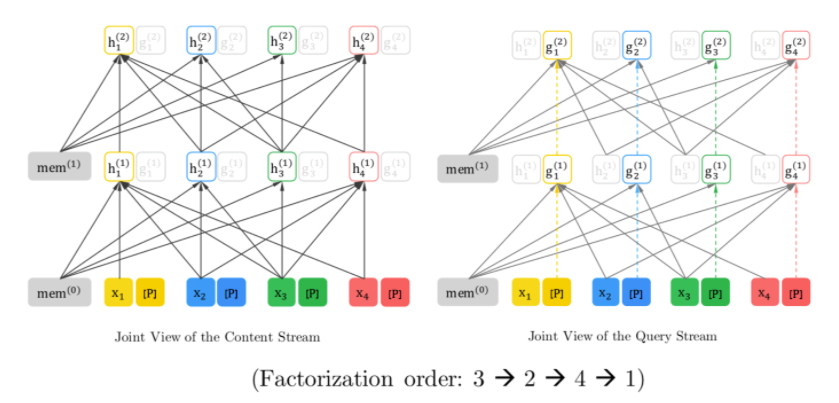
To make it easier to understand, we reorganized the dual-stream input of XLNet, supplementing the query stream input based on the PLM content stream input from the previous section.
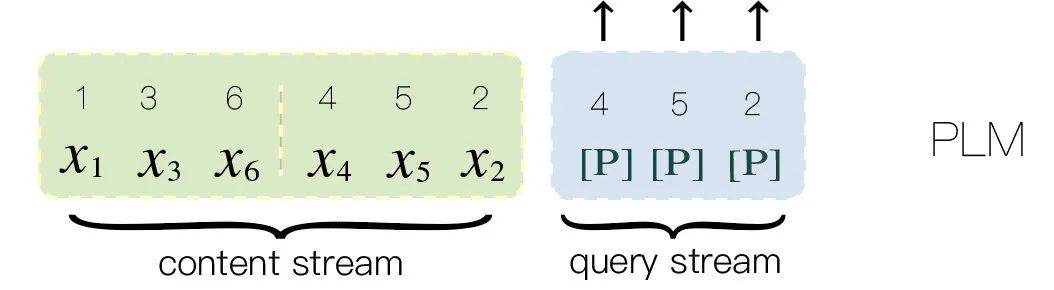
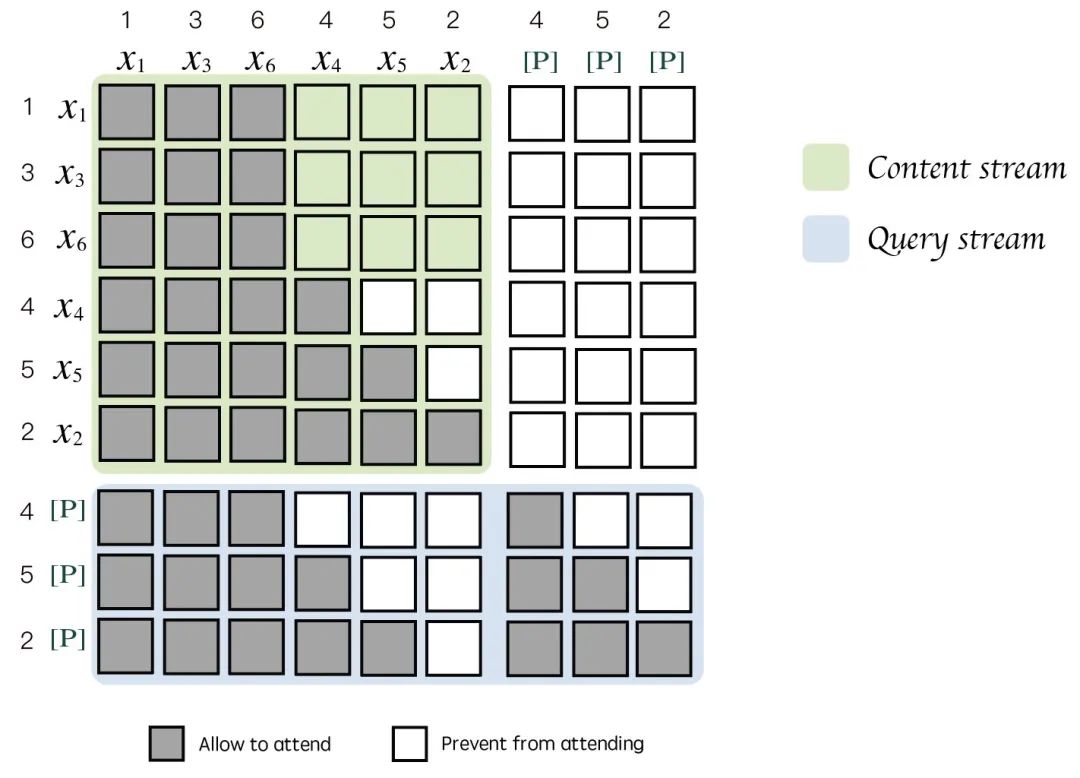
Where [P] placeholder represents the tokens to be predicted in PLM, with the prediction order being 4 -> 5 -> 2.
Below is the self-attention mask matrix corresponding to the PLM input, where the context (x_1, x_3, x_6) can be seen by all tokens in the content/query stream.
“Top-Notch” Pre-trained Models
The dual-stream mechanism defined by XLNet, where the query stream separates the “prediction task” from the input text (content stream), has strong versatility. In fact, we can define different query stream pre-training tasks, or even define multiple query streams (multi-stream). Since this year, many pre-training works based on the multi-stream mechanism have emerged, including the language generation pre-training technique ERNIE-GEN (Baidu) that refreshes multiple language generation task SOTA and the second-generation unified language pre-training technique UniLMv2 (Microsoft).
Currently, pre-training works based on the multi-stream mechanism include two major categories: language generation and language understanding.
Definition of “Top-Notch”
-
Top-notch models include 2+ pre-training task “streams”
Existing Works
-
ERNIE-GEN (Baidu): Multi-flow framework, first introduced span-by-span tasks in generation pre-training, using noise-aware mechanisms in the pre-training & fine-tuning stages to alleviate the exposure bias problem faced by seq-to-seq language generation frameworks, applied to language generation tasks (accepted by IJCAI 2020) -
ProphetNet (Microsoft): Ngram-stream framework, each stream models a particle independently, used for language generation pre-training (submitted to ICML 2020) -
UniLMv2 (Microsoft): Inherits the idea of unilm v1, replacing the original LM task with PLM. Utilizes the dual-stream mechanism to perform both MLM and PLM tasks, applied to language understanding and generation tasks (accepted by ICML 2020) -
MPNet (Microsoft): Similar to UniLMv2, provides a better theoretical explanation for why it is necessary to retain both MLM and PLM data construction methods from the perspective of “information retention”. The pre-training task only includes the PLM task, applied to language understanding tasks
Multi-stream Pre-training Technology for Language Generation
ERNIE-GEN (Baidu)
ERNIE-GEN is a language generation pre-training model proposed by Baidu researchers. ERNIE-GEN inherits the ideas of universal language understanding pre-training technology ERNIE 1.0, first introducing span-by-span generation streams in language generation pre-training, enabling the pre-training model to directly generate span-level (bigrams/trigrams) complete semantic units.
In addition to the span-by-span generation stream, ERNIE-GEN also includes a Contextual stream (modeling the preceding context of the semantic units to be generated) and a Word-by-Word generation stream. Therefore, ERNIE-GEN designed a Multi-flow Attention module for joint learning of multiple streams.

At the same time, ERNIE-GEN consciously designed filling generation (Infilling generation) and noise-aware mechanisms during the pre-training stage to alleviate the exposure bias problem faced by the Sequence-to-Sequence generation framework.
ERNIE-GEN Paper Address: https://paperswithcode.com/paper/ernie-gen-an-enhanced-multi-flow-pre-training
ERNIE-GEN Open Source Address: https://github.com/PaddlePaddle/ERNIE/tree/repro/ernie-gen
ProphetNet (Microsoft)
ProphetNet is a language generation pre-training model proposed by Microsoft researchers. Similar to ERNIE-GEN, ProphetNet also focuses on the model’s ability to model complete semantic units in language generation, proposing the N-gram stream multi-stream mechanism to address this issue.
During pre-training, ProphetNet simultaneously models multiple semantic units of different granularities. ProphetNet calls this mechanism of simultaneously modeling multiple granularities “Future N-gram Prediction”. In actual pre-training, for reasons of effect and efficiency, ProphetNet only uses 1-gram (word) and 2-gram (bigram) prediction streams.
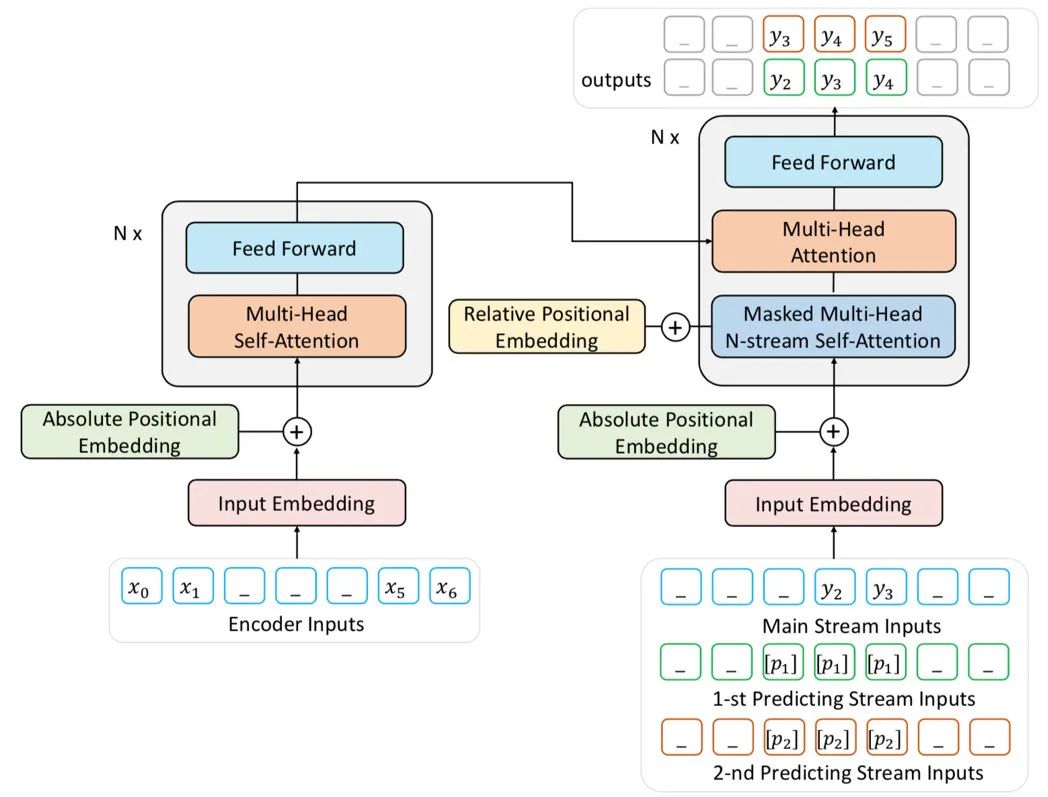
In addition, ProphetNet introduces relative position encoding embedding in pre-training, in addition to absolute encoding embedding, but the paper does not conduct relevant ablation experiments.
ProphetNet Paper Address: https://arxiv.org/abs/2001.04063
ProphetNet Open Source Address: https://github.com/microsoft/ProphetNet
Multi-stream Pre-training Technology for Language Understanding
Next, we will introduce language understanding pre-training models based on the multi-stream mechanism.
UniLMv2 (Microsoft)
UniLMv2 is the second-generation unified language pre-training model proposed by Microsoft researchers. Compared to UniLM v1, v2 retains the MLM task of v1, but replaces the traditional language model task with the PLM task.
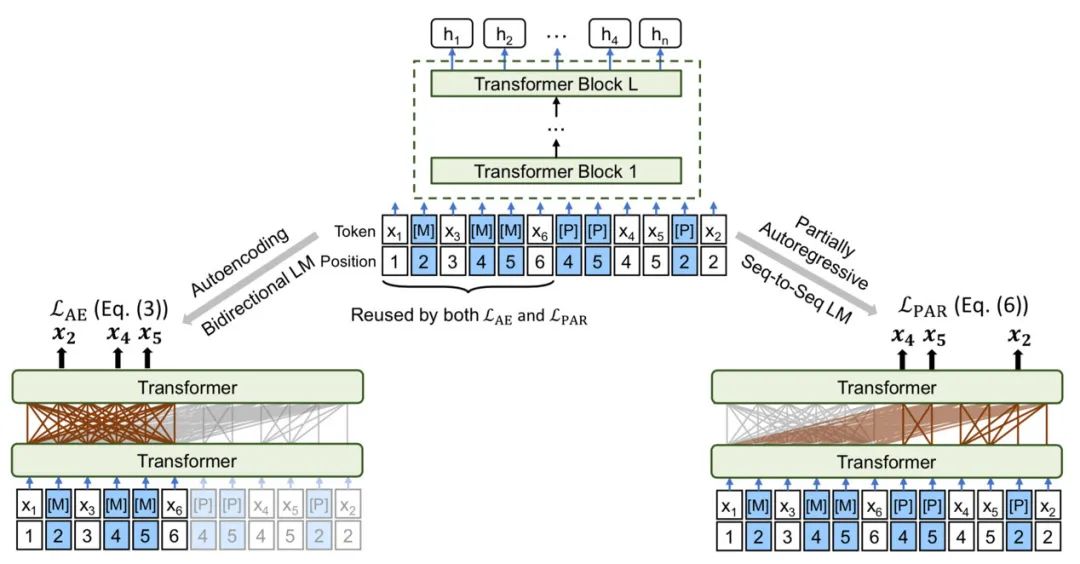
In UniLMv2, the joint modeling of MLM and PLM is achieved through a multi-stream mechanism similar to XLNet.
UniLMv2 also proposes a “partially autoregressive” mechanism in PLM modeling. Traditional “autoregressive” prediction is token-by-token, while “partially autoregressive” prediction includes a concept similar to Span (referred to as block-wise masking in the paper), where during generation, the tokens forming the Span are predicted together, i.e., span-by-span prediction is performed in PLM.
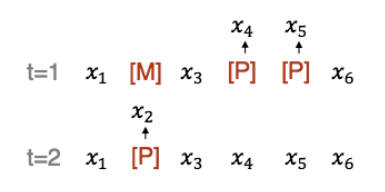
“Partially autoregressive” prediction: (x_1, x_3, x_6) -> t=1, predict span by (x_4, x_5) -> t=2, predict token by (x_2)
In UniLMv2, with a 15% mask proportion, 40% is masked by n-gram (span) and 60% by token.
UniLMv2 conducted comprehensive strategy disambiguation experiments in the paper, and interested readers can go and observe directly.
UniLMv2 Paper Address: https://arxiv.org/abs/2002.12804
UniLMv2 Open Source Address: https://github.com/microsoft/unilm
MPNet (Microsoft)
MPNet is also a work by Microsoft researchers. This work is quite similar to UniLMv2, both exploring how to integrate MLM and PLM tasks. The MPNet paper first compares MLM and PLM from a unified perspective:
-
Output Dependency: MLM assumes that masked tokens are independent of each other (or they are mutually masked), leading to information loss when modeling context. In contrast, the prediction order of tokens to be predicted in PLM can have N factorial permutations, thus better modeling the context of the tokens to be predicted. -
Input Discrepancy: In MLM, the mask hides token information but retains positional information through “placeholders”. In standard PLM, the tokens to be predicted can only see the preceding part of the corresponding permuted sequence; at a 15% prediction ratio, it is expected to see 85% + 7.5% = 92.5% of token and positional information.
MPNet retains the MLM mask [M] for placeholders in the input, while the output only learns PLM. Therefore, in terms of input, MPNet is very similar to UniLMv2, with the main difference being that UniLMv2’s output also learns MLM.
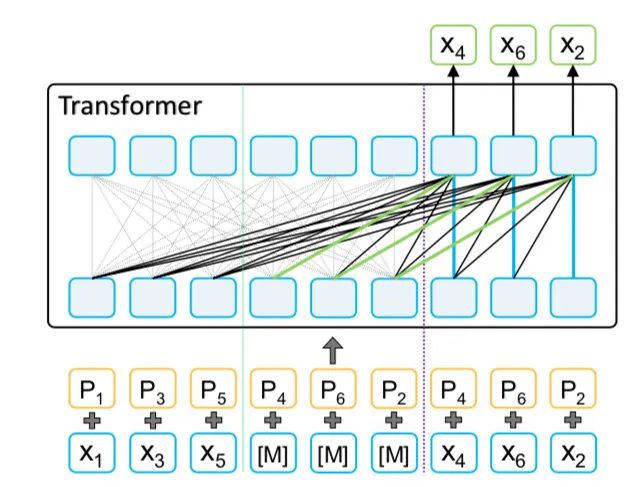
MPNet: Input includes MLM mask placeholders, output only learns PLM.
MPNet’s experiments are solid, and ablation experiments validate the effects of “position compensation” ([Maskl] placeholder) and “output dependency” (PLM) when removed in downstream tasks.
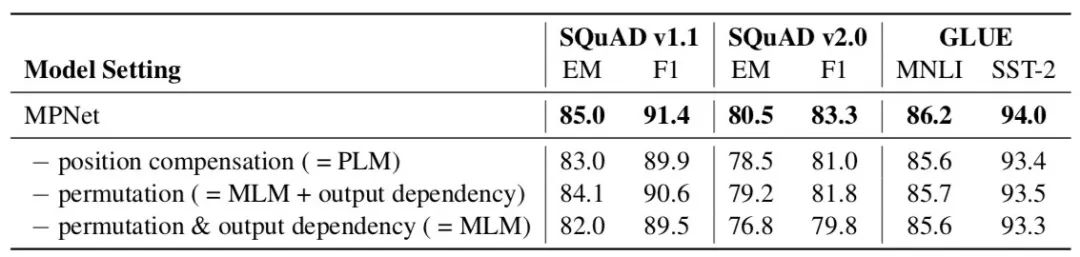
MPNet Paper Address: https://arxiv.org/abs/2004.09297
MPNet Open Source Address: https://github.com/microsoft/MPNet
Conclusion
Since BERT emerged over a year ago, language pre-training technology has continuously developed and integrated. The PLM proposed by XLNet and the dual-stream mechanism implementing PLM have been continuously promoted by more emerging language pre-training stars.
Indeed, everything is so beautiful.
Heavy! The Yizhen Natural Language Processing - TensorFlow group has officially been established! There are a lot of resources in the group, welcome everyone to join and learn! Note: Please modify the remarks when adding as [School/Company + Name + Direction] For example - Harbin Institute of Technology + Zhang San + Dialogue System. The account owner, WeChat merchants please consciously avoid. Thank you!
Recommended Reading:
Exploration of Few-Shot Dilemma in NLP
Collection of Deep Learning CNN Tricks
Several Review Articles on Multi-Task Learning