
Follow the public account “ML_NLP“

Recently, I have started using Transformer for some tasks, specifically recording related knowledge points to build a relevant and complete knowledge structure system.
The following is the article I am going to write; this is the sixteenth article in this series:
-
Transformer: The Culmination of Attention -
GPT-1 & 2: Miracles Brought by Pre-training + Fine-tuning -
Bert: Bidirectional Pre-training + Fine-tuning -
Bert and Model Compression -
Bert and Model Distillation: PKD and DistillBert -
ALBert: Lightweight Bert -
TinyBert: Comprehensive Application of Model Distillation -
MobileBert: Only 40ms on Pixel4 -
More to come -
Bert and AutoML (To Be Continued) -
Bert Variants -
Roberta: Fine-tuning Bert -
Electra: Discrimination or Generation, It’s a Choice -
Bart: Seq2Seq Pre-training Model (This Article) -
Transformer Optimization with Adaptive Width Attention -
Transformer Optimization with Sparse Attention -
Reformer: Efficiency from Local Sensitive Hashing and Reversible Residuals -
Longformer: A Mix of Local and Global Attention – Linformer: Linear Complexity Attention -
XLM: Cross-lingual Bert -
T5 (To Be Continued) -
More to come -
GPT-3 -
More to come
Overall
The Transformer was originally developed to solve machine translation problems; thus, the Transformer model is divided into two parts: Encoder and Decoder. The Bert model uses the Encoder part, while the GPT model uses the Decoder part, both achieving excellent pre-training models.
The Bart model discussed in this article, however, goes back to its roots, reintroducing the Encoder-Decoder structure, i.e., the seq2seq structure.
Bart Pre-training Model
The comparison between Bert, GPT, and Bart is as follows: Bart inputs corrupted sentences into the Encoder and then restores them in the Decoder. The advantage of this approach is that compared to the single data corruption method in Bert, Bart is more flexible.
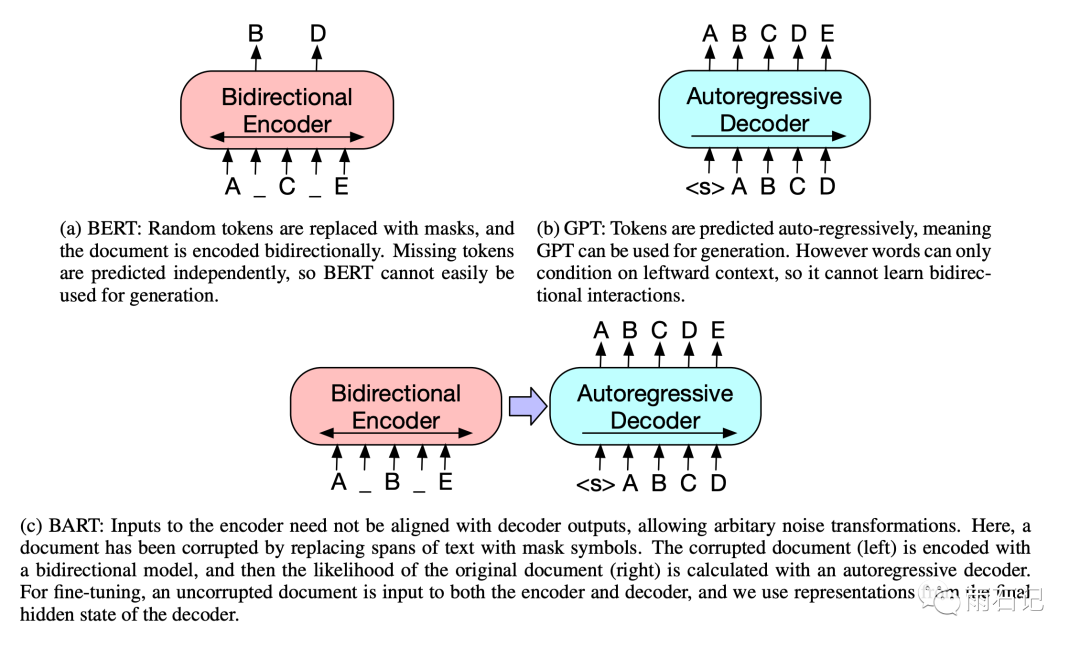
Bart’s Data Processing Method
In Bert, data is sampled and replaced with a special token [MASK] with a probability of 15%; there is also an 8:1:1 distribution, which I won’t detail here; interested readers can refer to the Bert article.
In Bart, however, the data processing is much more varied. For example, it can use a Masking method similar to Bert, deletion, reversal of order, or replacing multiple words with a single [MASK].
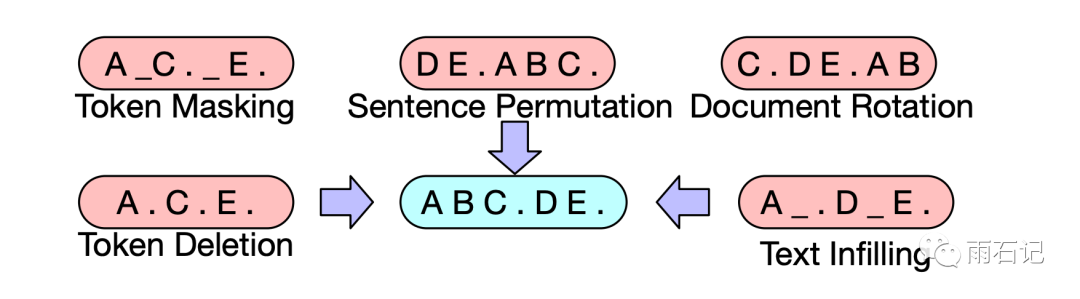
Among these, methods like word deletion and replacing multiple words with a single [MASK] can change the sentence length, which Bert cannot achieve.
This data restoration method gives Bart a significant advantage in generation tasks, as experiments have shown; additionally, Bart can achieve results comparable to Roberta in discrimination tasks.
Experiments
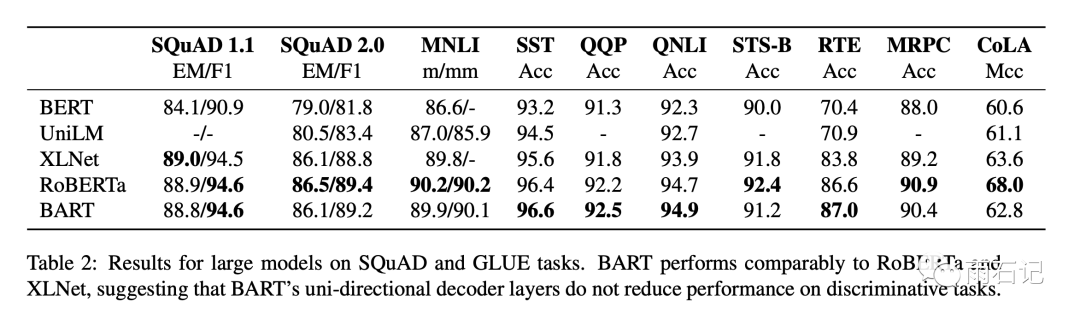
The results on the GLUE dataset are as follows: Bart can achieve results comparable to Roberta.
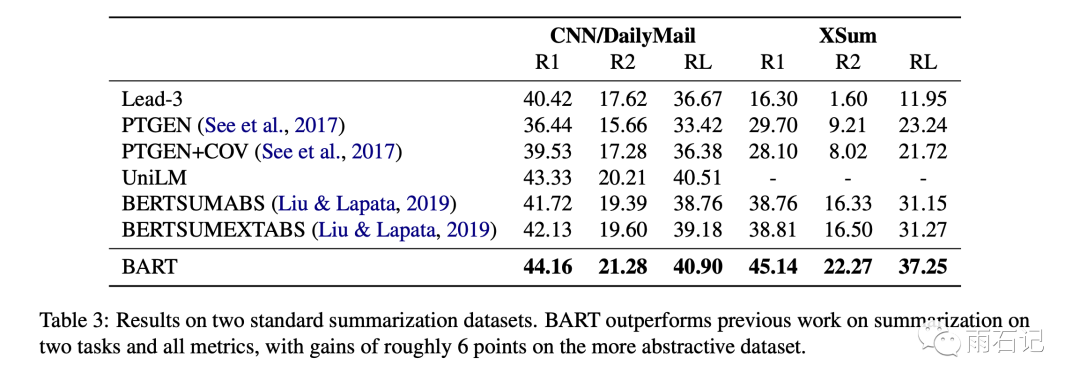
The results on the Summarization dataset are as follows:
The results on Abstractive QA are as follows:
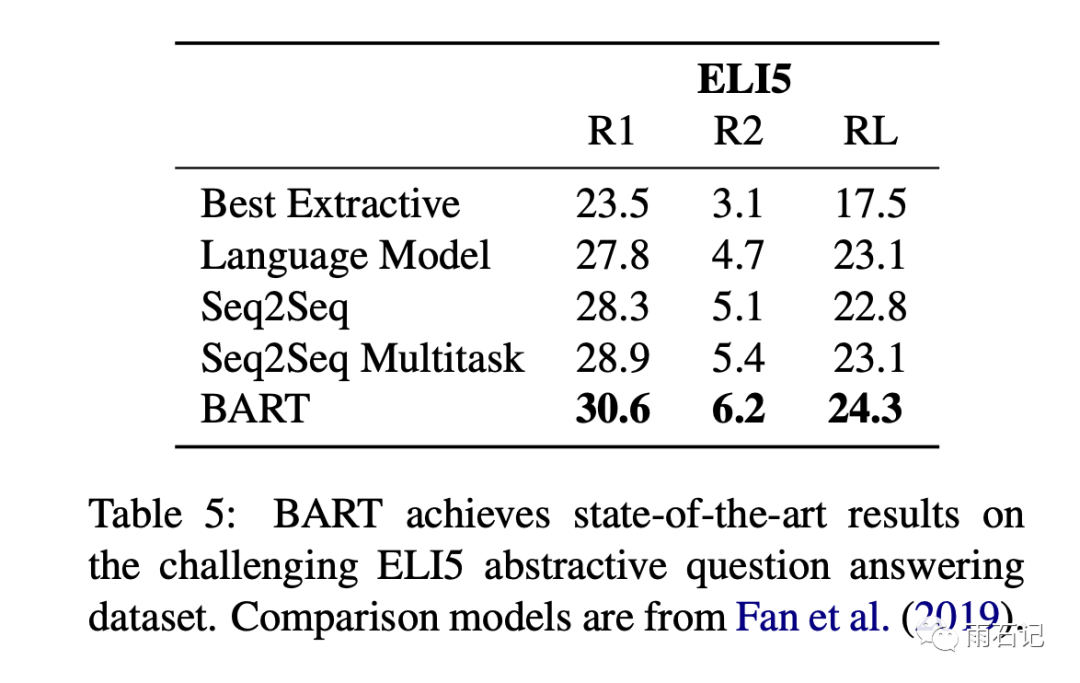
It can be seen that Bart’s approach is very effective in generation tasks.
References
-
[1]. Lewis, Mike, et al. “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.” arXiv preprint arXiv:1910.13461 (2019).
Repository address shared:
Reply "code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL + 295 ACL 2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Big news! The Machine Learning Algorithms and Natural Language Processing communication group has officially been established! There are a lot of resources in the group, and everyone is welcome to join and learn!
Extra bonus resources! Qiu Xipeng's Deep Learning and Neural Networks, official Chinese PyTorch tutorial, data analysis using Python, machine learning study notes, official Chinese version of pandas documentation, effective java (Chinese version), and other 20 bonus resources.
How to obtain: After entering the group, click on the group announcement to get the download link.
Note: Please modify the remarks when adding to [School/Company + Name + Direction]. For example - Harbin Institute of Technology + Zhang San + Dialogue System. Please avoid adding if you are a micro-business. Thank you!
Recommended reading:
Review of Open-domain Knowledge Base Question Answering Research
Automatically Train Your Deep Neural Network Using PyTorch Lightning
Collection of Common PyTorch Code Snippets