
Follow the public account “ML_NLP“
Set as “Starred“, delivering heavy content promptly!

Reprinted from | Zhihu
Author | Liang Chao Wei from Summer ResortOriginal link | https://zhuanlan.zhihu.com/p/412126626
01 – Background
In the traditional NLP unimodal field, the development of representation learning is relatively mature. However, in the multimodal field, due to the scarcity of high-quality labeled multimodal data, there is a desire to utilize few-shot learning or even zero-shot learning. In the past two years, multimodal pre-training models based on the Transformer architecture have emerged, which can be pre-trained on massive unlabeled data and then fine-tuned with a small amount of labeled data.Multimodal pre-training models can learn the semantic correspondence between different modalities through pre-training on large-scale data. In image-text modalities, we expect the model to learn to associate the word “dog” in the text with the appearance of a “dog” in the image. In video-text modalities, we expect the model to correlate objects/actions in the text with those in the video. To achieve this goal, it is necessary to cleverly design pre-training models that allow the model to explore the associations between different modalities.
02 – Paper Survey
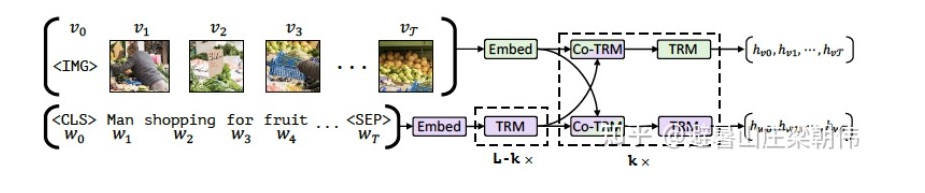
——– Divided into Single-Stream and Dual-Stream Models ———- 1.ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks NeurIPS 2019 — A pioneering work — Dual-stream motivation:The BERT model (bidirectional Transformer structure, utilizing self-attention to enhance contextual relevance) proposed in the field of Natural Language Processing (NLP) in 2018 has gradually become the preferred pre-training model for language tasks. However, a general pre-training model has not yet emerged in the intersection of vision and language, proposing a unified modeling of vision and language. Method: Images and text are processed through two different streams into a co-attentional transformer layer (in a standard Transformer, queries, keys, and values come from the previous layer. Here, the newly proposed co-transformer utilizes information from both visual and linguistic modalities simultaneously, with each stream using its own queries and keys/values from the opposite side). Images use the Faster R-CNN model to extract features from multiple target regions in the image. Since image features do not contain positional information like text features, five-dimensional data is used to encode the image positions, which are the normalized coordinates of the top-left and bottom-right corners, as well as the area. These are then projected to match the dimensionality of the visual features and summed. Task: Masked Language Modeling (MLM): 15% (80%, 10%, 10%) Masked Object Classification (MOC): 15% (90%, 10%) — Language can only express high-level semantic information of images Visual-linguistic Matching (VLM)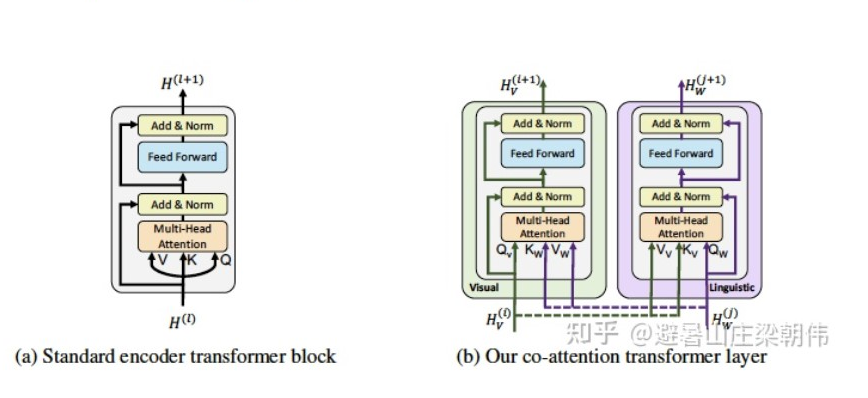
 2.VisualBERT: A Simple and Performant Baseline for Vision and Language 2019 — Single-stream motivation:Text and images are unified for semantic learning. A single-stream approach (simpler) is proposed. Method: Unlike ViLBERT, where images and text enter the transformer separately for learning, both text and images are input together into the transformer. Since it is a single stream, segment encoding needs to be added. Task: a. A portion of the text is masked, and the model predicts the masked information based on the remaining text and image information. b. The model predicts whether the provided text matches the image. The authors found that this pre-training on image-labeled data is crucial for VisualBERT to learn representations of text and images.
2.VisualBERT: A Simple and Performant Baseline for Vision and Language 2019 — Single-stream motivation:Text and images are unified for semantic learning. A single-stream approach (simpler) is proposed. Method: Unlike ViLBERT, where images and text enter the transformer separately for learning, both text and images are input together into the transformer. Since it is a single stream, segment encoding needs to be added. Task: a. A portion of the text is masked, and the model predicts the masked information based on the remaining text and image information. b. The model predicts whether the provided text matches the image. The authors found that this pre-training on image-labeled data is crucial for VisualBERT to learn representations of text and images.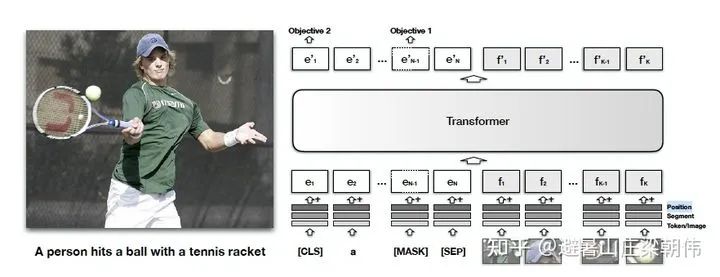 3.Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training AAAI 2020 motivation:Like VisualBERT, it belongs to the single-stream model category, adding three pre-training tasks. Method & Task: 1) Masked Language Modeling (MLM): A portion of words is masked, and the task is to infer the word based on the context. 2) Masked Object Classification (MOC): A portion of the image content is masked, and the task is to classify the image. The classification here still uses object detection techniques, simply taking the highest confidence item from object detection as the classification category. 3) Visual-linguistic Matching (VLM): Using the final hidden state of [CLS] to predict whether the linguistic sentence matches the visual content semantically, and adding a fully connected layer.
3.Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training AAAI 2020 motivation:Like VisualBERT, it belongs to the single-stream model category, adding three pre-training tasks. Method & Task: 1) Masked Language Modeling (MLM): A portion of words is masked, and the task is to infer the word based on the context. 2) Masked Object Classification (MOC): A portion of the image content is masked, and the task is to classify the image. The classification here still uses object detection techniques, simply taking the highest confidence item from object detection as the classification category. 3) Visual-linguistic Matching (VLM): Using the final hidden state of [CLS] to predict whether the linguistic sentence matches the visual content semantically, and adding a fully connected layer.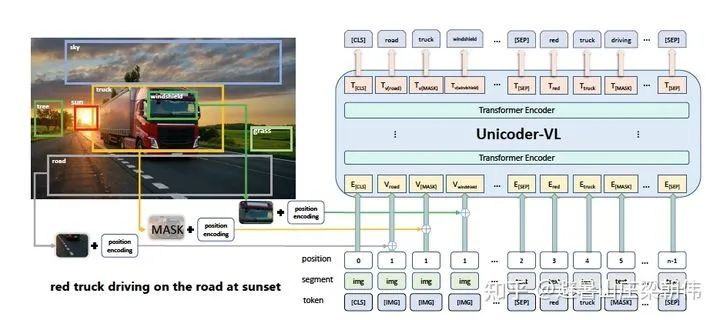 4.LXMERT: Learning Cross-Modality Encoder Representations from Transformers EMNLP 2019 motivation:Unlike ViLBERT, the cross-attention adds a fully connected layer after the cross operation, integrating information from both images and text. Additional pre-training task objectives are added, such as Masked Cross-Modality LM. The image question-answering task is also introduced into the pre-training tasks (training with datasets like VQA). Method & Task: Masked text prediction (Masked Cross-Modality LM) is set up similarly to BERT’s MLM task. The authors believe that besides predicting masked words from non-modal words in the language modality, LXMERT can also utilize its cross-modal model architecture to predict masked words from the visual modality, thus solving ambiguity issues, hence the task is named Masked Cross-Modality LM to emphasize this difference. Masked image category prediction (Detected-Label Classification): This task requires the model to predict the target category of the masked ROI based on image clues and corresponding text clues. Masked image feature regression (RoI-Feature Regression): Unlike category prediction, this task regresses the predicted target ROI feature vector with L2 loss. Image-text alignment (Cross-Modality Matching): By replacing the corresponding text description of the image with a 50% probability, the model determines whether the image and text description are consistent. Image question answering (Image Question Answering): Utilizes tasks related to image question answering, where training data consists of text questions about images. When the image and text question match, the model is required to predict the answers to these text questions related to the images.
4.LXMERT: Learning Cross-Modality Encoder Representations from Transformers EMNLP 2019 motivation:Unlike ViLBERT, the cross-attention adds a fully connected layer after the cross operation, integrating information from both images and text. Additional pre-training task objectives are added, such as Masked Cross-Modality LM. The image question-answering task is also introduced into the pre-training tasks (training with datasets like VQA). Method & Task: Masked text prediction (Masked Cross-Modality LM) is set up similarly to BERT’s MLM task. The authors believe that besides predicting masked words from non-modal words in the language modality, LXMERT can also utilize its cross-modal model architecture to predict masked words from the visual modality, thus solving ambiguity issues, hence the task is named Masked Cross-Modality LM to emphasize this difference. Masked image category prediction (Detected-Label Classification): This task requires the model to predict the target category of the masked ROI based on image clues and corresponding text clues. Masked image feature regression (RoI-Feature Regression): Unlike category prediction, this task regresses the predicted target ROI feature vector with L2 loss. Image-text alignment (Cross-Modality Matching): By replacing the corresponding text description of the image with a 50% probability, the model determines whether the image and text description are consistent. Image question answering (Image Question Answering): Utilizes tasks related to image question answering, where training data consists of text questions about images. When the image and text question match, the model is required to predict the answers to these text questions related to the images.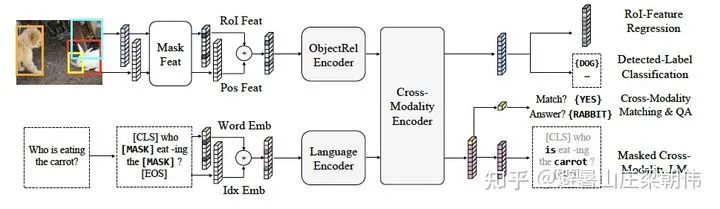 5.VL-BERT: Pre-training of Generic Visual-Linguistic Representations ICLR 2020 motivation:1) Previous papers (e.g., ViLBERT (Lu et al., 2019) and LXMERT (Tan & Bansal, 2019)) used sentence-image relationship prediction tasks, which were not helpful for pre-training visual-language representations. Therefore, such tasks are not included in VL-BERT. (2) VL-BERT is pre-trained on visual-language and pure text datasets. It was found that this joint pre-training improves generalization for long and complex sentences. (3) Improved adjustment of visual representations. In VL-BERT, the parameters of Faster R-CNN are also updated to obtain visual features. To avoid leakage of visual clues in the ROI classification pre-training task due to language clues masking, the raw pixels of the input are masked instead of masking the feature map generated by the convolutional layer. Method: Token embedding layer: For textual content, the original BERT setting is used but with an additional special token [IMG] as the token for images. Visual feature embedding layer: This layer is added to embed visual information, comprised of external visual features and visual geometric features. Specifically, for the non-visual part of the input, it is the features extracted from the entire image, while the visual part corresponds to the visual features of the ROI area images extracted by Faster R-CNN after pre-training. Segment embedding layer: The model defines three types of markers A, B, and C to indicate the source of the input. A and B indicate the first and second sentences from text, respectively, and can further indicate questions and answers in QA tasks; C indicates from images. Position embedding layer: Similar to BERT, a learnable sequential position feature is added to the text to represent the order and relative positions of the input text. For images, since there is no relative position concept, the position features of the ROI features are all the same. The authors conducted large-scale pre-training on visual-language datasets and pure language datasets, using the Conceptual Captions dataset as the visual-language corpus, which contains approximately 3.3 million images with caption annotations sourced from the internet. However, there is an issue with this dataset: the titles corresponding to the images are short sentences, which are simple and short. To prevent the model from focusing solely on simple clauses, the BooksCorpus and English Wikipedia datasets were also used for pure text training.Task: Masked text prediction (Masked Language Model with visual clues): This task is very similar to the Masked Language Modeling (MLM) task used in BERT. The key difference is that VL-BERT includes visual clues to capture the dependencies between visual and language content. Masked image category prediction (Masked RoI Classification with Linguistic Clues): Similar to masked text prediction, each RoI image is randomly masked with a probability of 15%, and the training task is to predict the category label of the masked RoI. Notably, to avoid leakage of visual clues due to embeddings of other elements’ visual features, the pixels of the masked target area must be set to zero before using Faster R-CNN.
5.VL-BERT: Pre-training of Generic Visual-Linguistic Representations ICLR 2020 motivation:1) Previous papers (e.g., ViLBERT (Lu et al., 2019) and LXMERT (Tan & Bansal, 2019)) used sentence-image relationship prediction tasks, which were not helpful for pre-training visual-language representations. Therefore, such tasks are not included in VL-BERT. (2) VL-BERT is pre-trained on visual-language and pure text datasets. It was found that this joint pre-training improves generalization for long and complex sentences. (3) Improved adjustment of visual representations. In VL-BERT, the parameters of Faster R-CNN are also updated to obtain visual features. To avoid leakage of visual clues in the ROI classification pre-training task due to language clues masking, the raw pixels of the input are masked instead of masking the feature map generated by the convolutional layer. Method: Token embedding layer: For textual content, the original BERT setting is used but with an additional special token [IMG] as the token for images. Visual feature embedding layer: This layer is added to embed visual information, comprised of external visual features and visual geometric features. Specifically, for the non-visual part of the input, it is the features extracted from the entire image, while the visual part corresponds to the visual features of the ROI area images extracted by Faster R-CNN after pre-training. Segment embedding layer: The model defines three types of markers A, B, and C to indicate the source of the input. A and B indicate the first and second sentences from text, respectively, and can further indicate questions and answers in QA tasks; C indicates from images. Position embedding layer: Similar to BERT, a learnable sequential position feature is added to the text to represent the order and relative positions of the input text. For images, since there is no relative position concept, the position features of the ROI features are all the same. The authors conducted large-scale pre-training on visual-language datasets and pure language datasets, using the Conceptual Captions dataset as the visual-language corpus, which contains approximately 3.3 million images with caption annotations sourced from the internet. However, there is an issue with this dataset: the titles corresponding to the images are short sentences, which are simple and short. To prevent the model from focusing solely on simple clauses, the BooksCorpus and English Wikipedia datasets were also used for pure text training.Task: Masked text prediction (Masked Language Model with visual clues): This task is very similar to the Masked Language Modeling (MLM) task used in BERT. The key difference is that VL-BERT includes visual clues to capture the dependencies between visual and language content. Masked image category prediction (Masked RoI Classification with Linguistic Clues): Similar to masked text prediction, each RoI image is randomly masked with a probability of 15%, and the training task is to predict the category label of the masked RoI. Notably, to avoid leakage of visual clues due to embeddings of other elements’ visual features, the pixels of the masked target area must be set to zero before using Faster R-CNN.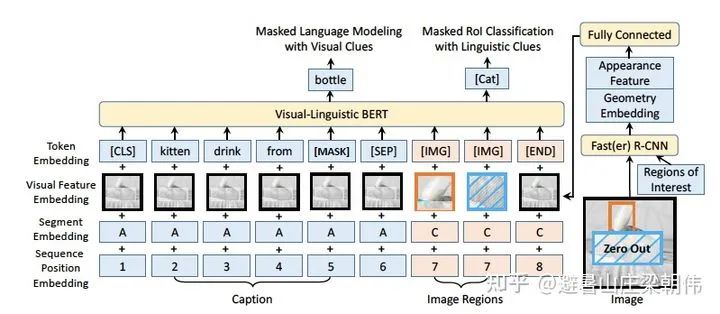 6.UNITER: UNiversal Image-TExt Representation Learning ECCV 2020 motivation:a) Pre-training tasks with text perform better than those without text; b) Vision + Language combinations in pre-training yield better results than Vision/Language alone; c) The best pre-training combination is: MLM + ITM + MRC-kl + MRFP; d) Training with the four datasets mentioned above yields the best results, proving that more data leads to better performance. e) Expanded datasets Method & Task: a) MLM (conditioned on image, masked word model) b) MRM (Mask Region Model, predicting images, regression or classification, with three variants) — MRC (Mask Region Classification), MRFR (Mask Region Feature Regression), MRC-KL (MRC + KL divergence) c) ITM (Image Text Match, consistency between images and text) d) WRA (Word Region Alignment, alignment task between words and images)
6.UNITER: UNiversal Image-TExt Representation Learning ECCV 2020 motivation:a) Pre-training tasks with text perform better than those without text; b) Vision + Language combinations in pre-training yield better results than Vision/Language alone; c) The best pre-training combination is: MLM + ITM + MRC-kl + MRFP; d) Training with the four datasets mentioned above yields the best results, proving that more data leads to better performance. e) Expanded datasets Method & Task: a) MLM (conditioned on image, masked word model) b) MRM (Mask Region Model, predicting images, regression or classification, with three variants) — MRC (Mask Region Classification), MRFR (Mask Region Feature Regression), MRC-KL (MRC + KL divergence) c) ITM (Image Text Match, consistency between images and text) d) WRA (Word Region Alignment, alignment task between words and images)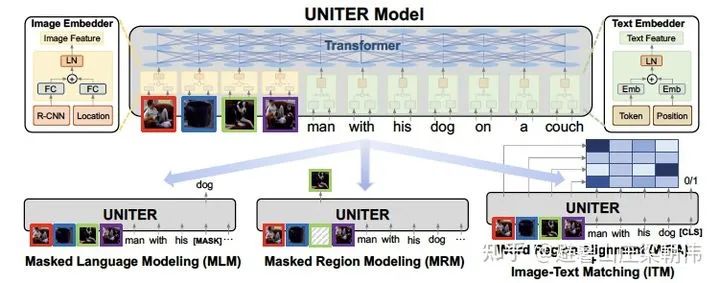 7.ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data 2020 motivation:Mainly expands data, with 10 million processed image-text pair data crawled from the internet. Previous UNITER combined four datasets (Conceptual Captions, SBU Captions, Visual Genome, MSCOCO) to form a 9.6 million training corpus, achieving the best results on multiple image-text cross-modal tasks. LXMERT added some VQA training data to pre-training and also achieved the best results on VQA tasks, proving that more data is better. Method & Task: During the model pre-training process, four tasks were designed to model the interactions between language information and visual content. The four tasks are: masked language modeling (Masked Language Modeling), masked object classification (Masked Object Classification), masked region feature regression (Masked Region Feature Regression), and image-text matching (Image-Text Matching). Masked language modeling is abbreviated as MLM, and the training process in this task is similar to that in BERT. A negative log-likelihood is introduced for prediction, based on the cross-attention between textual tokens and visual features. Masked object classification (MOC) is an extension of masked language modeling. Similar to the language model, it performs masked modeling on visual object labels and masks object objects with a probability of 15%, with probabilities of 90% and 10% for masking and retaining labels, respectively. Additionally, a fully connected layer is added in this task, utilizing a cross-entropy minimization optimization objective, combining the context of language features, and introducing negative log-likelihood for predicting the correct labels. Masked region feature regression (MRFR), similar to masked object classification, also models visual content, but does so more precisely in object feature prediction. As the name suggests, this task aims to regress the embedding features of each masked object. A fully connected layer is added to the output feature vector, projecting it to the same dimensions as the aggregated input RoI object features, and applying the L2 loss function for regression. Notably, all three tasks use conditional masking, meaning that when the input image and text are related, only the masked loss is calculated. In the image-text matching task, the main goal is to learn image-text alignment (image-text alignment). Specifically, for each training sample, a negative sentence is randomly extracted for each image, and a negative image for each sentence, generating negative training data. In this task, binary classification loss is used for optimization.
7.ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data 2020 motivation:Mainly expands data, with 10 million processed image-text pair data crawled from the internet. Previous UNITER combined four datasets (Conceptual Captions, SBU Captions, Visual Genome, MSCOCO) to form a 9.6 million training corpus, achieving the best results on multiple image-text cross-modal tasks. LXMERT added some VQA training data to pre-training and also achieved the best results on VQA tasks, proving that more data is better. Method & Task: During the model pre-training process, four tasks were designed to model the interactions between language information and visual content. The four tasks are: masked language modeling (Masked Language Modeling), masked object classification (Masked Object Classification), masked region feature regression (Masked Region Feature Regression), and image-text matching (Image-Text Matching). Masked language modeling is abbreviated as MLM, and the training process in this task is similar to that in BERT. A negative log-likelihood is introduced for prediction, based on the cross-attention between textual tokens and visual features. Masked object classification (MOC) is an extension of masked language modeling. Similar to the language model, it performs masked modeling on visual object labels and masks object objects with a probability of 15%, with probabilities of 90% and 10% for masking and retaining labels, respectively. Additionally, a fully connected layer is added in this task, utilizing a cross-entropy minimization optimization objective, combining the context of language features, and introducing negative log-likelihood for predicting the correct labels. Masked region feature regression (MRFR), similar to masked object classification, also models visual content, but does so more precisely in object feature prediction. As the name suggests, this task aims to regress the embedding features of each masked object. A fully connected layer is added to the output feature vector, projecting it to the same dimensions as the aggregated input RoI object features, and applying the L2 loss function for regression. Notably, all three tasks use conditional masking, meaning that when the input image and text are related, only the masked loss is calculated. In the image-text matching task, the main goal is to learn image-text alignment (image-text alignment). Specifically, for each training sample, a negative sentence is randomly extracted for each image, and a negative image for each sentence, generating negative training data. In this task, binary classification loss is used for optimization.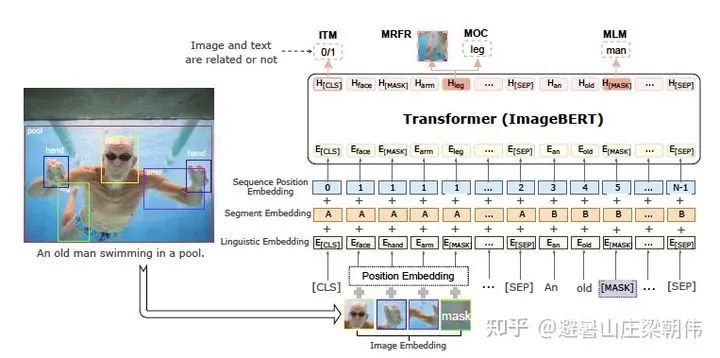 8.Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers 2020 motivation:A significant challenge in multimodal tasks is the semantic gap between different modalities. In previous works, such as VQA and Image Captioning, CNNs pretrained on image classification tasks were used to extract image features. Later, with the introduction of the attention mechanism, most visual-language methods utilized region-based visual features obtained from object detection models. However, region-based feature extractors are designed for specific visual tasks, which can lead to gaps in language understanding. Some important visual information is missing, such as the shapes of objects, spatial relationships, and overlaps. Additionally, this semantic representation ability is limited to the semantic categories contained within the model used for the task, which means that objects outside of this range cannot obtain semantic information. Some visual information is lost: object shapes, spatial relationships (overlap), and emotional representation capabilities are limited by the types of object labels. Method & Task: a) Sentence encoding: Uses the same encoding method as BERT. b) Image encoding: Convolves the image, pools it, and finally obtains a feature matrix (elements are feature vectors). After sampling, each element is added to a semantic embedding, which acts as a bias. Finally, it is flattened to obtain the final pixel feature encoding. c) Multimodal encoding: Concatenates the two representations, passes through TRM, and obtains the final representation. d) Tasks: MLM task and image-text matching task
8.Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers 2020 motivation:A significant challenge in multimodal tasks is the semantic gap between different modalities. In previous works, such as VQA and Image Captioning, CNNs pretrained on image classification tasks were used to extract image features. Later, with the introduction of the attention mechanism, most visual-language methods utilized region-based visual features obtained from object detection models. However, region-based feature extractors are designed for specific visual tasks, which can lead to gaps in language understanding. Some important visual information is missing, such as the shapes of objects, spatial relationships, and overlaps. Additionally, this semantic representation ability is limited to the semantic categories contained within the model used for the task, which means that objects outside of this range cannot obtain semantic information. Some visual information is lost: object shapes, spatial relationships (overlap), and emotional representation capabilities are limited by the types of object labels. Method & Task: a) Sentence encoding: Uses the same encoding method as BERT. b) Image encoding: Convolves the image, pools it, and finally obtains a feature matrix (elements are feature vectors). After sampling, each element is added to a semantic embedding, which acts as a bias. Finally, it is flattened to obtain the final pixel feature encoding. c) Multimodal encoding: Concatenates the two representations, passes through TRM, and obtains the final representation. d) Tasks: MLM task and image-text matching task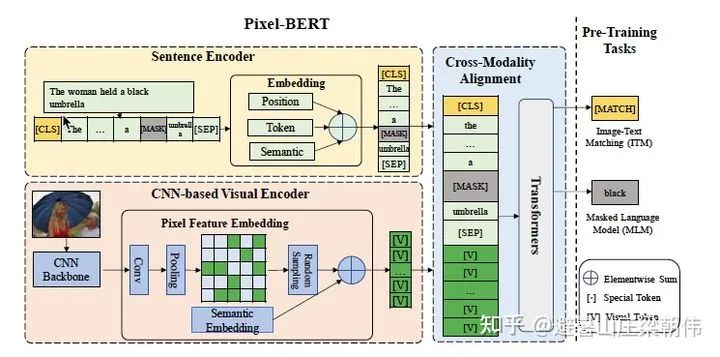 9.Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks ECCV 2020 motivation:A new learning method, Oscar, is proposed, which uses object labels detected in images as anchors to align image and language modalities in a shared semantic space. The Oscar model was pre-trained on a public corpus of 6.5 million image-text pairs, validating its effectiveness. Method & Task: Uses tokens, object labels, and regional features as input, adding mask token loss and contrastive loss.
9.Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks ECCV 2020 motivation:A new learning method, Oscar, is proposed, which uses object labels detected in images as anchors to align image and language modalities in a shared semantic space. The Oscar model was pre-trained on a public corpus of 6.5 million image-text pairs, validating its effectiveness. Method & Task: Uses tokens, object labels, and regional features as input, adding mask token loss and contrastive loss.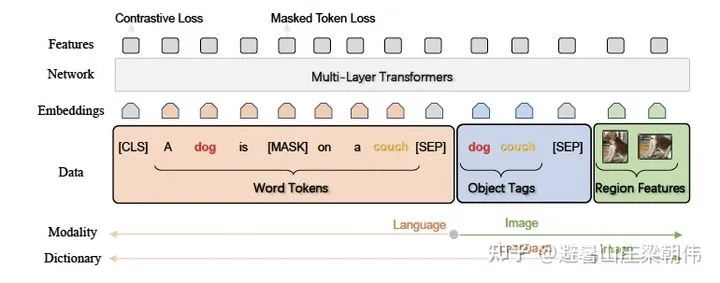 10.InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining KDD 2020 motivation:Proposes a method for maintaining modality independence after introducing broader masks and higher-order interaction features. Method & Task: masked segment modeling (MSM), masked region modeling (MRM), Image-Text Matching with Hard Negatives, constructing strong negatives (based on tf-idf).
10.InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining KDD 2020 motivation:Proposes a method for maintaining modality independence after introducing broader masks and higher-order interaction features. Method & Task: masked segment modeling (MSM), masked region modeling (MRM), Image-Text Matching with Hard Negatives, constructing strong negatives (based on tf-idf).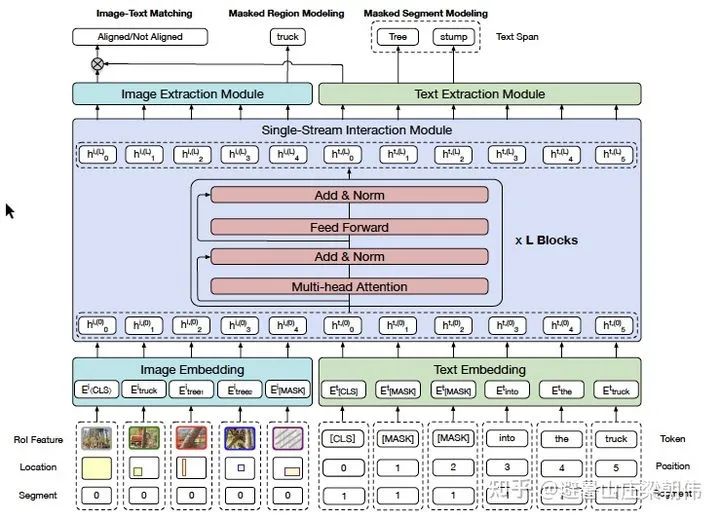 11.Large-Scale Adversarial Training for Vision-and-Language Representation Learning NeurIPS 2020 motivation:Pre-training and fine-tuning are inherently closely related. The training of the model requires mastering essential reasoning skills, promoting modality fusion, and achieving cross-modal joint understanding. By performing adversarial training during the pre-training stage, improved generalization capabilities are beneficial for the fine-tuning stage; during the fine-tuning stage, task-related fine-tuning signals become available, and adversarial fine-tuning can be used for further performance enhancement. Since pre-training and fine-tuning share the same mathematical expression, the same adversarial algorithm can be applied in both stages. Method & Task: freelb (adversarial training) + multimodal pre-training objectives
11.Large-Scale Adversarial Training for Vision-and-Language Representation Learning NeurIPS 2020 motivation:Pre-training and fine-tuning are inherently closely related. The training of the model requires mastering essential reasoning skills, promoting modality fusion, and achieving cross-modal joint understanding. By performing adversarial training during the pre-training stage, improved generalization capabilities are beneficial for the fine-tuning stage; during the fine-tuning stage, task-related fine-tuning signals become available, and adversarial fine-tuning can be used for further performance enhancement. Since pre-training and fine-tuning share the same mathematical expression, the same adversarial algorithm can be applied in both stages. Method & Task: freelb (adversarial training) + multimodal pre-training objectives 12.ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph AAAI 2021 motivation:When people look at a picture, they first pay attention to the objects (Objects) as well as their attributes (Attributes) and the relationships (Relationships) between them. For instance, “car”, “person”, “cat”, “house”, etc., are the basic elements that constitute the scene in the image; while the attributes of the objects, such as “the cat is white”, “the car is brown”, provide a more detailed description of the objects; the positional and semantic relationships between objects, such as “the cat is on the car”, “the car is in front of the house”, establish the associations between the objects in the scene. Therefore, objects, attributes, and relationships together constitute the detailed semantics of the visual scene. Image information represents the most basic and intuitive visual information. Deeper semantic information, such as the connotation of the image, historical background, character actions, and causal reasoning, etc. Based on this observation, incorporating scene graphs containing prior knowledge of the scene into the multimodal pre-training process models the fine-grained semantic associations between visual and language modalities, learning a joint representation that contains fine-grained semantic alignment information. Method: Proposes three multimodal pre-training scene graph prediction tasks: Object Prediction, Attribute Prediction, Relationship Prediction. Object prediction: Randomly select a portion of objects in the image, such as “house” in the image below, mask the corresponding word in the sentence, and the model predicts the masked part based on text context and image. Attribute prediction: For the attribute-object pairs in the scene graph, such as “
12.ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph AAAI 2021 motivation:When people look at a picture, they first pay attention to the objects (Objects) as well as their attributes (Attributes) and the relationships (Relationships) between them. For instance, “car”, “person”, “cat”, “house”, etc., are the basic elements that constitute the scene in the image; while the attributes of the objects, such as “the cat is white”, “the car is brown”, provide a more detailed description of the objects; the positional and semantic relationships between objects, such as “the cat is on the car”, “the car is in front of the house”, establish the associations between the objects in the scene. Therefore, objects, attributes, and relationships together constitute the detailed semantics of the visual scene. Image information represents the most basic and intuitive visual information. Deeper semantic information, such as the connotation of the image, historical background, character actions, and causal reasoning, etc. Based on this observation, incorporating scene graphs containing prior knowledge of the scene into the multimodal pre-training process models the fine-grained semantic associations between visual and language modalities, learning a joint representation that contains fine-grained semantic alignment information. Method: Proposes three multimodal pre-training scene graph prediction tasks: Object Prediction, Attribute Prediction, Relationship Prediction. Object prediction: Randomly select a portion of objects in the image, such as “house” in the image below, mask the corresponding word in the sentence, and the model predicts the masked part based on text context and image. Attribute prediction: For the attribute-object pairs in the scene graph, such as “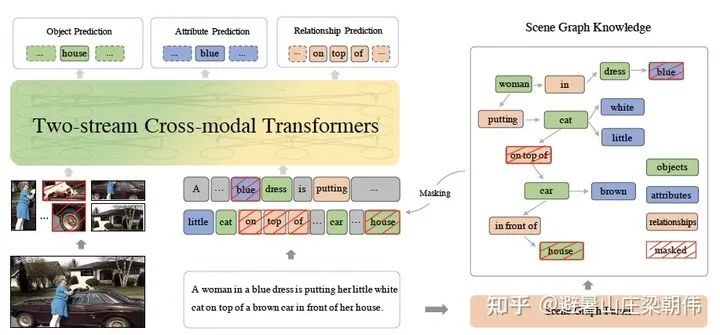 13.ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision ICML 2021 motivation:A multimodal method based on patch projection, improving speed, but overall performance is still slightly lower than region feature methods. Method: For the text feature input part, treats text as a sequence of words, converting it into word embedding through a word embedding matrix, and then adding it to the position embedding, finally concatenating with the modal-type embedding. For the image feature input part, treats image patches as a sequence of image blocks, converting it into visual embedding through linear projection, and then adding it to the position embedding, finally concatenating with the modal-type embedding. The word embedding and visual embedding are distinguished by a learnable modal-type embedding flag, where the 0 flag indicates the word embedding part and the 1 flag indicates the visual embedding part. Both word embedding and visual embedding each embed an additional learnable [class] embedding for easier integration with downstream tasks. Task: The optimization objectives for ViLT pre-training are two: one is image text matching (ITM), and the other is masked language modeling (MLM). Image Text Matching: Randomly replaces the image corresponding to the text with a different image with a probability of 0.5, and then uses a linear ITM head to map the output features into binary logits to determine whether the image and text match. Additionally, ViLT also designs a word patch alignment (WPA) to calculate the alignment score between the textual subset and visual subset. Masked Language Modeling: The goal of MLM is to predict the masked text tokens using the context information of the text. Randomly masks tokens with a probability of 0.15, then the text output connects to two layers of MLP with the masked tokens.
13.ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision ICML 2021 motivation:A multimodal method based on patch projection, improving speed, but overall performance is still slightly lower than region feature methods. Method: For the text feature input part, treats text as a sequence of words, converting it into word embedding through a word embedding matrix, and then adding it to the position embedding, finally concatenating with the modal-type embedding. For the image feature input part, treats image patches as a sequence of image blocks, converting it into visual embedding through linear projection, and then adding it to the position embedding, finally concatenating with the modal-type embedding. The word embedding and visual embedding are distinguished by a learnable modal-type embedding flag, where the 0 flag indicates the word embedding part and the 1 flag indicates the visual embedding part. Both word embedding and visual embedding each embed an additional learnable [class] embedding for easier integration with downstream tasks. Task: The optimization objectives for ViLT pre-training are two: one is image text matching (ITM), and the other is masked language modeling (MLM). Image Text Matching: Randomly replaces the image corresponding to the text with a different image with a probability of 0.5, and then uses a linear ITM head to map the output features into binary logits to determine whether the image and text match. Additionally, ViLT also designs a word patch alignment (WPA) to calculate the alignment score between the textual subset and visual subset. Masked Language Modeling: The goal of MLM is to predict the masked text tokens using the context information of the text. Randomly masks tokens with a probability of 0.15, then the text output connects to two layers of MLP with the masked tokens.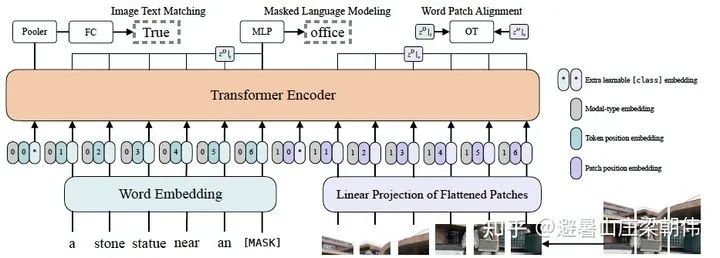 14.Learning Transferable Visual Models From Natural Language Supervision openai 2021 motivation:Transforms classification models into image-text matching tasks, using text to weakly supervise image classification. PET’s application in visual classification used a dataset of 400 million image-text pairs from the web, treating text as image labels for training. During downstream tasks, only text descriptions corresponding to concepts on the image need to be provided for zero-shot transfer. Evaluated using linear prob, it significantly outperformed other models across 27 datasets, with 20 of them surpassing the performance of open-source SOTA trained on ImageNet, and was trained in two weeks on 256 GPUs. Method & Task: 1. CLIP encodes a batch of texts into a batch of word embeddings through a Text Encoder, encodes a batch of images (corresponding to texts) into a batch of feature embeddings through an Image Encoder, then normalizes and computes the dot product between corresponding word embeddings and feature embeddings to obtain a similarity matrix. The larger the dot product, the more similar the word embedding and feature embedding vectors are, where the supervisory signal is that the diagonal of the matrix is 1, and the rest are 0. The Text Encoder uses Transformer, while the Image Encoder uses either ResNet50 or ViT architecture, both trained from scratch. 2. The pre-trained CLIP is then transferred to downstream tasks, constructing a batch of labeled texts (e.g., A photo of a {plane}) as labels for downstream tasks, which are then encoded into corresponding word embeddings through the Text Encoder. 3. Finally, zero-shot predictions are made for unseen images by encoding an image of a dog into a feature embedding through the Image Encoder, normalizing it, and computing the dot product with the batch of word embeddings from step 2 to obtain logits, with the position of the maximum value in the logits corresponding to the final predicted label. From CLIP’s process, it can be seen that the prompt usage in CLIP and PET is very similar, where “A photo of a” serves as a manually designed prompt. Subsequent CoOp seems to correspond to p-tuning, completing the development from PET to P-tuning.
14.Learning Transferable Visual Models From Natural Language Supervision openai 2021 motivation:Transforms classification models into image-text matching tasks, using text to weakly supervise image classification. PET’s application in visual classification used a dataset of 400 million image-text pairs from the web, treating text as image labels for training. During downstream tasks, only text descriptions corresponding to concepts on the image need to be provided for zero-shot transfer. Evaluated using linear prob, it significantly outperformed other models across 27 datasets, with 20 of them surpassing the performance of open-source SOTA trained on ImageNet, and was trained in two weeks on 256 GPUs. Method & Task: 1. CLIP encodes a batch of texts into a batch of word embeddings through a Text Encoder, encodes a batch of images (corresponding to texts) into a batch of feature embeddings through an Image Encoder, then normalizes and computes the dot product between corresponding word embeddings and feature embeddings to obtain a similarity matrix. The larger the dot product, the more similar the word embedding and feature embedding vectors are, where the supervisory signal is that the diagonal of the matrix is 1, and the rest are 0. The Text Encoder uses Transformer, while the Image Encoder uses either ResNet50 or ViT architecture, both trained from scratch. 2. The pre-trained CLIP is then transferred to downstream tasks, constructing a batch of labeled texts (e.g., A photo of a {plane}) as labels for downstream tasks, which are then encoded into corresponding word embeddings through the Text Encoder. 3. Finally, zero-shot predictions are made for unseen images by encoding an image of a dog into a feature embedding through the Image Encoder, normalizing it, and computing the dot product with the batch of word embeddings from step 2 to obtain logits, with the position of the maximum value in the logits corresponding to the final predicted label. From CLIP’s process, it can be seen that the prompt usage in CLIP and PET is very similar, where “A photo of a” serves as a manually designed prompt. Subsequent CoOp seems to correspond to p-tuning, completing the development from PET to P-tuning.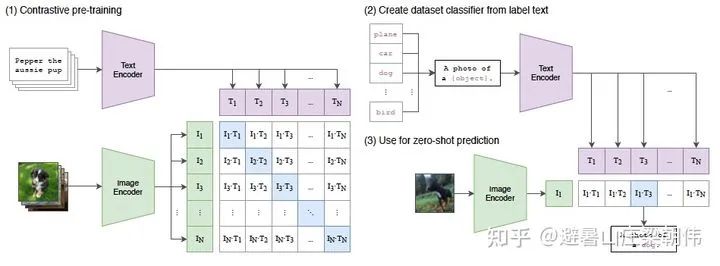 15.UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning ACL 2021 motivation:Existing pre-training models primarily target single-modal or multimodal tasks separately, but cannot adapt well to both types of tasks simultaneously. Moreover, current pre-training models for multimodal tasks can only train on a very limited amount of multimodal data (image-text pairs). This paper proposes a unified modal pre-training framework, UNIMO, which can effectively perform both single-modal and multimodal content understanding and generation tasks. The advantage of UNIMO is that it can utilize a large amount of open-domain text corpora and image collections to enhance visual and textual understanding, while employing cross-modal contrastive learning (CMCL) on augmented image-text pair datasets to learn a unified semantic space that maps more textual and visual information. Thanks to the use of rich non-aligned single-modal data, UNIMO can learn broader feature representations. Method: The paper integrates single-modal texts, images, and image-text pairs, adopting a dual-stream model and proposing cross-modal contrastive learning. The text side retrieves positive samples through back-translation and tf-idf, generating strong negative examples through scene graph parsing and rewriting. The visual side retrieves positive samples through object detection and tf-idf. For CMCL, each positive sample of image-text pairs is concatenated with several difficult negative samples generated through sentence rewriting, as well as several positive samples of retrieved images and texts; all other image-text pairs are treated as negative samples. Task: Visual learning: Similar to the masked language model in BERT, each image undergoes sampling of image regions, and the features of the image regions are masked with a probability of 15%. The masked image region features are replaced with zeros. Since a certain region of an image may overlap significantly with other regions, a threshold for overlap is set (0.3 in this paper), and all regions exceeding this threshold will be masked to prevent information leakage. Because visual feature vectors are often high-dimensional and continuous, both feature regression and target category classification metrics are used to better learn visual representations. Language learning: To learn language features for language understanding and generation tasks, the model adopts a unified encoder-decoder structure to pre-train two language model tasks: bidirectional prediction and seq2seq generation. UNIMO’s significant advantage is its ability to simultaneously use single-modal and multimodal data for pre-training, thus learning a more powerful unified modal semantic representation from large-scale data. To validate the effectiveness of single-modal data, the paper also conducted separation experiments. The experimental results indicate that when single-modal text data is not used for pre-training, UNIMO’s performance on multimodal tasks declines. Conversely, when single-modal image-text pairs and image data are not used, UNIMO’s performance on text understanding and generation tasks also declines. This fully demonstrates the effectiveness of single-modal data in unified modal learning, indicating that the UNIMO model can effectively utilize different modal data for cross-modal joint learning.
15.UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning ACL 2021 motivation:Existing pre-training models primarily target single-modal or multimodal tasks separately, but cannot adapt well to both types of tasks simultaneously. Moreover, current pre-training models for multimodal tasks can only train on a very limited amount of multimodal data (image-text pairs). This paper proposes a unified modal pre-training framework, UNIMO, which can effectively perform both single-modal and multimodal content understanding and generation tasks. The advantage of UNIMO is that it can utilize a large amount of open-domain text corpora and image collections to enhance visual and textual understanding, while employing cross-modal contrastive learning (CMCL) on augmented image-text pair datasets to learn a unified semantic space that maps more textual and visual information. Thanks to the use of rich non-aligned single-modal data, UNIMO can learn broader feature representations. Method: The paper integrates single-modal texts, images, and image-text pairs, adopting a dual-stream model and proposing cross-modal contrastive learning. The text side retrieves positive samples through back-translation and tf-idf, generating strong negative examples through scene graph parsing and rewriting. The visual side retrieves positive samples through object detection and tf-idf. For CMCL, each positive sample of image-text pairs is concatenated with several difficult negative samples generated through sentence rewriting, as well as several positive samples of retrieved images and texts; all other image-text pairs are treated as negative samples. Task: Visual learning: Similar to the masked language model in BERT, each image undergoes sampling of image regions, and the features of the image regions are masked with a probability of 15%. The masked image region features are replaced with zeros. Since a certain region of an image may overlap significantly with other regions, a threshold for overlap is set (0.3 in this paper), and all regions exceeding this threshold will be masked to prevent information leakage. Because visual feature vectors are often high-dimensional and continuous, both feature regression and target category classification metrics are used to better learn visual representations. Language learning: To learn language features for language understanding and generation tasks, the model adopts a unified encoder-decoder structure to pre-train two language model tasks: bidirectional prediction and seq2seq generation. UNIMO’s significant advantage is its ability to simultaneously use single-modal and multimodal data for pre-training, thus learning a more powerful unified modal semantic representation from large-scale data. To validate the effectiveness of single-modal data, the paper also conducted separation experiments. The experimental results indicate that when single-modal text data is not used for pre-training, UNIMO’s performance on multimodal tasks declines. Conversely, when single-modal image-text pairs and image data are not used, UNIMO’s performance on text understanding and generation tasks also declines. This fully demonstrates the effectiveness of single-modal data in unified modal learning, indicating that the UNIMO model can effectively utilize different modal data for cross-modal joint learning.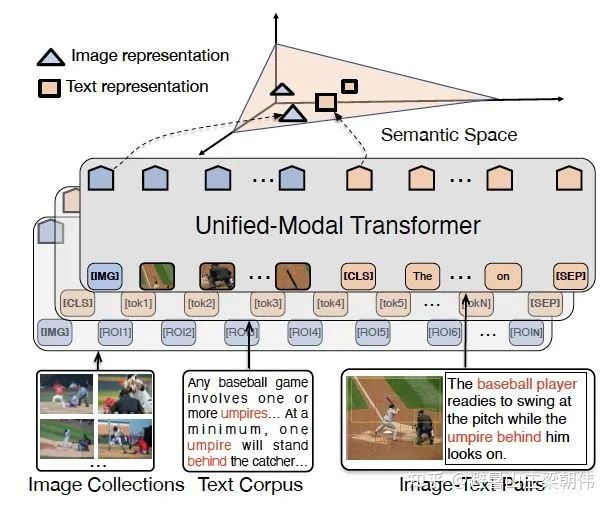 16.Zero-Shot Text-to-Image Generation openai 2021 motivation:Traditional text-to-image generation methods focus on finding better modeling assumptions to facilitate training on fixed datasets. However, these assumptions may involve complex structures, auxiliary losses, or target partial labels or segmentation masks provided during training. In this paper, the authors propose a simple method to tackle this task, based on transformers, modeling text and image tokens autoregressively as a single data stream. When sufficient data and scale are available, the proposed method is competitive when evaluated in zero-shot scenarios compared to previous domain-specific models. The difficulty of generating images with GPT lies in the fact that image patch information is continuous, making it challenging to discretize like NLP. DALL·E generates images of size 256×256. The specific approach divides the image into 32×32 patches, with each patch mapped to a vocabulary of size 8192 by discrete VAE. Thus, the image is composed of 1024 tokens. This is concatenated with 256 sentence tokens, resulting in a token sequence of length 1280. This discrete VAE is designed based on VQVAE, which is quite impressive. Such discrete tokens may evolve into a universal practice for self-supervised pre-training of visual transformers. Method & Task: 1. In the first phase, a dVAE is trained to compress each 256×256 RGB image into 32×32 image tokens, each position having 8192 possible values (meaning the output of the dVAE encoder is of dimension 32x32x8192 logits, which are then indexed into the codebook features for combination, with the codebook embeddings being learnable). 2. In the second phase, a BPE Encoder encodes the text into a maximum of 256 text tokens. If the number of tokens is less than 256, it is padded to 256, then the 256 text tokens are concatenated with the 1024 image tokens, resulting in a length of 1280 data, which is finally input into the Transformer for autoregressive training. 3. During the inference phase, given a candidate image and a piece of text, the transformer can generate the fused tokens, then use the dVAE decoder to generate the image, and finally compute the matching score between the text and the generated image using the pre-trained CLIP. By sampling a larger number of images, different sampling images can be ranked by their scores obtained through CLIP. From the above process, it can be seen that the dVAE, Transformer, and CLIP models are independently trained at different stages.
16.Zero-Shot Text-to-Image Generation openai 2021 motivation:Traditional text-to-image generation methods focus on finding better modeling assumptions to facilitate training on fixed datasets. However, these assumptions may involve complex structures, auxiliary losses, or target partial labels or segmentation masks provided during training. In this paper, the authors propose a simple method to tackle this task, based on transformers, modeling text and image tokens autoregressively as a single data stream. When sufficient data and scale are available, the proposed method is competitive when evaluated in zero-shot scenarios compared to previous domain-specific models. The difficulty of generating images with GPT lies in the fact that image patch information is continuous, making it challenging to discretize like NLP. DALL·E generates images of size 256×256. The specific approach divides the image into 32×32 patches, with each patch mapped to a vocabulary of size 8192 by discrete VAE. Thus, the image is composed of 1024 tokens. This is concatenated with 256 sentence tokens, resulting in a token sequence of length 1280. This discrete VAE is designed based on VQVAE, which is quite impressive. Such discrete tokens may evolve into a universal practice for self-supervised pre-training of visual transformers. Method & Task: 1. In the first phase, a dVAE is trained to compress each 256×256 RGB image into 32×32 image tokens, each position having 8192 possible values (meaning the output of the dVAE encoder is of dimension 32x32x8192 logits, which are then indexed into the codebook features for combination, with the codebook embeddings being learnable). 2. In the second phase, a BPE Encoder encodes the text into a maximum of 256 text tokens. If the number of tokens is less than 256, it is padded to 256, then the 256 text tokens are concatenated with the 1024 image tokens, resulting in a length of 1280 data, which is finally input into the Transformer for autoregressive training. 3. During the inference phase, given a candidate image and a piece of text, the transformer can generate the fused tokens, then use the dVAE decoder to generate the image, and finally compute the matching score between the text and the generated image using the pre-trained CLIP. By sampling a larger number of images, different sampling images can be ranked by their scores obtained through CLIP. From the above process, it can be seen that the dVAE, Transformer, and CLIP models are independently trained at different stages.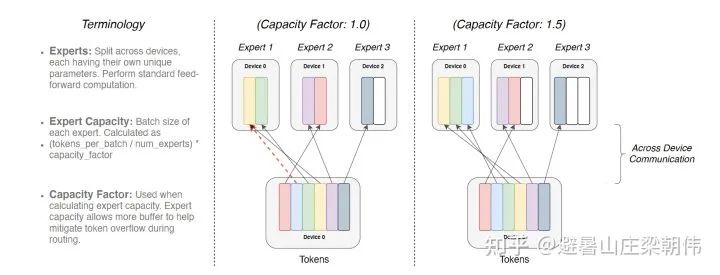
03 – Summary and Outlook:
Through the organization of multimodal pre-training tasks, we can find that existing pre-training tasks mainly fall into two categories. One category is primarily designed for single-modal data, such as masked text prediction and masked image prediction. Among these, masked text prediction continues to follow the design of BERT, while masked image prediction and masked frame prediction generally do not directly predict the original object/frames, but rather predict features. The second category is primarily designed for multimodal data. Tasks in this category are designed to exploit corresponding relationships within different modalities, such as image-text alignment. Current multimodal pre-training models have made certain progress, achieving remarkable performance on multiple downstream tasks. Future work may achieve further progress in several directions: first, whether improvements can be made on single-modal downstream tasks. Most multimodal pre-training models are tested on multimodal downstream tasks, with few works comprehensively comparing single-modal tasks like natural language processing with single-modal pre-training models like RoBERTa. If it is believed that models trained on multimodal data can better understand semantics, intuitively, multimodal pre-training models should outperform single-modal models under similar experimental settings (e.g., similar corpus scales). Second, more refined exploration of the correlations between different modal data and the design of more clever pre-training tasks. For instance, exploring the correlation between image-text, nouns, and object objects, allowing the model to establish correlations between words and object objects. Third, designing more efficient model architectures and exploring larger-scale high-quality multimodal data.
04 – Large Model Training Methods:
1.MoE: Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. 2017 motivation:As models grow larger and training samples increase, each sample requires the full computation of the model, leading to quadratic growth in training costs. To solve this problem, large models are split into multiple smaller models, so that for a sample, it is unnecessary to compute through all small models; only a portion of small models are activated for computation, saving computational resources. How to determine which small models a sample goes through introduces a sparse gate mechanism, where the sample input is given to this gate to obtain the activated small model indices, ensuring sparsity to optimize computational capacity. Method: First, MoE is a layer, not an entire model. Secondly, as mentioned, this model structure includes a gating network to determine which expert to activate and contains n expert networks, which are generally of the same structure. To ensure sparsity and balance, the softmax is processed, with the first modification being KeepTopK, a discrete function that forces values outside the top-k to negative infinity, resulting in softmax values of 0. The second modification introduces noise, aiming for balance, with a Wnoise parameter added, which will also be modified at the loss function level. Without improvements, many experts would only be used by a few. To address this issue, a soft constraint method is employed. We define the importance of an expert for a batch of training samples, i.e., the sum of the gating output values for that expert over a batch. A loss term is defined and added to the total loss of the model. This loss term equals the variance squared of all expert importance, plus a manually adjusted proportional factor. This loss term encourages all experts to have similar importance.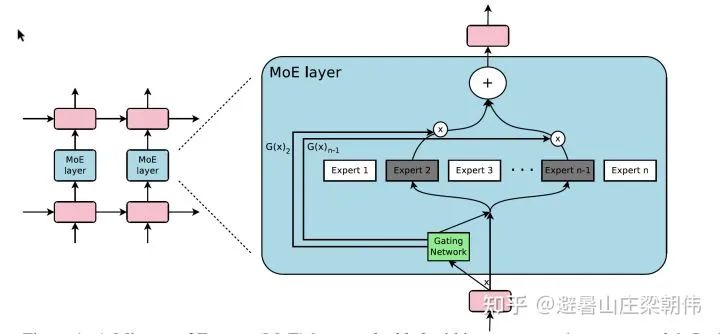 2.Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism 2019 motivation:Utilizes model parallel methods to address the challenges of training large models, focusing on tensor parallelism to enhance training speed. It implements a simple yet efficient model parallel method, successfully breaking through the limitations of training on a single GPU. Method: Matrix decomposition
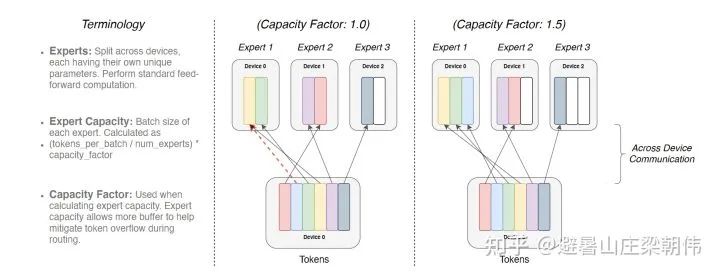
2.Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism 2019 motivation:Utilizes model parallel methods to address the challenges of training large models, focusing on tensor parallelism to enhance training speed. It implements a simple yet efficient model parallel method, successfully breaking through the limitations of training on a single GPU. Method: Matrix decomposition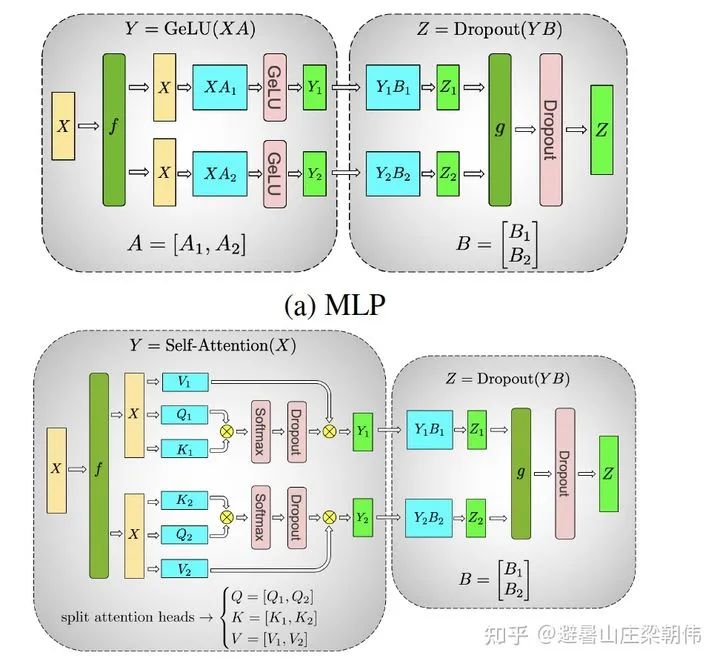 3.ZeRO: Memory Optimizations Toward Training Trillion Parameter Models 2019 motivation:Addresses the issue of each GPU storing the entire model parameters, leading to exceeding GPU memory limits, reducing memory usage while increasing computational overhead. The three main parallel modes in current distributed training are data parallelism, model parallelism, and pipeline parallelism. Among these, data parallelism is widely used due to its ease of use. However, data parallelism generates a lot of redundant Model States occupying space. 1. Optimizer States: Optimizer States are the data required by the Optimizer for gradient updates, e.g., Momentum in SGD and Float32 Master Parameters when using mixed precision training. 2. Gradient: The gradients produced after backpropagation determine the direction of parameter updates. 3. Model Parameter: Model parameters are the information we learn through data throughout the process. Under traditional data parallelism, each process uses the same parameters for training. Each process also holds complete copies of Optimizer States, etc., occupying a significant amount of GPU memory. ZeRO, on the basis of data parallelism, introduces optimizations for redundant Model States. After using ZeRO, each process only saves 1/GPUs of the complete state, with no overlap, eliminating redundancy. Method: ZeRO has three different levels, corresponding to different degrees of partitioning Model States (Partition): – ZeRO-1: Partitioning Optimizer States; – ZeRO-2: Partitioning Optimizer States and Gradients; – ZeRO-3: Partitioning Optimizer States, Gradients, and Parameters. Finally, we summarize the training steps of zero optimization, taking the Pos+g+p mode as an example: Initial state: Suppose there are Nd GPUs, then each GPU (gpu_n) saves 1/Nd of the total parameters; and saves the corresponding gradients and optimizer states (P_n,G_n,O_n); parameters can be partitioned by layer; each gpu_n is also responsible for the data assigned to it (data_n); a. During the forward computation of the first layer, gpu_n broadcasts its responsible parameters (P_n) to all other GPUs; subsequent model layers follow this process; finally, each gpu_n obtains the loss corresponding to its data (data_n); b. During the backward computation, gpu_n broadcasts its responsible parameters (P_n) to all other GPUs, ultimately calculating the gradients corresponding to its data (data_n); c. The gradients from step two are aggregated to the corresponding gpu_n, with each gpu updating its own P_n,G_n,O_n; proceeding to the next iteration. From this training process, it can be seen that during parameter transmission, a broadcasting method is used, while the gradient aggregation process uses a reduce-scatter pattern similar to Allreduce, but no all-gather is needed because each GPU only needs to update its part of the parameters.
3.ZeRO: Memory Optimizations Toward Training Trillion Parameter Models 2019 motivation:Addresses the issue of each GPU storing the entire model parameters, leading to exceeding GPU memory limits, reducing memory usage while increasing computational overhead. The three main parallel modes in current distributed training are data parallelism, model parallelism, and pipeline parallelism. Among these, data parallelism is widely used due to its ease of use. However, data parallelism generates a lot of redundant Model States occupying space. 1. Optimizer States: Optimizer States are the data required by the Optimizer for gradient updates, e.g., Momentum in SGD and Float32 Master Parameters when using mixed precision training. 2. Gradient: The gradients produced after backpropagation determine the direction of parameter updates. 3. Model Parameter: Model parameters are the information we learn through data throughout the process. Under traditional data parallelism, each process uses the same parameters for training. Each process also holds complete copies of Optimizer States, etc., occupying a significant amount of GPU memory. ZeRO, on the basis of data parallelism, introduces optimizations for redundant Model States. After using ZeRO, each process only saves 1/GPUs of the complete state, with no overlap, eliminating redundancy. Method: ZeRO has three different levels, corresponding to different degrees of partitioning Model States (Partition): – ZeRO-1: Partitioning Optimizer States; – ZeRO-2: Partitioning Optimizer States and Gradients; – ZeRO-3: Partitioning Optimizer States, Gradients, and Parameters. Finally, we summarize the training steps of zero optimization, taking the Pos+g+p mode as an example: Initial state: Suppose there are Nd GPUs, then each GPU (gpu_n) saves 1/Nd of the total parameters; and saves the corresponding gradients and optimizer states (P_n,G_n,O_n); parameters can be partitioned by layer; each gpu_n is also responsible for the data assigned to it (data_n); a. During the forward computation of the first layer, gpu_n broadcasts its responsible parameters (P_n) to all other GPUs; subsequent model layers follow this process; finally, each gpu_n obtains the loss corresponding to its data (data_n); b. During the backward computation, gpu_n broadcasts its responsible parameters (P_n) to all other GPUs, ultimately calculating the gradients corresponding to its data (data_n); c. The gradients from step two are aggregated to the corresponding gpu_n, with each gpu updating its own P_n,G_n,O_n; proceeding to the next iteration. From this training process, it can be seen that during parameter transmission, a broadcasting method is used, while the gradient aggregation process uses a reduce-scatter pattern similar to Allreduce, but no all-gather is needed because each GPU only needs to update its part of the parameters.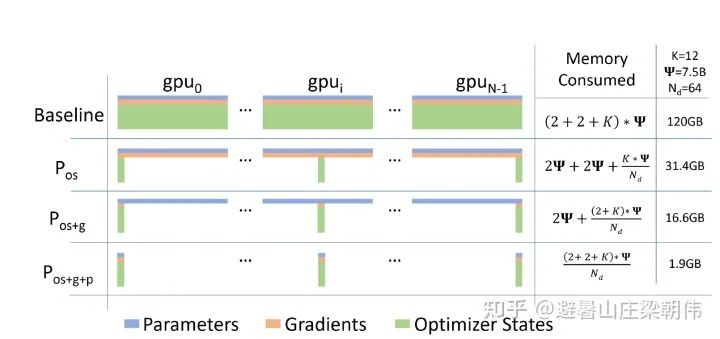 4.GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding ICLR 2021 motivation:The first work to introduce the MoE structure into the Transformer architecture, GShard replaces the Feedforward Network (FFN) layer in the Transformer with the MoE layer and cleverly combines MoE layers with data parallelism. During data parallel training, the model is already replicated multiple times in the training cluster. GShard achieves the MoE layer functionality by treating each data-parallel FFN as an expert in MoE, implementing All-to-All communication in multiple data parallel paths. Method: Essentially, it replaces the original FFN (two-layer fully connected) with the MoE structure.
4.GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding ICLR 2021 motivation:The first work to introduce the MoE structure into the Transformer architecture, GShard replaces the Feedforward Network (FFN) layer in the Transformer with the MoE layer and cleverly combines MoE layers with data parallelism. During data parallel training, the model is already replicated multiple times in the training cluster. GShard achieves the MoE layer functionality by treating each data-parallel FFN as an expert in MoE, implementing All-to-All communication in multiple data parallel paths. Method: Essentially, it replaces the original FFN (two-layer fully connected) with the MoE structure.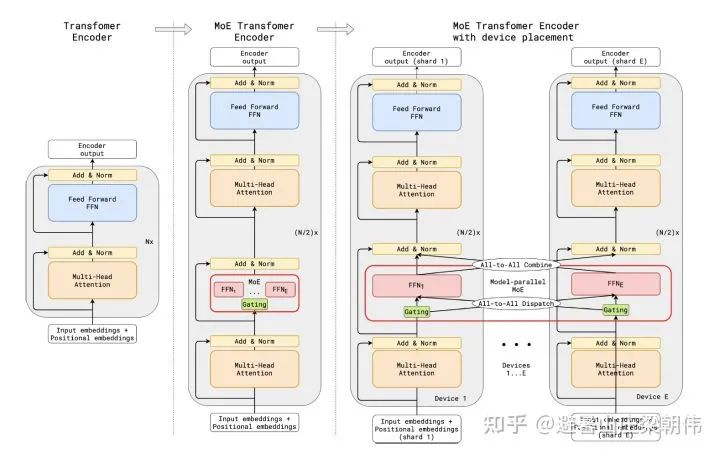 5.Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 2021 motivation:Scales the parameter count of language models to 1.6 trillion, simplifying the MoE routing algorithm by sending token representations to a single expert. Research shows that this simplified strategy maintains model quality, reduces routing computations, and performs better. This k=1 strategy is referred to as the Switch layer. If too many tokens are sent to a single expert (referred to as “dropped tokens”), computation will be skipped, and token representations will be directly passed to the lower layer via residual connections. However, increasing expert capacity is not without drawbacks, as excessively high numbers will lead to computational and memory waste, ultimately applied to the t5 model. Method: Simplifies sparse routing: only sends token representations to a single expert; efficient sparse routing: if too many tokens are sent to a single expert, computation will be skipped, and token representations will be passed to the lower layer via residual connections; enhances training and fine-tuning techniques: regularizes large sparse models, uses selectable row precision for large sparse models, and improves scalability: the number of experts is the most effective dimension for scaling the model; step-based scalability: having more parameters (experts) can increase training speed while keeping FLOPS per token constant; time-based scalability: the speed advantage of Switch Transformer is evident when both training time and computational costs are fixed.
5.Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 2021 motivation:Scales the parameter count of language models to 1.6 trillion, simplifying the MoE routing algorithm by sending token representations to a single expert. Research shows that this simplified strategy maintains model quality, reduces routing computations, and performs better. This k=1 strategy is referred to as the Switch layer. If too many tokens are sent to a single expert (referred to as “dropped tokens”), computation will be skipped, and token representations will be directly passed to the lower layer via residual connections. However, increasing expert capacity is not without drawbacks, as excessively high numbers will lead to computational and memory waste, ultimately applied to the t5 model. Method: Simplifies sparse routing: only sends token representations to a single expert; efficient sparse routing: if too many tokens are sent to a single expert, computation will be skipped, and token representations will be passed to the lower layer via residual connections; enhances training and fine-tuning techniques: regularizes large sparse models, uses selectable row precision for large sparse models, and improves scalability: the number of experts is the most effective dimension for scaling the model; step-based scalability: having more parameters (experts) can increase training speed while keeping FLOPS per token constant; time-based scalability: the speed advantage of Switch Transformer is evident when both training time and computational costs are fixed.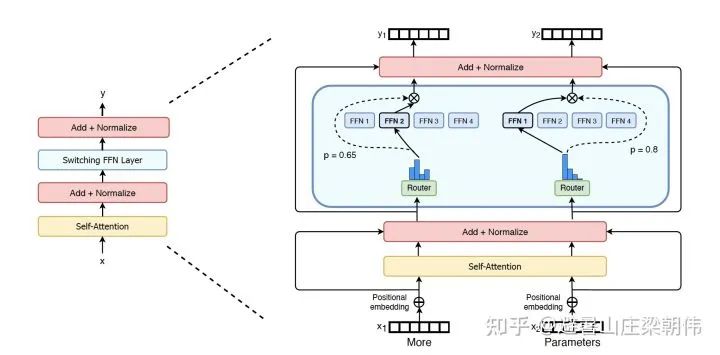
 Appendix: Comparison of Multimodal Model Tasks
Appendix: Comparison of Multimodal Model Tasks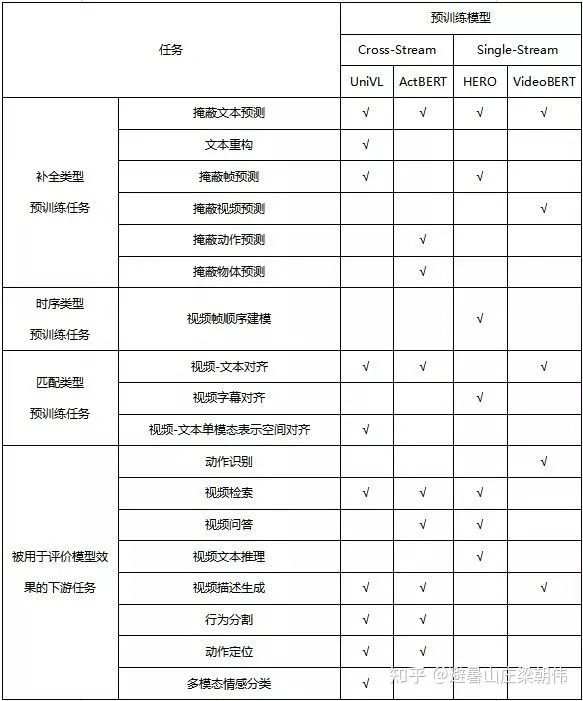
Recommended Reading:
Prompt—From CLIP to CoOp, New Paradigms in Visual-Language Models
Focal Loss --- From Intuition to Implementation
CPU and GPU, Who is the Elementary Student?
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: