Edited by | Jia Wei
Source | AI Technology Review
In the past two years, the research paradigm based on pre-training + fine-tuning has rapidly swept the entire field of NLP. This research paradigm is widely recognized as a revolutionary paradigm in NLP research, with previous paradigms including “expert systems,” “statistical models,” and “neural network models.”
Recently, with the development of technology, a new research paradigm has gradually become prevalent in the field of NLP: Pre-train, Prompt, Predict. Compared to the previous “pre-training + fine-tuning,” this research paradigm tends to make various downstream tasks accommodate the pre-trained language model, while the latter is a typical model accommodating tasks.
Dr. Liu Pengfei from CMU summarized this research paradigm and wrote a blog post on Zhihu, categorizing modern NLP research into four paradigms, which is quite profound.
Liu Pengfei, Ph.D., graduated from Fudan University and is currently conducting postdoctoral research at the Language Technologies Institute at Carnegie Mellon University (CMU). He has served as a co-lecturer for the CMU Natural Language Processing course. His main research areas include information extraction, text generation, and systematic interpretable evaluation and diagnosis. He has led the development of products such as a review robot and an AI system interpretability leaderboard, which have received widespread attention from academia, enterprises, and investors.
What is the “Fourth Paradigm” of Modern Natural Language Processing Technology Development?
Answer: (It may be) Prompt Learning empowered by pre-trained language models.
Clearly, knowing this answer is not the only important thing; in addition, understanding what the other three paradigms are and the intrinsic logic of the transitions between paradigms is even more valuable.
1) Having an overall understanding of the characteristics of each paradigm allows us to better position our current work and make our stories more impactful;
2) Ultimately, we do not just want to be promoters under a certain paradigm, but to become leaders of the next new paradigm. The key to this lies in grasping the core driving forces behind the evolution of paradigms, which requires summarizing both the present and the past.
Our recent work is precisely based on this motivation and has been completed. (http://pretrain.nlpedia.ai/)
This article hopes to discuss some content that was not included in the paper. (Papers generally include more rigorous statements, while those more personal and unproven understandings are equally valuable.)
We summarize the development of modern NLP technology into four paradigms:
P1. Fully Supervised Learning in the Non-Neural Network Era (Fully Supervised Learning, Non-Neural Network)
P2. Fully Supervised Learning Based on Neural Networks (Fully Supervised Learning, Neural Network)
P3. Pre-train, Fine-tune Paradigm (Pre-train, Fine-tune)
P4. Pre-train, Prompt, Predict Paradigm (Pre-train, Prompt, Predict)
Rules of Paradigm Evolution
During the transition between these different paradigms, some things remain unchanged, and uncovering them is quite interesting. For example:
Rule 1: Each paradigm involves complex engineering that requires human involvement (providing prior knowledge).
P1 Fully Supervised Learning in the Non-Neural Network Era
Feature Engineering (Feature Engineering): We need to go through the “boring” process of defining feature templates.
P2 Fully Supervised Learning Based on Neural Networks
Architecture Engineering (Architecture Engineering): Neural networks liberate the manpower needed for manually configuring feature templates, but at the cost of requiring humans to design suitable network structures. Therefore, in this research paradigm, researchers spend a lot of time exploring the structural bias that best fits downstream tasks (Structural Bias). For example, should we use “convolutional recurrent transformers” or “convolutional transformers”?
P3 Pre-train, Fine-tune Paradigm
Objective Engineering: In this process, researchers often introduce additional objective functions to the pre-trained language model to make it more suitable for downstream tasks.
This process sometimes requires some exploration of network structures, but comparatively speaking, it is not the main theme of this paradigm. A practical reason is that: (1) the pre-training process itself is time-consuming, and excessive exploration of structural bias incurs too much overhead; (2) during fine-tuning, often the knowledge provided by the pre-trained language model itself allows everyone to “forget” the differences between convolutional neural networks and recurrent neural networks.
P4 Pre-train, Prompt, Predict Paradigm
Prompt Engineering: In this process, we often do not make too many changes to the pre-trained language model; we hope to redefine the way downstream tasks are modeled by utilizing appropriate prompts.
Because of the existence of Rule 1, we can look at the new paradigm more dialectically. The value of this statement is reflected in two scenarios:
1) When we use methods from the new paradigm, we can realize that the excellent performance it brings comes at the cost of some “human” sacrifices (it requires some manual design). How to minimize this human cost is often the core issue that needs to be solved in the new paradigm.
2) When we suddenly have some “magical” ideas that differ greatly from the current mainstream solutions, but implementing them requires some trivial operations, then congratulations, because you are likely approaching a new paradigm (or a new solution framework). If there were a god’s perspective, perhaps that “god” is watching you, looking forward to your persistence, because you will bring unique progress to the development of this field.
Of course, going from having an idea to actually implementing it becomes another critical point, and among the factors that determine whether it can be done, perhaps the most important are: confidence, persistence, understanding of the field, and implementation ability.
Rule 2: The benefits brought by the new paradigm can allow us to temporarily “ignore” the additional human costs required.
This seems to be natural (otherwise, why would we need it?).
However, it is worth noting that the definition of “benefits” is not unique; it is not only defined as an improvement in performance on a certain task, but can also be “helping us do things that past frameworks could not do” or new research scenarios.
For example, whether in the early applications of neural networks in NLP or the early applications of Seq2Seq in translation, there was no performance advantage (compared to traditional statistical methods), but this disruptive idea provided us with a lot of imaginative space (for example, if translation can use Seq2Seq, can other tasks do the same? Then can the NLP task-solving framework be unified?).
When we look back at the process where P(N) gradually replaced P(N-1) (where P refers to the paradigms defined above), we suddenly understand:
P1->P2: Although we often complain about hyperparameter tuning in neural networks, we also enjoy the benefits of not having to manually configure templates to achieve decent or even better results. Rather than saying “tuning,” I think training neural networks is more like “pottery,” while traditional feature engineering is more like “alchemy,” because it has very stringent requirements on the selection of raw materials (features) and the order of adding them (feature combinations).
P2->P3: Although exploring “which loss function to introduce to the pre-trained language model is more suitable for downstream tasks” is relatively boring, compared to the permutations and combinations of various network structures that may not yield good performance, the former seems to be acceptable.
P3->P4: Although the definition of prompts is cumbersome, if there is a method that can help you answer the question “Since BERT performs so well, what else should I study?” then it is quite attractive. Moreover, Prompt Learning has activated many new research scenarios, such as few-shot learning, which can clearly be a boon for researchers with limited GPU resources. Of course, I understand that the most important role of Prompt Learning is to prompt us about what the core driving force of NLP development might be. If everyone is interested, they can follow up on future updates.
Can help us distinguish between “pseudo-paradigms” and “true paradigms.” If the cost of implementing a new modeling system is too complex, or the benefits are minimal, then it may not be a promising paradigm.
What Happened with Prompt Learning?
Prompt Learning refers to processing input text information according to specific templates, reconstructing the task into a form that can better utilize pre-trained language models.
For example, if I want to determine the sentiment of the sentence “I like this movie” (“positive” or “negative”),
The original task format treats it as a classification problem.
Output: “positive” or “negative”
However, if we use Prompt Learning to solve it, the task can be transformed into a “cloze test,”
Input: I like this movie; overall, this is a __ movie
Output: “interesting” or “boring”
The italicized input is to process the input text according to a specific template, and the purpose of doing this is to better adapt to the form of pre-trained language models. For example, BERT’s pre-training adopts a similar cloze test format. (Thus, the application of Prompt Learning also requires a deep understanding of the characteristics of various pre-trained language models; we provided a very detailed description in the paper (Section 3) to inform everyone about which prompting scenarios suit different pre-trained language models.)
Regarding this definition, if we dig deeper, we will find some wonderful points.
1) The techniques involved in Prompt Learning seem to have been addressed in many past works?
No doubt, whether it is the templating of inputs or the task reconstruction operation, this is not a new thing. In Section 9 of the paper, we provide a detailed comparison of some (eight) “old” research topics related to Prompt Learning, such as “Query Reformulation” and “QA-based Task Reformulation.”
2) Since past works have all been involved, why is Prompt Learning a new paradigm now?
In fact, if we look at the above description of Prompt Learning, it contains an implicit assumption that is not easy to discover: the knowledge of pre-trained language models is indeed rich, and in order to better utilize it, we are willing to reconstruct tasks at a cost (because task reconstruction itself involves many decision-making choices that require human involvement).
This indicates that the purpose of “task reconstruction” in the Prompt Learning paradigm is very clear, namely to better utilize pre-trained language models.
And this can be distinguished from past works like “Query Reformulation/QA-based Task Reformulation.” The reason is simple: because at that time, NLP technology did not have such a powerful pre-trained language model that prompted us to reconstruct tasks to “accommodate” it.
3) Is the assumption contained in Prompt Learning (the knowledge of pre-trained language models is indeed rich, and we are willing to reconstruct tasks at a cost to better utilize it) valid?
It is not necessarily valid, especially when pre-trained language models are relatively weak, for instance, in the early days of context-independent word vector models, reconstructing tasks for them might be counterproductive (this also answers the previous question of why Prompt Learning emerged at this time).
Since BERT, such context-dependent pre-trained models not only contain rich knowledge, but another important point is that they are complete individuals (for example, they have an input layer, feature extraction layer, and output layer), which means that when we design models for different downstream tasks, we have the possibility to utilize the existing network structure of pre-trained language models without designing new network layers. To achieve this, some changes need to be made, and that change is to utilize prompts to reconstruct the input of the tasks.
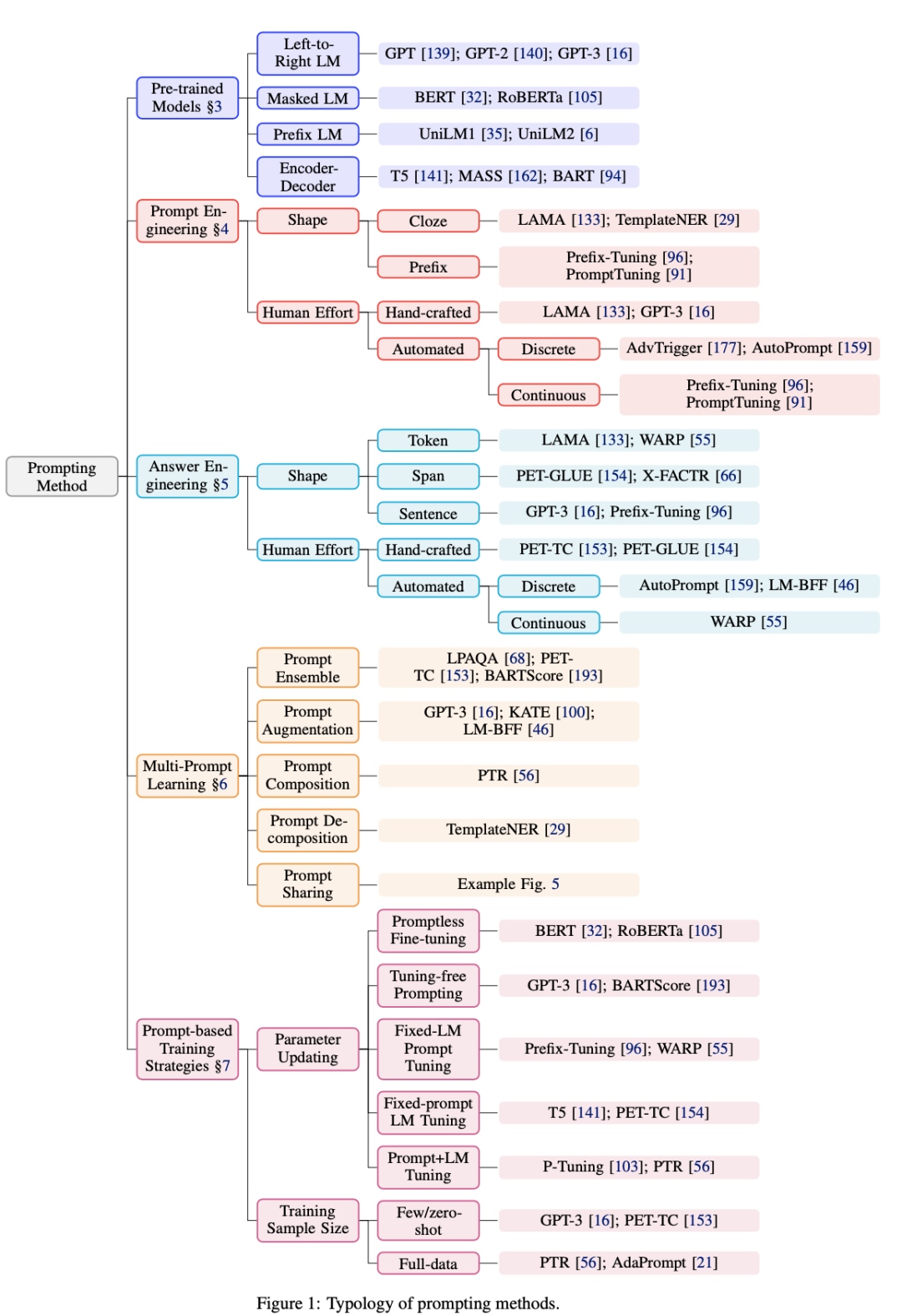
Review of Prompt Learning Research
Regarding this issue, we have tried to provide a clear review in the paper, and everyone can understand it in conjunction with the concepts in the paper (the figure below).
Relationship Between Paradigms
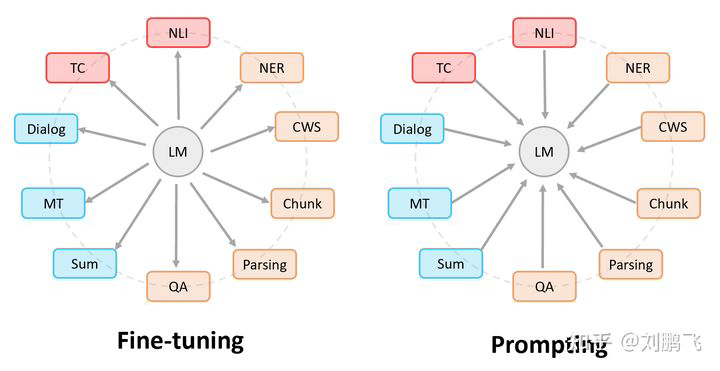
What is the relationship between the Fine-tuning paradigm that occurred in the third phase and the Prompting paradigm in the fourth phase?
Here, I would like to share a figure that I really like, although it was ultimately not included in the paper.
In the figure, circles represent pre-trained language models, and rectangles represent various downstream NLP tasks. Therefore, we have this statement: everyone hopes to bring pre-trained language models closer to downstream tasks, but the ways to achieve this are different.
In Fine-tuning: Pre-trained language models “accommodate” various downstream tasks. This is specifically reflected in the aforementioned introduction of various auxiliary task losses, adding them to the pre-trained model, and then continuing pre-training to make it more suitable for downstream tasks. In summary, in this process, the pre-trained language model sacrifices more.
In Prompting: Various downstream tasks “accommodate” pre-trained language models. This is specifically manifested in the aforementioned need to reconstruct different tasks to achieve adaptation to pre-trained language models. In summary, in this process, downstream tasks sacrifice more.
Indeed, a more harmonious state should be one where everyone “makes concessions to each other”. I believe that after reading this, everyone should have some good ideas.
Core Driving Force of NLP
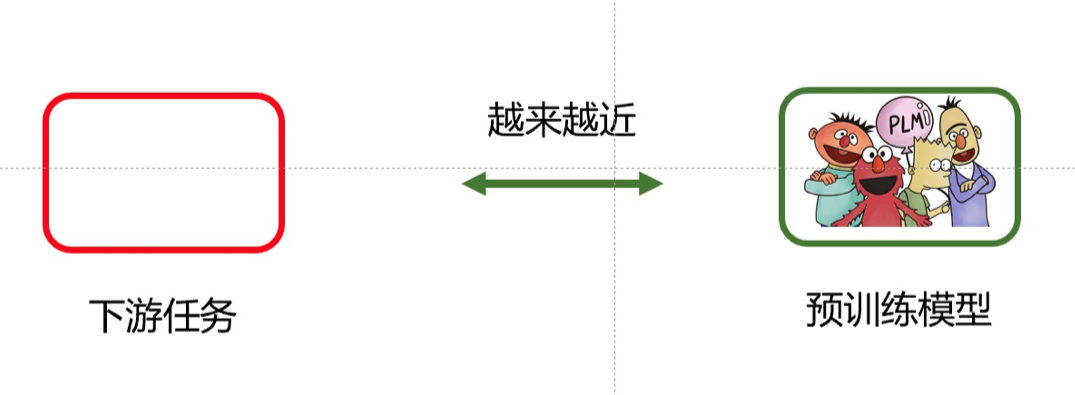
Finally, I would like to conclude this blog post with a summary that I particularly like: the development history of modern natural language processing technology is essentially (possibly) a history of the changing relationship between downstream tasks and pre-trained language models.
Therefore, when we review the events that significantly improved the performance of NLP tasks, it is likely because:
(1) Pre-trained language models were used;
(2) Stronger pre-trained language models were used;
(3) Better utilization of pre-trained language models occurred.
Prompting itself is not the goal; it is a means to bring downstream tasks and pre-trained language models closer together. If we have other better methods, we can lead to the next paradigm.