
Reprinted from the public account 【AI Meets Machine Learning】

1. Introduction to Language Models
What is a language model? Simply put, a language model is a model used to calculate the probability of a sentence, which is to judge the probability of whether a sentence is reasonable. Speaking of its applications, how to enable computers to understand human language has always been a major issue in the field of artificial intelligence. Language models are used in machine translation, question-answer systems, speech recognition, word segmentation, input methods, and search engines’ autocomplete features. Of course, initially, research was conducted on rule-based language models, which often had significant problems. Later, statistical language models were invented and found to be highly effective. The N-gram language model we are discussing today is a type of statistical language model.
The N-gram language model can be said to be the most widely used language model today. However, with the development of deep learning, there are now neural network language models using RNN/LSTM, which sometimes perform better than N-gram models. However, RNNs have the disadvantage of needing to calculate language model scores for each word in real-time, which is relatively slow.
2. Detailed Explanation of the N-Gram Model
Since we need to build a language model, based on statistical probabilities, we need to calculate the probability of a sentence:
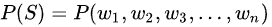
This is the probability of the final sentence we want. A high probability indicates that it is more reasonable, while a low probability indicates that it is unreasonable and not human-like…
Since we cannot calculate it directly, we first apply conditional probability to obtain:
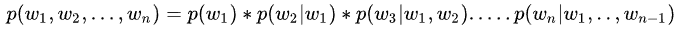
Here, we introduce conditional probability: P(B|A): the probability of B occurring under the condition A. It calculates the proportion within a subspace (slice) from a larger space.
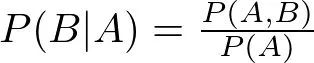
However, if we directly calculate the transformed formula of conditional probability, we have to consider all the preceding words for each word, which is not very meaningful in practice and is evidently difficult to calculate. At this point, can we add some assumptions to simplify? Yes, we can simplify it based on the Markov assumption.
What is the Markov Assumption?
The Markov assumption states that the probability of each word occurring only depends on a few preceding words. For instance, a second-order Markov assumption only considers the two preceding words, and the corresponding language model is a trigram model. A language model that introduces the Markov assumption can also be called a Markov model. A Markov chain is a random process that transitions from one state to another within a state space. This process requires the property of “memorylessness”: the probability distribution of the next state can only be determined by the current state, and previous events in the time series are irrelevant.
In other words, applying this assumption indicates that the current word is only related to a limited number of preceding words, so there is no need to trace back to the very first word, which significantly reduces the length of the aforementioned formula. The formula then becomes:
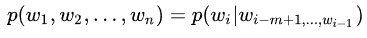
Note: Here, m indicates the number of preceding words related.
We can then set m=1, 2, 3, … to obtain the corresponding unigram model, bigram model, and trigram model.
When m=1, a unigram model is:
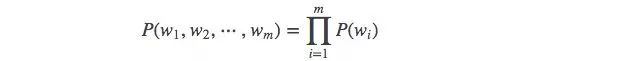
When m=2, a bigram model is:
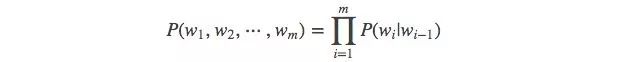
When m=3, a trigram model is:
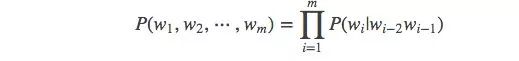
The N-Gram model is defined as follows: when m=1, it is called 1-gram or unigram; when m=2, it is called 2-gram or bigram; when m=3, it is called 3-gram or trigram; when m=N, it represents N-gram.
After explaining what the N-Gram model is, let’s discuss its classic applications for a deeper understanding:
3. Using the N-Gram Model to Evaluate the Reasonableness of Sentences
Suppose we have a corpus, and we have counted the occurrences of the following words:

The following probability values are known:
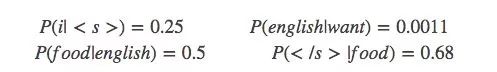
p(want|<s>) = 0.25
The following table shows the counting results based on the Bigram model:

For example, in the first row, second column, it indicates that when the previous word is “i”, the current word “want” occurred a total of 827 times. Based on this, we can derive the corresponding frequency distribution table as follows.
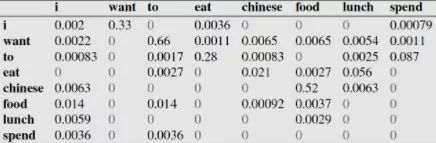
For instance, let’s explain the probability value p(eat|i)=0.0036 from the table: “i” appeared a total of 2533 times, and the occurrence of “eat” afterwards was 9 times, thus p(eat|i)=p(eat,i)/p(i)=count(eat,i)/count(i)=9/2533 = 0.0036.
Next, we will use this corpus to determine which sentence is more reasonable between s1=”<s> i want english food</s>” and s2=”<s> want i english food</s>”.
First, let’s calculate p(s1):
P(s1)=P(i|<s>)P(want|i)P(english|want)P(food|english)P(</s>|food)
=0.25×0.33×0.0011×0.5×0.68=0.000031
Now, let’s calculate p(s2):
P(s2)=P(want|<s>)P(i|want)P(english|want)P(food|english)P(</s>|food)
=0.25*0.0022*0.0011*0.5*0.68 = 0.00000002057
By comparing, we can clearly see that 0.00000002057 < 0.000031, which means s1=”i want english food</s>” is more reasonable.
Of course, the above is based on the bigram model, and you can also calculate the probabilities for the trigram or unigram models, but the results should be similar.
On a deeper level, we can find that the difference in probabilities between these two sentences is mainly due to the order of “i want” versus “want i”. According to our intuition and common collocation grammar, “i want” has a much higher occurrence probability than “want i”. Thus, the difference in probabilities makes sense.
Note: The above example is sourced from the internet.
4. Other Applications of the N-Gram Model
The n-gram model also has many other applications, as illustrated below:
1. Studying Human Civilization: The n-gram model has given rise to a new discipline (Culturomics) that studies human behavior and cultural trends through digitized texts. The book “Visualizing the Future” provides detailed insights, and you can also find discussions on Zhihu (https://www.zhihu.com/question/26166417) and TED talks (https://www.ted.com/talks/what_we_learned_from_5_million_books).
2. Search Engines: When you input one or more words into Google or Baidu, the search box typically provides a dropdown menu with several suggestions like those shown below. These suggestions are essentially guesses about the word string you want to search for. As illustrated:
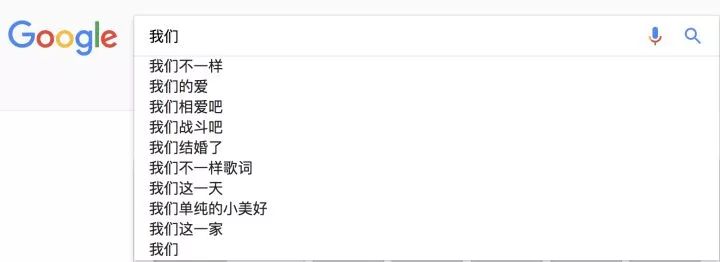
In fact, these are derived from language models. For example, using a bigram language model to predict the next word involves sorting the process as follows:
p(“不一样”|”我们”) > p(“的爱”|”我们”) > p(“相爱吧”|”我们”) > … > p(“这一家”|”我们”), where the probability values are computed in the same way as mentioned above, and the data source can be user search logs.
3. Input Methods: For example, when inputting “zhongguo”, possible outputs include: China,种过, 经过, etc. The technology behind this relies on the n-gram language model, where each item corresponds to a possible character for each pinyin.
… (There are many more applications related to language models.)
5. Conclusion
That concludes everything we have learned today. Of course, regarding n-gram, we should know that the larger the size of the corpus, the more useful the resulting n-gram is for statistical language modeling. Additionally, the size of n in n-gram has a significant impact on performance; for instance, a larger n provides more constraint information for predicting the next word, leading to greater discernibility, while a smaller n results in higher reliability due to more frequent occurrences in the training corpus. Interested readers can further explore this topic. Lastly, I recommend some books:
Wu Jun. 2012. “The Beauty of Mathematics“.
Guan Yi. 2007. Harbin Institute of Technology: Statistical Natural Language Processing.
Fandy Wang, 2012, “NLP & Statistical Language Models“.
These books all discuss n-gram or language models and are worth reading!
Recommended Reading
Step into the world of Natural Language Processing
Step into the world of Computer Vision
Insights| Simple Understanding of Overfitting and Inductive Bias
Welcometo follow us for more accessible insights!
