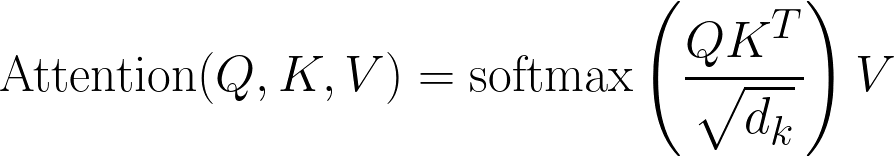MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning both domestically and internationally, especially for beginners.
Reprinted from | Machine Heart
Try a new attention pattern with FlexAttention.
Theoretically, the attention mechanism is all you need. However, in practice, we also need to optimize the implementation of attention mechanisms like FlashAttention.
Although these fused attention mechanisms greatly improve performance and support long contexts, this efficiency gain comes at the cost of flexibility. For machine learning researchers, it feels like a “software lottery” — if your attention variant does not fit the existing optimized kernels, you will face slow runtime and CUDA out-of-memory issues.
Some attention variants include causal attention, relative position embedding, Alibi, sliding window attention, PrefixLM, document masking, irregular tensors, PagedAttention, etc. Worse still, people often want to combine these variants! For example, sliding window attention + document masking + causal attention + context parallelism, or PagedAttention + sliding window combinations.
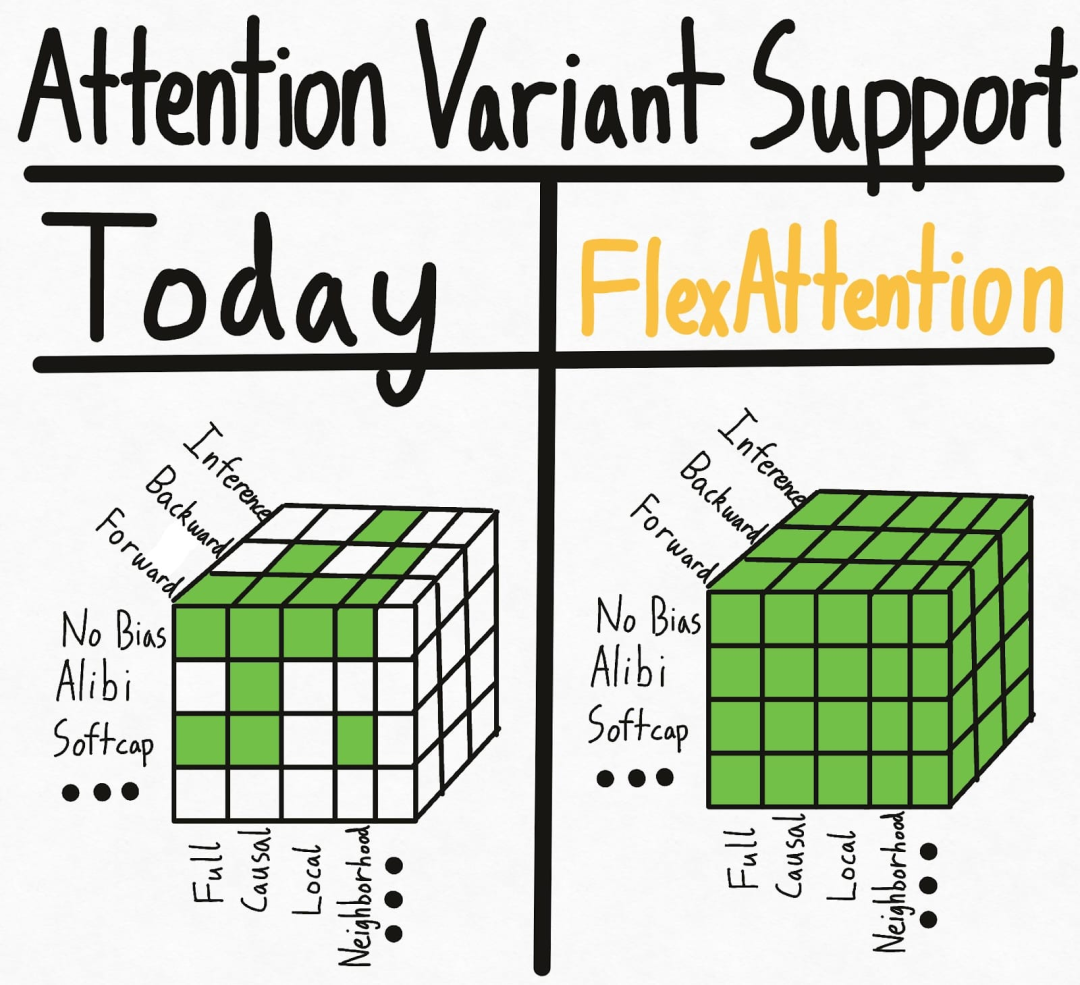
The left side of the image below represents the current situation — some combinations of masks + biases + settings already have kernel implementations. However, adding various options leads to an exponential growth in settings. Even worse, this approach does not support new attention variants.
To thoroughly solve this hypercube problem, the PyTorch team introduced FlexAttention, a new PyTorch API.
-
FlexAttention is a flexible API that allows users to implement multiple attention variants with just a few lines of idiomatic PyTorch code.
-
The team reduced it to a fused FlashAttention kernel via torch.compile, generating a FlashAttention kernel that does not consume additional memory and performs comparably to hand-written kernels.
-
Utilize PyTorch’s automatic differentiation mechanism to automatically generate backpropagation.
-
Finally, the PyTorch team can also leverage the sparsity in the attention masks, significantly improving standard attention implementations.
Tri Dao, a participant in FlashAttention versions 1-3, forwarded this research and commented: This research has integrated many technologies.
FlexAttention
The classic attention equation is as follows:
FlexAttention is as follows, addressing the above issues by accepting a user-defined function score_mod.
This function allows users to modify the attention scores before softmax. Researchers found that this function ultimately meets the needs of most users for attention variants.
Specifically, score_mod is as follows:
To apply this function, it can be implemented as:
for b in range (batch_size): for h in range (num_heads): for q_idx in range (sequence_length): for kv_idx in range (sequence_length): modified_scores [b, h, q_idx, kv_idx] = score_mod (scores [b, h, q_idx, kv_idx], b, h, q_idx, kv_idx)
The final API has surprising expressive power.
Score Mod Example
In this case, score_mod performs no operation; it takes the scores as input and returns them as is.
Relative Position Encoding
A common attention variant is relative position encoding. Relative position encoding adjusts scores based on the distance between queries and keys instead of encoding absolute distances in queries and keys.
It is worth noting that, unlike typical implementations, this does not require materializing the SxS tensor. Instead, FlexAttention dynamically computes the bias values in the kernel, significantly improving memory and performance.
Soft-capping is a technique used by Gemma 2 and Grok-1, and in FlexAttention, it takes the following form:
Although bidirectional attention is simple, in the paper “Attention is All You Need” and other LLMs, their settings are attention with only decoders, where each token can only attend to the tokens before it. If users use the score_mod API, it can be represented as:
Image source: https://arxiv.org/abs/2310.06825
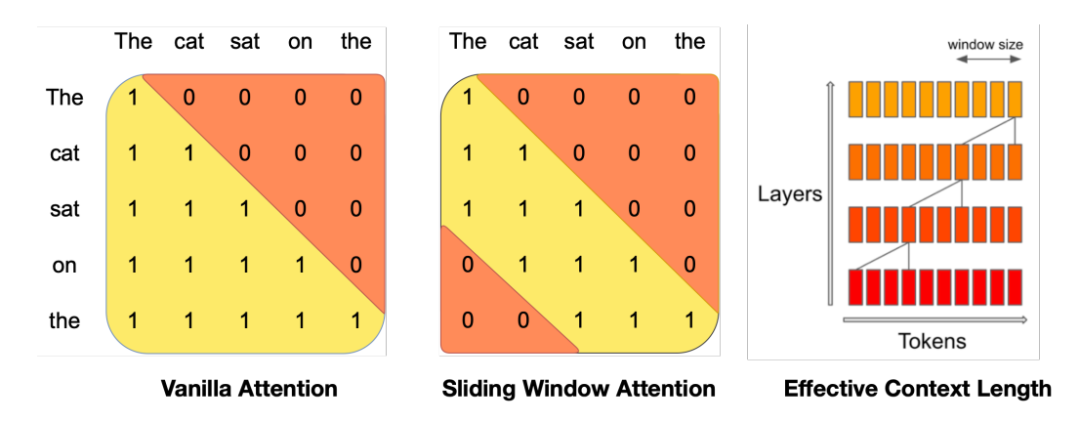
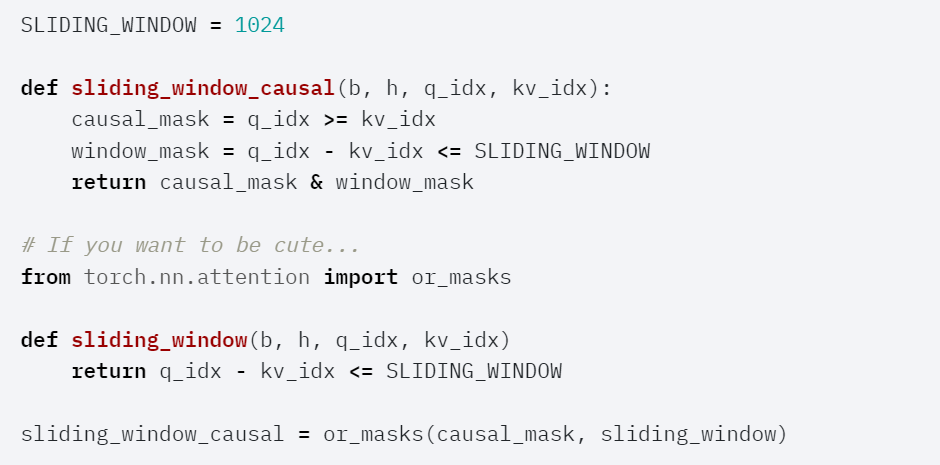
Mistral has been promoting sliding window attention (also known as local attention), which allows query tokens to only attend to the most recent 1024 tokens, usually used in conjunction with causal attention.
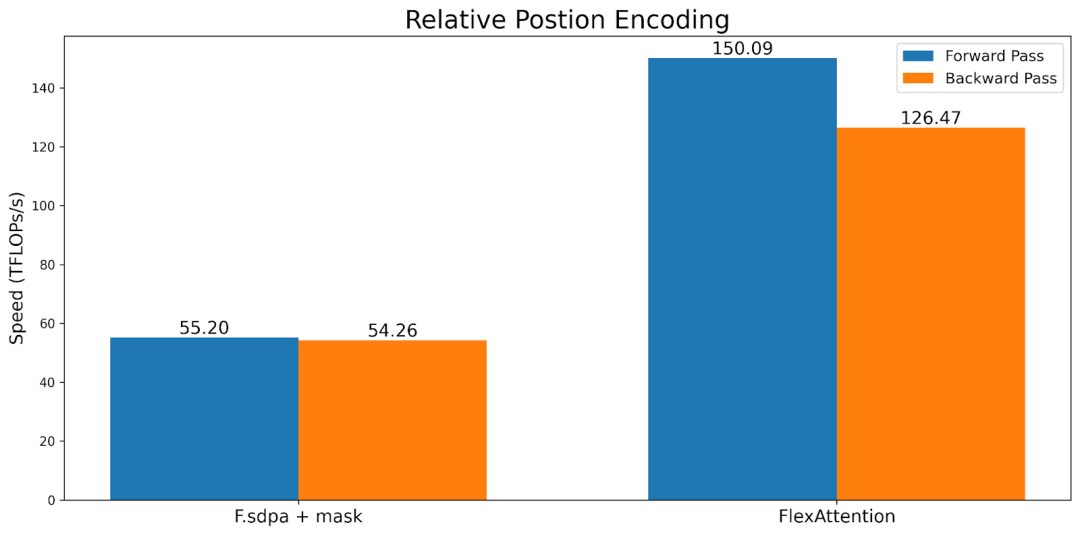
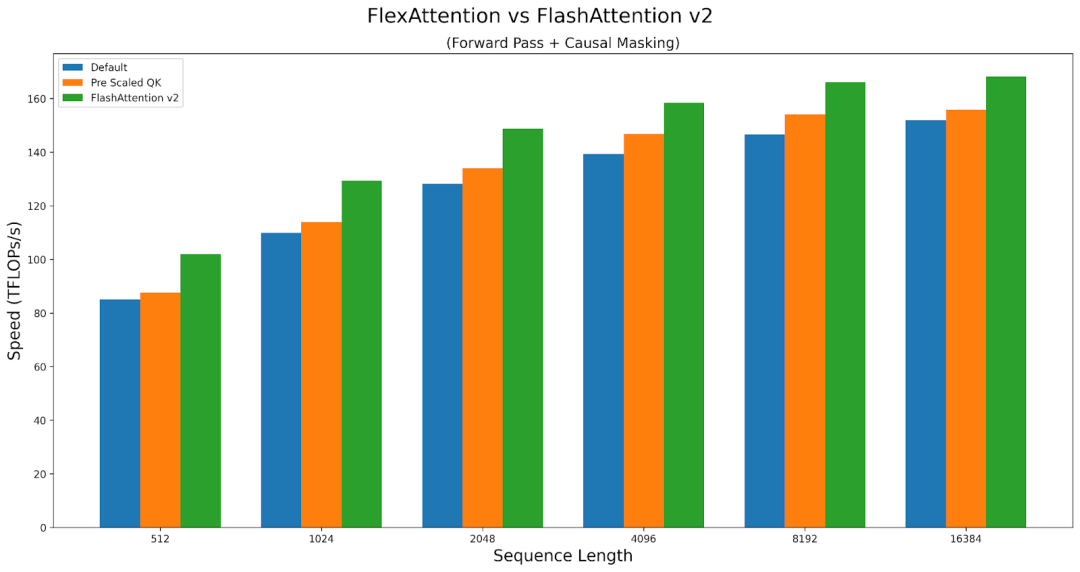
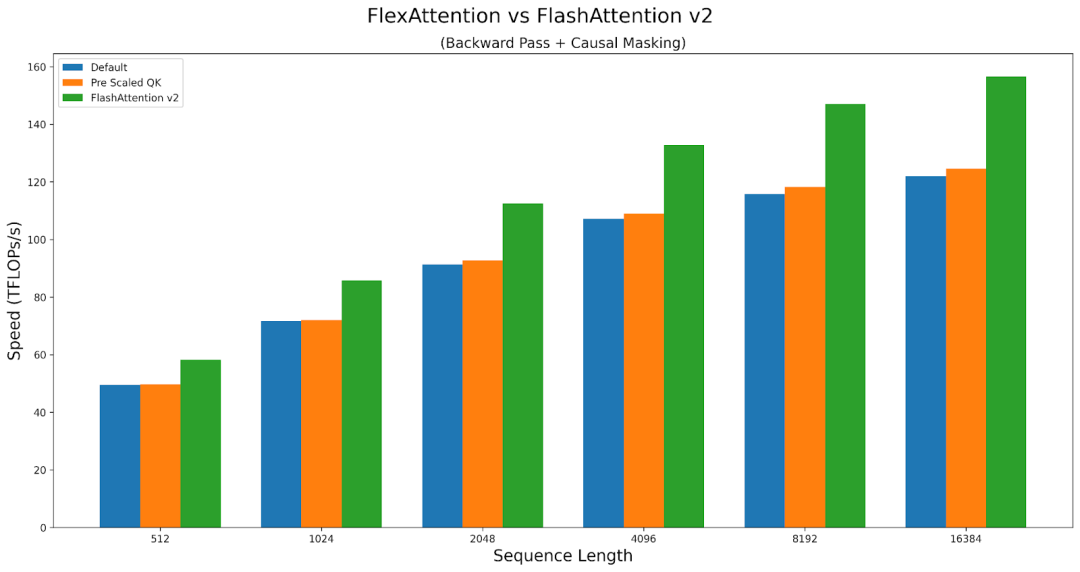
Researchers benchmarked F.scaled_dot_product_attention with a sliding window mask and FA2 with a causal mask. The results show that FlexAttention is not only significantly faster than F.scaled_dot_product_attention but also significantly faster than FA2 with a causal mask.
Performance
Overall, the performance of FlexAttention is almost as good as that of hand-written Triton kernels. However, due to the generality of FlexAttention, it suffers slight performance loss. For example, users must endure some extra latency.
FlexAttention achieves 90% of FlashAttention2 performance in forward propagation and 85% in backward propagation. FlexAttention is currently using a deterministic algorithm that recalculates more intermediates than FAv2; researchers plan to improve FlexAttention’s backward algorithm to narrow this gap!
Reference link: https://pytorch.org/blog/flexattention/
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from home and abroad. It has developed into a well-known community for machine learning and natural language processing, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing, as well as among enthusiasts.
The community can provide an open communication platform for practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.