
Big Data Digest and Baidu NLP jointly produced
Compiled by: Andy Proofread by: Baidu NLP, Long Xincheng
Original Author: Jesse Vig
Some intuitive patterns emerge in BERT’s intricate attention networks.
2018 was a turning point in the field of natural language processing, with a series of deep learning models achieving the best results on various NLP tasks such as intelligent Q&A and sentiment classification. In particular, Google’s BERT has become a “one-for-ten model,” achieving excellent performance across various tasks.
BERT is primarily based on two core concepts, both of which incorporate the latest advances in NLP: (1) Transformer architecture (2) Unsupervised learning pre-training.
The Transformer is a sequence model that discards the sequential structure of RNNs in favor of a fully attention-based approach. This is detailed in the classic paper “Attention Is All You Need.”
BERT also undergoes pre-training. Its weights are learned through two unsupervised tasks: the masked language model (MLM) and next sentence prediction.
Therefore, for each new task, BERT does not need to be trained from scratch. Instead, it can simply fine-tune the pre-trained weights. For more detailed information about BERT, please refer to “The Illustrated BERT” (previous translation link from Big Data Digest).
BERT is a Multi-Headed Monster
BERT does not use a flat attention mechanism like traditional attention models. Instead, BERT employs multi-layer attention (12 or 24 layers, depending on the model), with multiple (12 or 16) attention “heads” in each layer. Since the model weights are not shared between layers, a single BERT model can effectively contain up to 24 x 16 = 384 different attention mechanisms.
Visualizing BERT
Due to BERT’s complexity, it is challenging to intuitively understand the meaning of its internal weights. Generally speaking, deep learning models are also criticized for being black boxes. Therefore, various visualization tools have been developed to aid understanding.
However, I could not find a tool that could explain BERT’s attention patterns to tell us what it is actually learning. Fortunately, Tensor2Tensor has a great tool for visualizing attention patterns in Transformer models. I modified it for use with a PyTorch version of BERT. The modified interface is shown below. You can run it directly in this Colab notebook (https://colab.research.google.com/drive/1vlOJ1lhdujVjfH857hvYKIdKPTD9Kid8) or find the source code on GitHub (https://github.com/jessevig/bertviz).
This tool visualizes attention as different connections that link updated positions (left) with attended positions (right). Different colors represent the corresponding attention heads, while the darkness of the line color indicates the strength of attention. At the top of this small tool, users can select which layer of the model to observe and which attention head to view (by clicking on the colored blocks at the top, which represent the 12 heads).
What Does BERT Actually Learn?
I used this tool to explore the attention patterns of the pre-trained BERT model across various layers and heads (using the uncased version of the BERT-Base model). I also tried different input sentences, but for demonstration purposes, I will use the following example sentences:
Sentence A: I went to the store.
Sentence B: At the store, I bought fresh strawberries.
BERT uses the WordPiece tool for tokenization and inserts special delimiters ([CLS] to separate samples and [SEP] to separate different sentences within a sample), so the actual input sequence is: [CLS] i went to the store . [SEP] at the store , i bought fresh straw ##berries . [SEP]
In my exploration, I discovered several particularly striking attention patterns. Below are the six key patterns I identified, along with visualizations of the specific layers and heads that produce each pattern.
Pattern 1: Attention to the Next Word
In this pattern, each position primarily attends to the next word (token) in the sequence. Below is an example from layer 2, head 0 (the selected head is indicated by the highlighted color block in the top color bar).
The left image shows the attention for all words, while the right image shows the attention for a specific word (“i”). In this example, “i” focuses almost all its attention on “went,” the next word in the sequence.
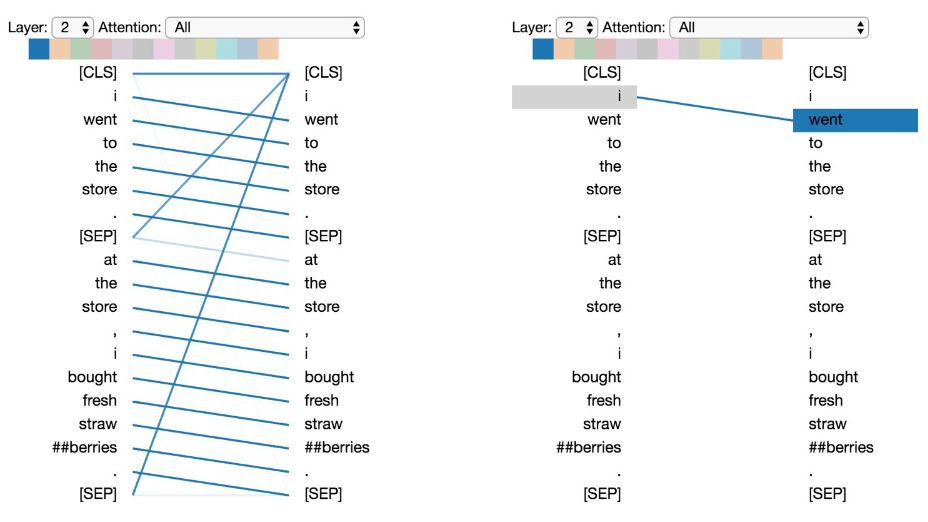
Pattern 1: Attention to the Next Word. Left: Attention of all words. Right: Attention weight of the selected word (“i”).
On the left side, it can be seen that the [SEP] symbol does not conform to this attention pattern, as most of its attention is directed towards [CLS] rather than the next word. Therefore, this pattern seems to primarily occur within each sentence.
This pattern is related to backward RNNs, where the state updates occur from right to left. Pattern 1 appears in multiple layers of the model, somewhat simulating the cyclical updates of RNNs.
Pattern 2: Attention to the Previous Word
In this pattern, most of the attention is focused on the previous word in the sentence. For example, in the image below, most of the attention for “went” is directed towards the previous word “i.”
This pattern is not as pronounced as the previous one, with some attention also dispersed to other words, particularly the [SEP] symbol. Like Pattern 1, this is somewhat similar to RNNs, but in this case, it resembles a forward RNN.
Pattern 2: Attention to the Previous Word. Left: Attention of all words. Right: Attention weight of the selected word (“went”).
Pattern 3: Attention to the Same or Related Words
This pattern attends to the same or related words, including itself. In the example below, most of the attention for the first occurrence of “store” is directed towards itself and the second occurrence of “store.” This pattern is not as pronounced as some of the others, with attention being dispersed across many different words.
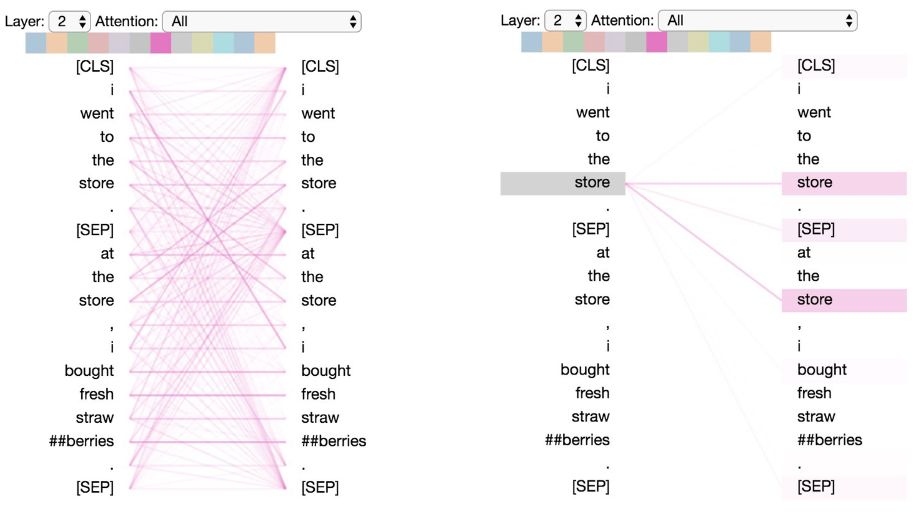
Pattern 3: Attention to Same/Related Words. Left: Attention of all words. Right: Attention weight of the selected word (“store”).
Pattern 4: Attention to Same or Related Words in Other Sentences
This pattern attends to the same or related words in another sentence. For example, in the second sentence, most of the attention for “store” is directed towards the “store” in the first sentence. This is particularly useful for the next sentence prediction task (part of BERT’s pre-training tasks), as it helps identify relationships between sentences.
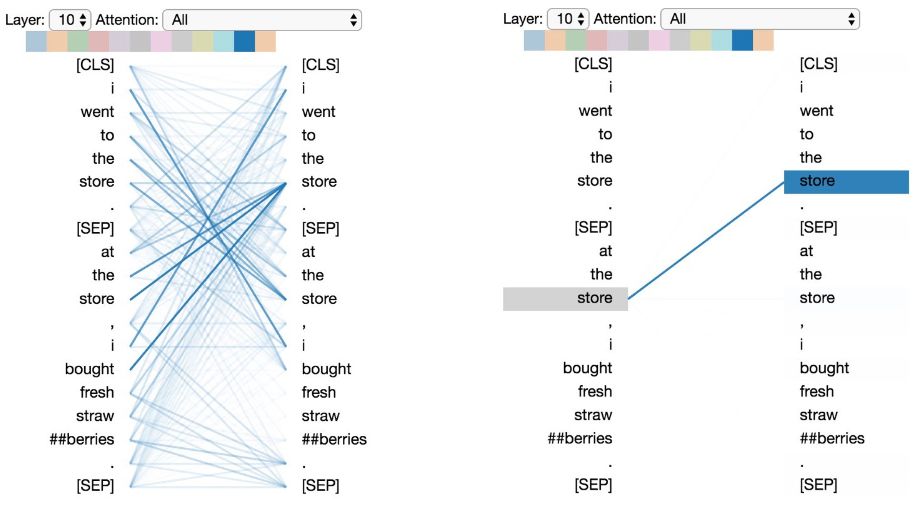
Pattern 4: Attention to Same/Related Words in Other Sentences. Left: Attention of all words. Right: Attention weight of the selected word (“store”).
Pattern 5: Attention to Other Words That Can Predict That Word
This pattern seems to pay more attention to words that can predict the target word, excluding the word itself. In the example below, most of the attention for “straw” is directed towards “##berries” (strawberries, as WordPiece separates them), and most of the attention for “##berries” is also directed towards “straw.”

Pattern 5: Attention to Other Words That Can Predict That Word. Left: Attention of all words. Right: Attention of the selected word (“## berries”).
This pattern is not as pronounced as the others. For example, most of the attention for the words is directed towards the delimiter ([CLS]), which is characteristic of the pattern 6 discussed below.
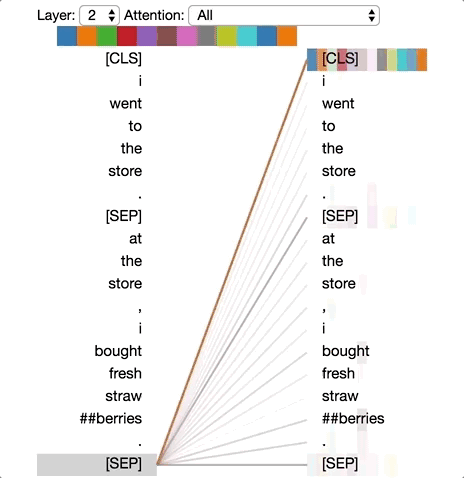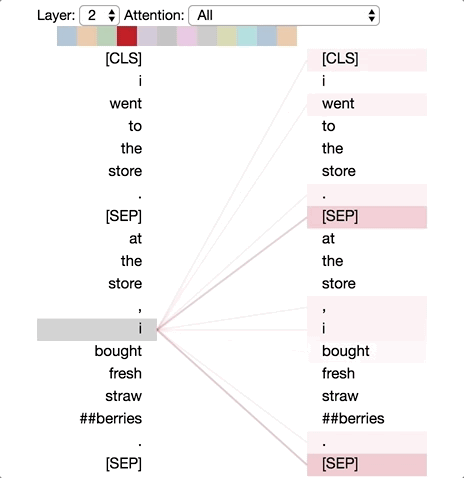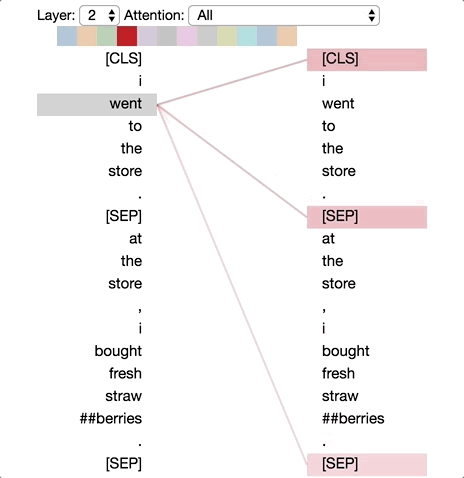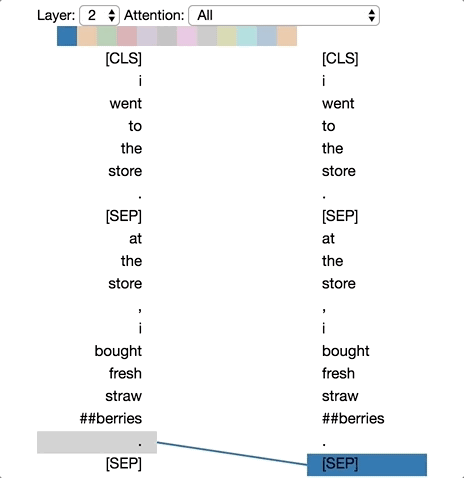
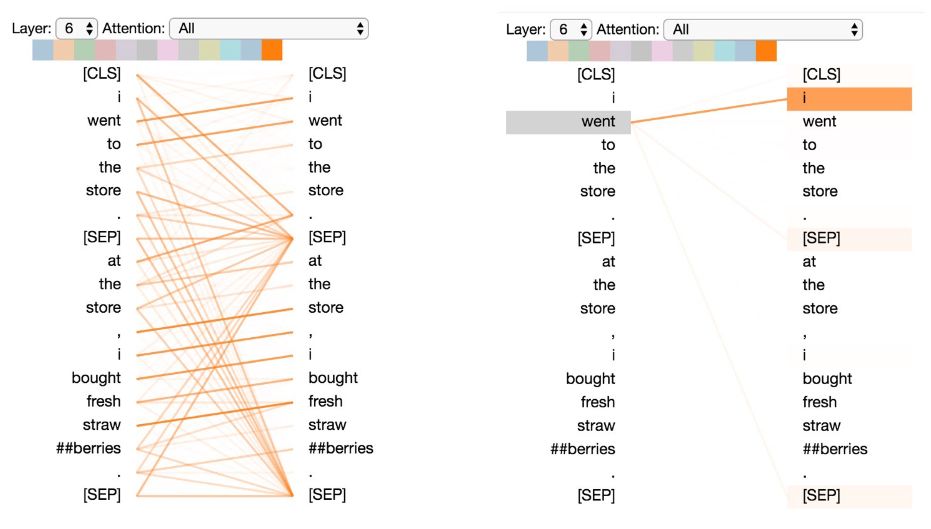
Pattern 6: Attention to Delimiters
In this pattern, most of the attention for words is directed towards the delimiters [CLS] or [SEP]. In the example below, most of the attention is directed towards the two [SEP] symbols. This may be a way for the model to propagate sentence-level states to individual words.

Pattern 6: Attention to Delimiters. Left: Attention of all words. Right: Attention weight of the selected word (“store”).
Explanation
Data visualization is somewhat like the Rorschach inkblot test (where people are asked to interpret inkblots to assess their personality): our interpretations may be influenced by our subjective beliefs and expectations. While some of the patterns above are quite pronounced, others are somewhat subjective, so these interpretations should only be considered initial observations.
Moreover, the six patterns described above only outline the rough attention structure of BERT and do not attempt to describe the linguistic patterns that attention may capture. For instance, in patterns 3 and 4, there could be many other types of “relatedness,” such as synonyms, co-reference, etc.
It would also be very interesting to see if attention heads capture different types of semantic and syntactic relationships.
PS: Many thanks to Llion Jones for developing the original Tensor2Tensor visualization tool.
Original link:
https://towardsdatascience.com/deconstructing-bert-distilling-6-patterns-from-100-million-parameters-b49113672f77

Long press to follow Baidu NLP
Understanding Language
Possessing Intelligence
Changing the World