
Source: Machine Heart
This article is about 5400 words, and it is recommended to read for more than 10 minutes.
Mamba is promising, but its development is still in the early stages.
There are many deep learning architectures, but in recent years, none have been as successful as the Transformer, which has established its dominance in multiple application areas.
A key driving force behind this success is the attention mechanism, which allows Transformer-based models to focus on the parts of the input sequence that are relevant, achieving better context understanding. However, the downside of the attention mechanism is its high computational overhead, which grows quadratically with input size, making it difficult to handle very long texts.
Fortunately, a potential new architecture has recently emerged: the Structured State Space Model (SSM). This architecture can efficiently capture complex dependencies in sequential data, making it a strong competitor to Transformers.
The design inspiration for these models comes from classical state space models – we can think of them as a fusion of Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). They can perform efficient calculations using recurrent or convolutional operations, allowing computational costs to change linearly or nearly linearly with sequence length, significantly reducing computational expenses.
Specifically, one of the most successful variants of SSM, Mamba, has modeling capabilities that can rival Transformers while maintaining linear scalability with respect to sequence length.
Mamba first introduces a simple yet effective selection mechanism that allows for the reparameterization of SSM based on the input, enabling the model to filter out irrelevant information while retaining necessary and relevant data indefinitely. Additionally, Mamba includes a hardware-aware algorithm that uses scanning instead of convolution to compute the model recurrently, achieving a 3-fold speedup on A100 GPUs.
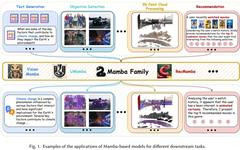
As shown in Figure 1, with its powerful ability to model complex long-sequence data and nearly linear scalability, Mamba has risen to become a foundational model and is expected to revolutionize research and application fields such as computer vision, natural language processing, and healthcare.
Consequently, the literature on researching and applying Mamba has rapidly increased, making it overwhelming. A comprehensive review report will undoubtedly be beneficial. Recently, a research team from the Hong Kong Polytechnic University published their contribution on arXiv.

-
Paper Title: A Survey of Mamba -
Paper Address: https://arxiv.org/pdf/2408.01129
This review report summarizes Mamba from multiple perspectives, helping both beginners learn the basic working mechanisms of Mamba and experienced practitioners understand the latest developments.
Mamba is a hot research direction, and as a result, multiple teams are attempting to write review reports. Besides the one introduced in this article, there are others focusing on state space models or visual Mamba. For details, please refer to the corresponding papers:
-
Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. arXiv:2404.16112 -
State space model for new-generation network alternative to transformers: A survey. arXiv:2404.09516 -
Vision Mamba: A Comprehensive Survey and Taxonomy. arXiv:2405.04404 -
A survey on vision mamba: Models, applications and challenges. arXiv:2404.18861 -
A survey on visual mamba. arXiv:2404.15956
Prerequisites
Mamba integrates the recurrent framework of Recurrent Neural Networks (RNNs), the parallel computation and attention mechanism of Transformers, and the linear characteristics of State Space Models (SSM). Therefore, to thoroughly understand Mamba, it is essential to first understand these three architectures.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have the ability to retain internal memory, making them adept at handling sequential data.
Specifically, at each discrete time step k, a standard RNN processes a vector along with the hidden state from the previous time step, then outputs another vector and updates the hidden state. This hidden state serves as the memory of the RNN, retaining information about previously seen inputs. This dynamic memory allows RNNs to handle sequences of varying lengths.
In other words, RNNs are a type of nonlinear recurrent model that can effectively capture temporal patterns by utilizing historical knowledge stored in the hidden state.
Transformer
The self-attention mechanism of Transformers helps capture global dependencies within the input. It does this by assigning weights to each position relative to the importance of other positions. More specifically, the original input undergoes a linear transformation, converting the input vector sequence x into three types of vectors: query Q, key K, and value V.
Then, normalized attention scores S are calculated, and attention weights are derived.
In addition to executing a single attention function, we can also perform multi-head attention. This allows the model to capture different types of relationships and understand the input sequence from multiple perspectives. Multi-head attention uses multiple sets of self-attention modules to process the input sequence in parallel. Each head operates independently, performing calculations similar to the standard self-attention mechanism.
Afterward, the attention weights of each head are aggregated to obtain a weighted sum of the value vectors. This aggregation step allows the model to utilize information from multiple heads and capture various patterns and relationships within the input sequence.
State Space
A State Space Model (SSM) is a traditional mathematical framework used to describe the dynamic behavior of systems over time. In recent years, SSMs have been widely applied in various fields such as control theory, robotics, and economics.
At its core, SSM captures the behavior of a system through a set of hidden variables known as “states,” allowing it to effectively capture dependencies in temporal data. Unlike RNNs, SSMs are linear models with associative properties. Specifically, classical state space models construct two key equations (state equation and observation equation) to model the relationship between the input x and output y at the current time t via an N-dimensional hidden state h(t).
-
Discretization
To meet the needs of machine learning, SSMs must undergo a discretization process—transforming continuous parameters into discrete parameters. Generally, the goal of discretization methods is to partition continuous time into K discrete intervals with as equal integral areas as possible. One of the most representative solutions adopted by SSMs to achieve this goal is Zero-Order Hold (ZOH), which assumes that the function value remains constant over the interval Δ = [𝑡_{𝑘−1}, 𝑡_𝑘]. Discrete SSMs are structurally similar to RNNs, allowing them to perform inference processes more efficiently than Transformer-based models.
-
Convolutional Computation
Discrete SSMs are linear systems with associative properties, enabling seamless integration with convolutional computations.
Relationship Between RNNs, Transformers, and SSMs
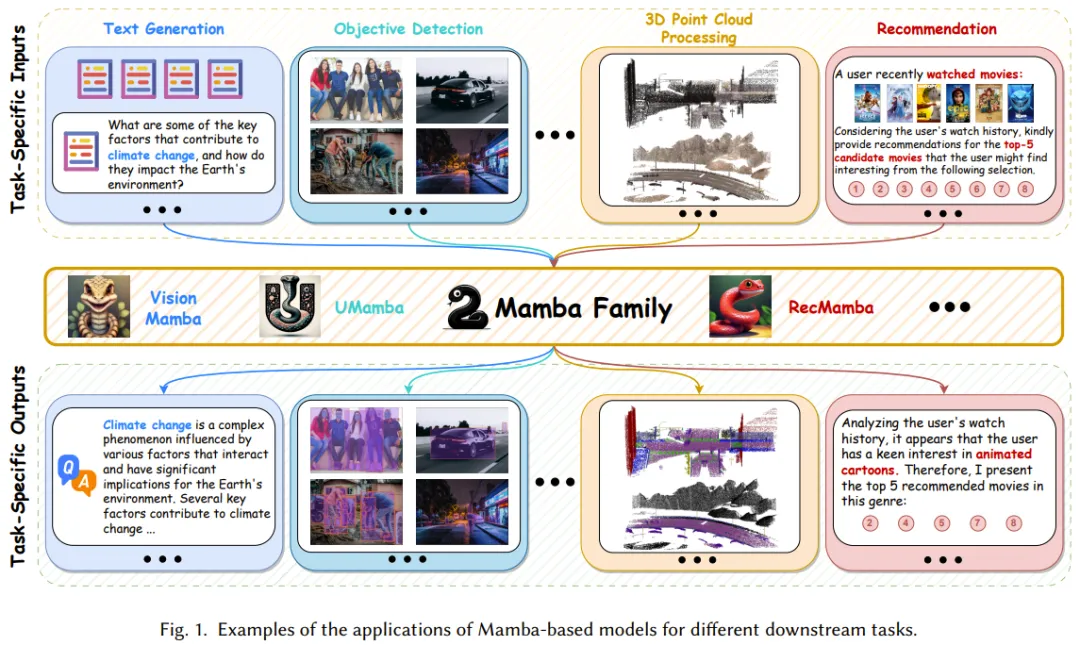
Figure 2 illustrates the computational algorithms of RNNs, Transformers, and SSMs.
On one hand, the operation of conventional RNNs is based on a nonlinear recurrent framework, where each computation relies solely on the previous hidden state and the current input.
While this form allows RNNs to quickly generate outputs during autoregressive inference, it also limits their ability to fully utilize the parallel computing capabilities of GPUs, resulting in slower model training speeds.
On the other hand, the Transformer architecture performs matrix multiplication in parallel across multiple “query-key” pairs, allowing efficient allocation of this computation to hardware resources, thus speeding up the training of attention-based models. However, generating responses or predictions with Transformer-based models can be very time-consuming during inference.
Unlike RNNs and Transformers, which support only one type of computation, discrete SSMs offer high flexibility; thanks to their linear nature, they can support both recurrent and convolutional computations. This characteristic allows SSMs to achieve efficient inference and parallel training. However, it should be noted that the most conventional SSMs are time-invariant, meaning that their A, B, C, and Δ are independent of the model input x. This limits their contextual modeling capabilities, leading to poor performance on specific tasks such as selective copying.
Mamba
To address the aforementioned shortcomings of traditional SSMs and achieve context-aware modeling, Albert Gu and Tri Dao proposed Mamba, which can serve as a general sequence backbone model, as reported in the article “Five Times Throughput, Performance Fully Surpassing Transformers: The New Architecture Mamba Ignites the AI Circle”.
Subsequently, they further proposed Mamba-2, which constructs a robust theoretical framework connecting structured SSMs with various forms of attention through Structured Space-State Duality (SSD), allowing us to transfer algorithms and system optimization techniques originally developed for Transformers to SSMs, as referenced in the report “Back to Battle with Transformers! Mamba 2, Led by the Original Authors, Has Arrived, Significantly Improving Training Efficiency”.
Mamba-1: Selective State Space Model with Hardware-Aware Algorithms
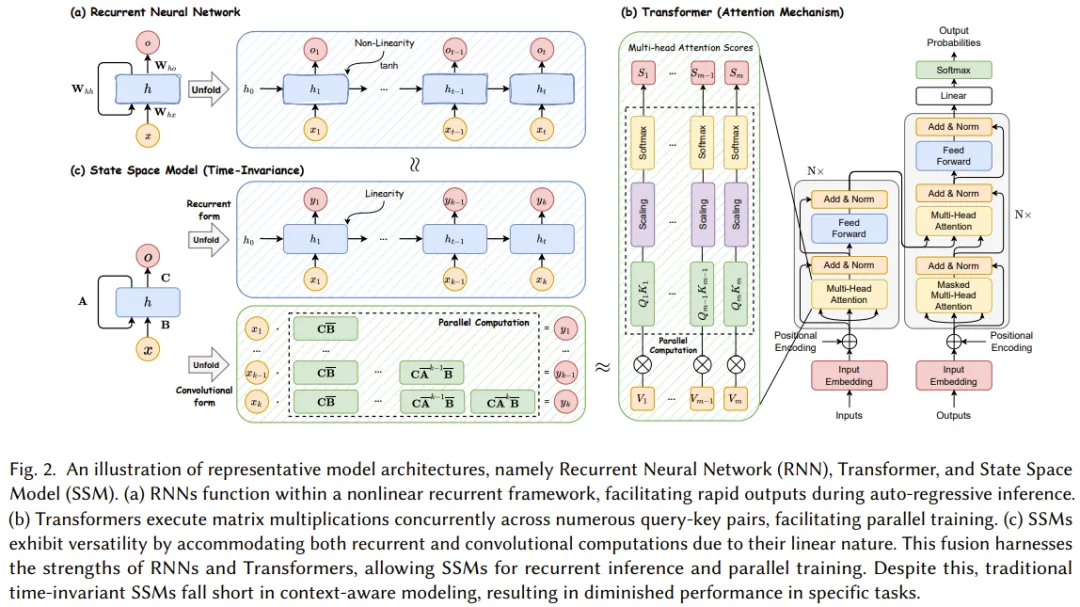
Mamba-1 introduces three major innovative techniques based on structured state space models: memory initialization based on higher-order polynomial projection operators (HiPPO), a selection mechanism, and hardware-aware computation. As shown in Figure 3, these techniques aim to enhance the long-range linear time series modeling capabilities of SSMs.
Specifically, the initialization strategy constructs a coherent hidden state matrix to effectively facilitate long-range memory.
Then, the selection mechanism equips SSMs with the ability to acquire representations of perceivable content.
Finally, to enhance training efficiency, Mamba also incorporates two hardware-aware computing algorithms: Parallel Associative Scan and Memory Recomputation.
Mamba-2: State Space Duality
The Transformer has inspired the development of various techniques, such as parameter-efficient fine-tuning, catastrophic forgetting mitigation, and model quantization. To allow state space models to benefit from these techniques originally developed for Transformers, Mamba-2 introduces a new framework: Structured State Space Duality (SSD). This framework theoretically connects SSMs with different forms of attention.
Essentially, SSD indicates that the attention mechanisms used in Transformers and the linear time-invariant systems used in SSMs can be viewed as semi-separable matrix transformations.
Moreover, Albert Gu and Tri Dao have also demonstrated that selective SSMs are equivalent to structured linear attention mechanisms implemented using a semi-separable mask matrix.
Mamba-2 designs a computation method that utilizes hardware more efficiently based on SSD, employing a block decomposition matrix multiplication algorithm.
Specifically, this matrix transformation treats the state space model as a semi-separable matrix, allowing Mamba-2 to decompose this computation into matrix blocks, where diagonal blocks represent intra-block computations, while non-diagonal blocks represent inter-block computations decomposed through the hidden states of SSMs. This method enables Mamba-2’s training speed to exceed that of Mamba-1’s parallel associative scan by 2-8 times while maintaining performance comparable to Transformers.
Mamba Blocks
Now let’s take a look at the block designs of Mamba-1 and Mamba-2. Figure 4 compares these two architectures.
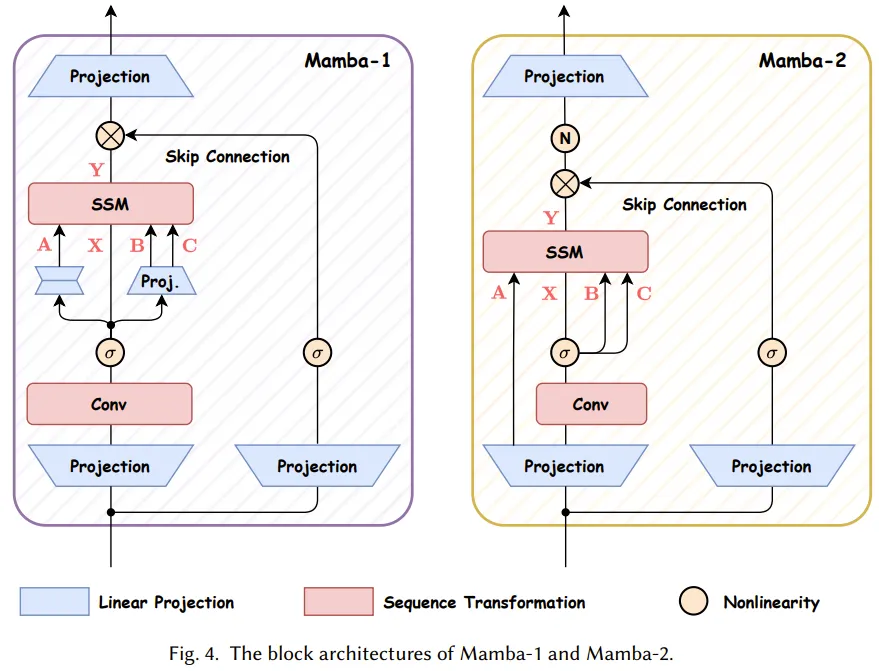
The design of Mamba-1 is centered around SSM, where the task of the selective SSM layer is to perform the mapping from the input sequence X to Y. In this design, after an initial linear projection to create X, linear projections of (A, B, C) are used. Then, the input tokens and state matrices are processed through the selective SSM unit, utilizing parallel associative scans to produce the output Y. Afterward, Mamba-1 adopts a skip connection to encourage feature reuse and mitigate the performance degradation often encountered during model training. Finally, by interleaving this module with standard normalization and residual connections, the Mamba model can be constructed.
As for Mamba-2, it introduces an SSD layer to create the mapping from [X, A, B, C] to Y. This is achieved by using a single projection at the start of the block to process [X, A, B, C] simultaneously, similar to how standard attention architectures generate Q, K, V projections in parallel.
In other words, by removing the linear projection of the sequence, the Mamba-2 block simplifies the Mamba-1 block. This allows the computation of the SSD structure to exceed that of Mamba-1’s parallel selective scan. Furthermore, to enhance training stability, Mamba-2 adds a normalization layer after the skip connection.
Progress of Mamba Models
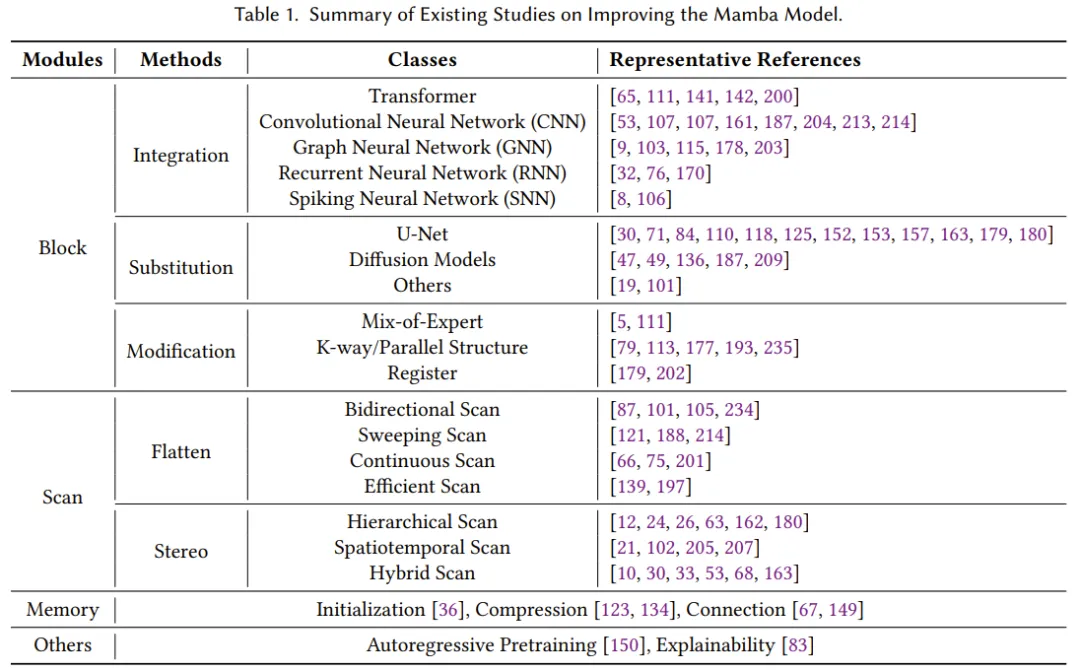
State space models and Mamba have recently developed rapidly, becoming a highly promising choice for foundational model backbone networks. Although Mamba performs well on natural language processing tasks, it still faces some challenges, such as memory loss, difficulty generalizing to different tasks, and performance on complex patterns not matching that of Transformer-based language models. To address these issues, the research community has proposed numerous improvements for the Mamba architecture. Existing research primarily focuses on modifying block designs, scanning patterns, and memory management. Table 1 categorizes and summarizes relevant studies.
Block Design
The design and structure of Mamba blocks significantly impact the overall performance of the Mamba model, making it a major research focus.
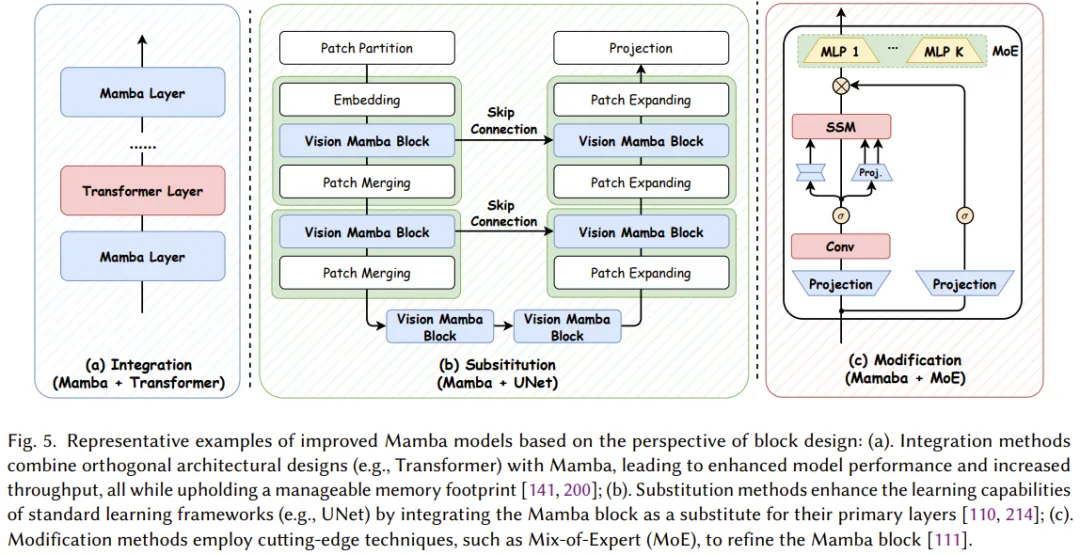
As shown in Figure 5, based on different methods of constructing new Mamba modules, existing studies can be divided into three categories:
-
Integration methods: Integrating Mamba blocks with other models to achieve a balance between performance and efficiency; -
Replacement methods: Replacing key layers in other model frameworks with Mamba blocks; -
Modification methods: Modifying components within the classic Mamba block.
Scanning Patterns
Parallel associative scanning is a key component within the Mamba model, aimed at addressing computational issues caused by the selection mechanism, improving training speed, and reducing memory requirements. This is achieved by leveraging the linear properties of time-varying SSMs to design kernel fusion and recomputation at the hardware level. However, the unidirectional sequence modeling paradigm of Mamba is not conducive to comprehensively learning diverse data such as images and videos.
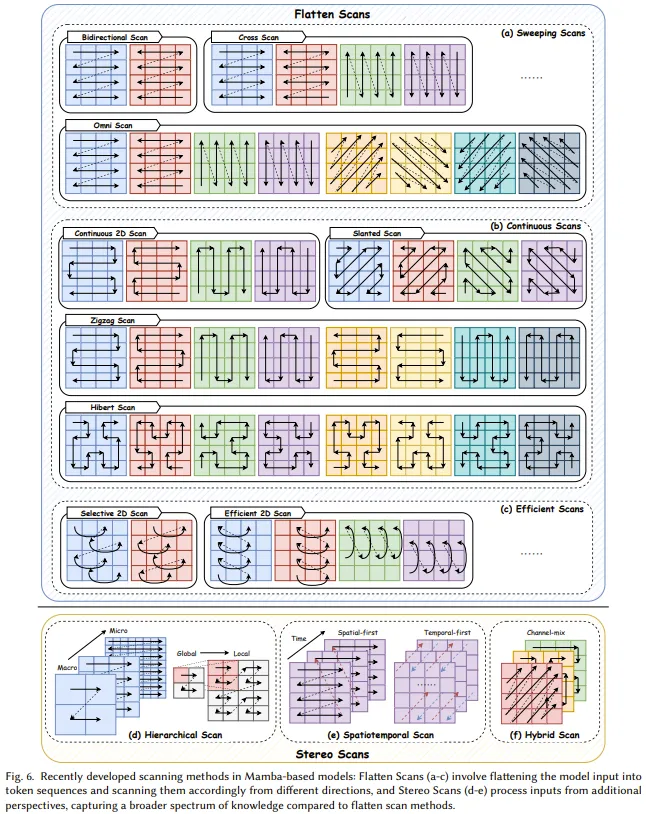
To alleviate this issue, some researchers have explored new efficient scanning methods to enhance the performance of Mamba models and facilitate their training processes. As shown in Figure 6, existing research achievements in developing scanning patterns can be divided into two categories:
-
Flattening scanning methods: Viewing the token sequence from a flattened perspective and processing the model input based on this; -
Three-dimensional scanning methods: Scanning model inputs across dimensions, channels, or scales, which can be further divided into three categories: hierarchical scanning, spatiotemporal scanning, and hybrid scanning.
Memory Management
Similar to RNNs, in state space models, the memory of the hidden state effectively stores information from previous steps, thus significantly impacting the overall performance of SSMs. Although Mamba introduces HiPPO-based methods for memory initialization, managing memory within SSM units remains challenging, including transferring hidden information before layers and achieving lossless memory compression.
To address this, some pioneering research has proposed various solutions, including memory initialization, compression, and connection.
Adapting Mamba to Diverse Data
The Mamba architecture is an extension of the selective state space model, possessing the fundamental characteristics of recurrent models, making it very suitable as a general foundational model for handling sequential data such as text, time series, and speech.
Moreover, recent pioneering research has expanded the application scenarios of the Mamba architecture, enabling it to handle not only sequential data but also images and graphs, as shown in Figure 7.
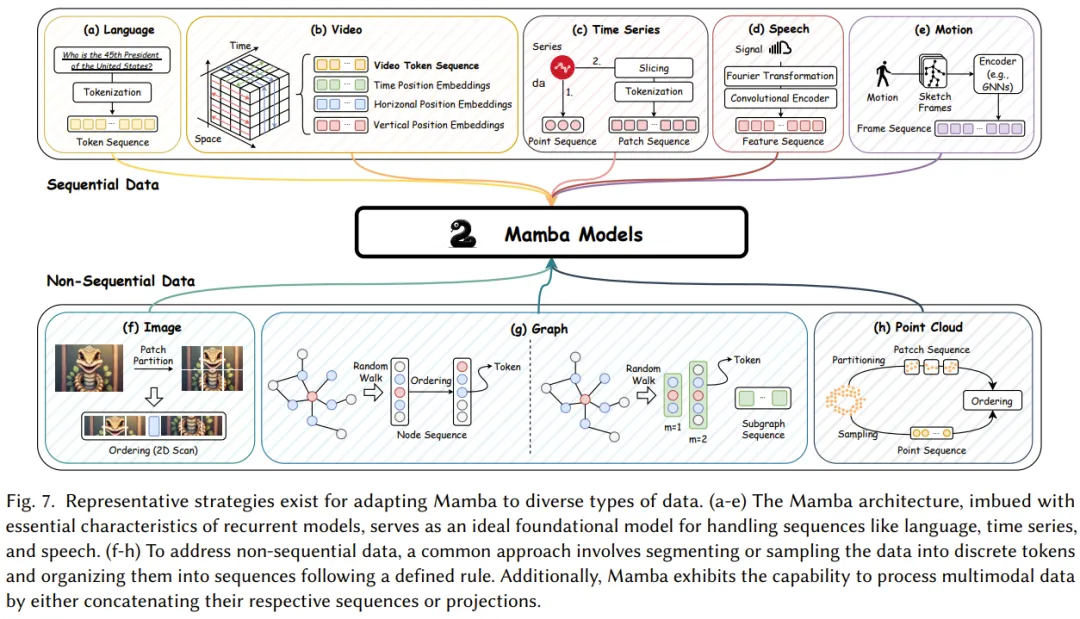
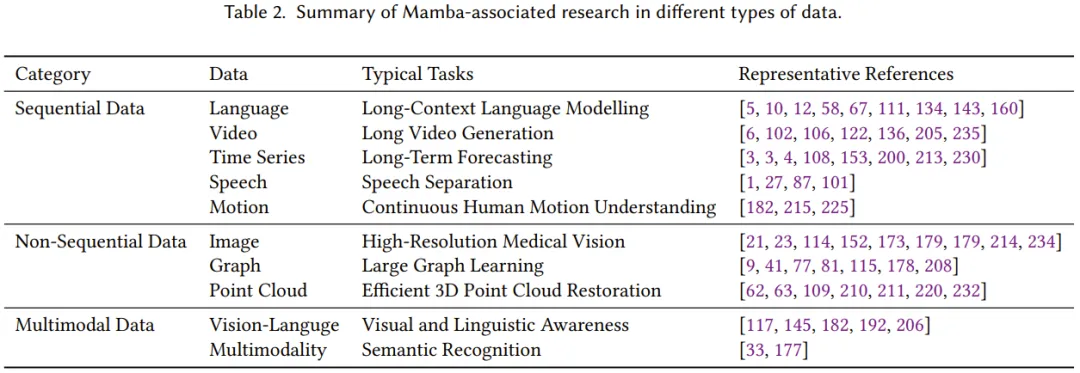
The goal of these studies is to fully leverage Mamba’s excellent ability to capture long-range dependencies while enhancing efficiency during learning and inference processes. Table 2 briefly summarizes these research achievements.
Sequential Data
Sequential data refers to data that is collected and organized in a specific order, where the order of data points is significant. This review comprehensively summarizes the applications of Mamba across various sequential data types, including natural language, video, time series, speech, and human motion data. For details, please refer to the original paper.
Non-Sequential Data
Unlike sequential data, non-sequential data does not follow a specific order. Its data points can be organized in any order without significantly affecting the meaning of the data. This lack of inherent order presents challenges for recurrent models (like RNNs and SSMs) designed to capture temporal dependencies in data.
Surprisingly, recent studies have successfully enabled Mamba (representative of SSMs) to efficiently process non-sequential data, including images, graphs, and point cloud data.
Multimodal Data
To enhance AI’s perception and scene understanding capabilities, multiple modalities of data can be integrated, such as language (sequential data) and images (non-sequential data). Such integration can provide valuable and complementary information.
Recently, multimodal large language models (MLLMs) have become a prominent research focus; these models inherit the powerful capabilities of large language models (LLMs), including strong language expression and logical reasoning abilities. Although Transformers have become the dominant method in this field, Mamba is also rising as a strong competitor, demonstrating excellent performance in aligning mixed-source data and achieving linear complexity scaling with respect to sequence length, positioning Mamba to potentially replace Transformers in multimodal learning.
Applications
Below are some notable applications of models based on Mamba. The team has categorized these applications into the following areas: natural language processing, computer vision, speech analysis, drug discovery, recommendation systems, and robotics and autonomous systems.
We will not elaborate further here; please refer to the original paper for more details.
Challenges and Opportunities
Although Mamba has achieved excellent performance in some areas, overall, Mamba research is still in its infancy, and there are still challenges to overcome. Of course, these challenges also present opportunities.
-
How to develop and improve foundational models based on Mamba; -
How to fully realize hardware-aware computing to maximize the utilization of hardware like GPUs and TPUs, enhancing model efficiency; -
How to enhance the credibility of Mamba models, which requires further research into safety and robustness, fairness, interpretability, and privacy; -
How to apply new technologies from the Transformer domain to Mamba, such as parameter-efficient fine-tuning, catastrophic forgetting mitigation, and retrieval-augmented generation (RAG).
About Us
Data派THU is a public account focused on data science, backed by the Tsinghua University Big Data Research Center, sharing cutting-edge research dynamics in data science and big data technology innovation, continuously spreading knowledge in data science, and striving to build a platform for gathering data talent, creating the strongest group of big data in China.

Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU