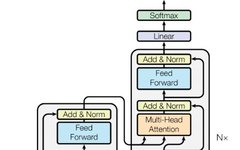
The transformer is an encoder-decoder structure used in fields such as natural language processing and computer vision. The encoder-decoder structure is a crucial part of current large models.
Encoder-decoder structure diagram:

The transformer module encodes the input to obtain features and then decodes to get the output.
A classic diagram from the transformer paper:
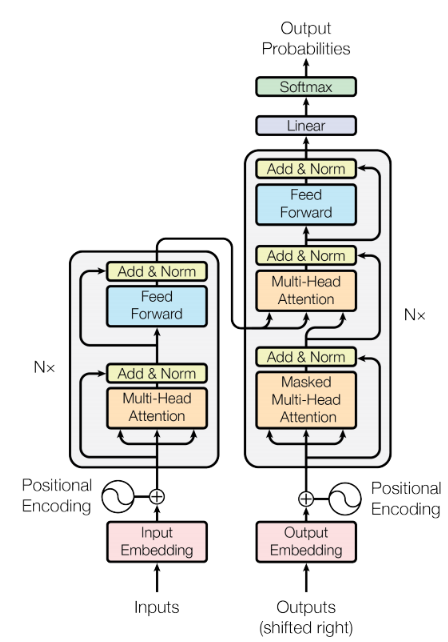
Based on the transformer paper and code, the modules mainly include:
-
Token Embedding Module (input embedding) -
Positional Encoding Module -
Multi-Head Attention Mechanism Module -
Layer Normalization Module (LayerNorm) -
Residual Module -
Feed-Forward Neural Network Module (FFN) -
Cross Multi-Head Attention Module -
Masked Multi-Head Attention Module
Next, I will introduce the above modules one by one.
1. Token Embedding Module
The token embedding module calls nn.Embedding, which mainly serves to represent each word as a vector for easier computation and processing in the next step.
class TokenEmbedding(nn.Embedding): """ Token Embedding using torch.nn they will dense representation of word using weighted matrix """ def __init__(self, vocab_size, d_model): """ class for token embedding that included positional information :param vocab_size: number of words in the dictionary :param d_model: embedding dimension """ super(TokenEmbedding, self).__init__(vocab_size, d_model, padding_idx=1)If batch_size is bs, the number of input words is seq_len, and the embedding dimension is n_model.
Thus, the input dimension x: tensor(bs,seq_len)
After TokenEmbedding(x), the dimension is: tensor(bs,seq_len,d_model)
2. Positional Encoding Module
The positional encoding module encodes each word’s position to obtain a position vector, using trigonometric functions for encoding. As shown in the figure, the left uses sine function encoding, and the right uses cosine function encoding, which are then concatenated.
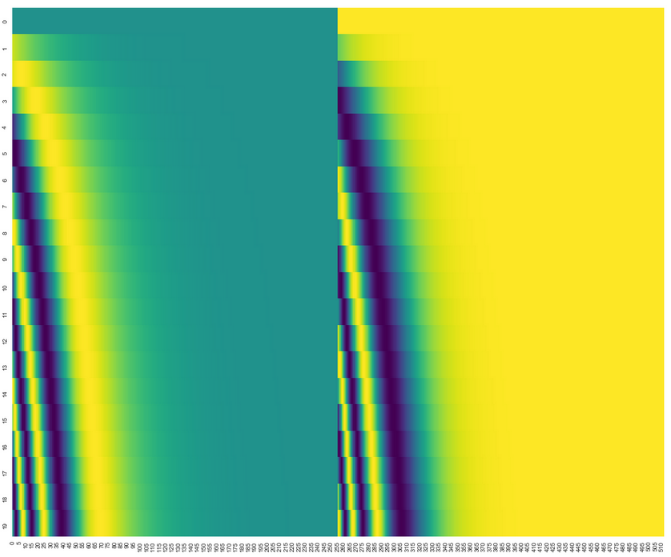
Where rows represent embedding dimensions and columns represent word positions.
Another method of positional encoding is to alternate sine and cosine functions based on position, for example, position 1 uses sin, position 2 uses cos, and so on. As shown in the figure:
If batch_size is bs, the number of input words is seq_len, and the embedding dimension is n_model.
class PositionalEncoding(nn.Module): """ compute sinusoid encoding. """ def __init__(self, d_model, max_len, device): """ constructor of sinusoid encoding class :param d_model: dimension of model, embedding dimension :param max_len: max sequence length :param device: hardware device setting """ super(PositionalEncoding, self).__init__() # same size with input matrix (for adding with input matrix) self.encoding = torch.zeros(max_len, d_model, device=device) self.encoding.requires_grad = False # we don't need to compute gradient pos = torch.arange(0, max_len, device=device) pos = pos.float().unsqueeze(dim=1) # 1D -> 2D unsqueeze to represent word's position _2i = torch.arange(0, d_model, step=2, device=device).float() # 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50]) # "step=2" means 'i' multiplied with two (same with 2 * i) # positional encoding self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model))) self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model))) # compute positional encoding to consider positional information of wordsThus, the input dimension x: tensor(bs,seq_len)
PositionalEncoding(x), the output dimension is: tensor(seq_len,d_model)
Adding the token embedding module and the positional module gives the input to the Encoder module.
Dimension representation of this process:
tensor(bs,seq_len,n_model) + tensor(seq_len,d_model) = tensor(bs,seq_len,n_model)
3. Multi-Head Attention Mechanism Module
The multi-head attention mechanism module is the core of the transformer and an important part of both the encoder and decoder.
The multi-head attention mechanism module concatenates multiple self-attention mechanisms and then passes through a fully connected layer to obtain the output. Understanding the self-attention mechanism helps in understanding the multi-head attention mechanism.
3.1 Self-Attention Mechanism Module
The self-attention mechanism module obtains the Q, K, V matrices through the WQ, WK, WV matrices. As shown in the figure:
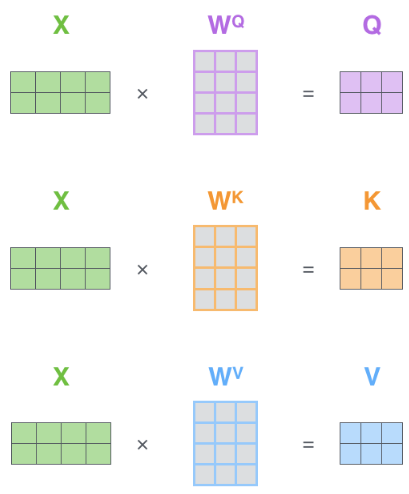
Then, the Q matrix is multiplied by the transposed K matrix to obtain the correlation coefficients between each word, which are normalized using the word embedding dimension and softmax.
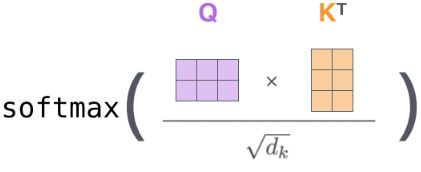
Finally, multiplying by the V matrix produces the output of the self-attention mechanism,
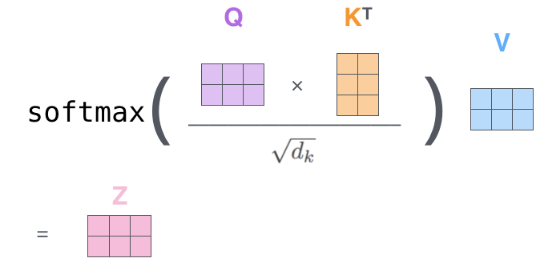
The vector dimensions representing this process:
Input x: tensor(bs,seq_len,n_model)
WQ,WK,WV: tensor(n_model,n_model)
x@WQ, x@WK, and x@WV yield Q, K, V matrices: tensor(bs,seq_len,n_model), where @ denotes matrix multiplication
Q@K^T: tensor(bs,seq_len,seq_len)
coef=softmax(Q@K^T)/sqrt(n_model): tensor(bs,seq_len,seq_len)
coef@V: tensor(bs,seq_len,n_model)
3.2 Multi-Head Attention Mechanism
The multi-head attention mechanism, as the name suggests, includes multiple self-attention mechanisms, and the outputs of these mechanisms are concatenated before being passed through a fully connected layer to obtain the final output.
As shown in the figure, input x goes through multiple self-attention mechanisms to get multiple Q, K, V.
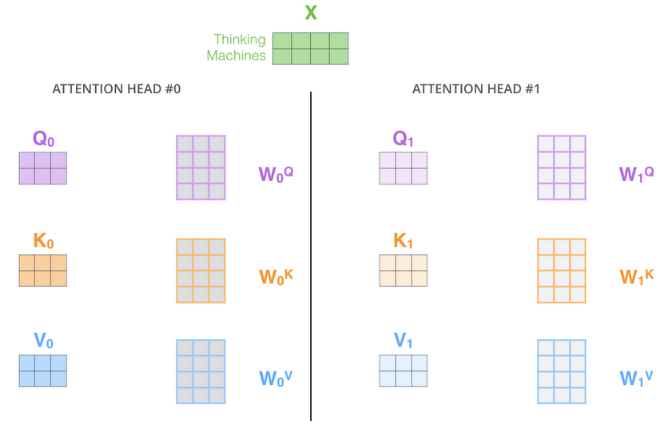
Then, as described in the previous section, multiple Z are obtained.
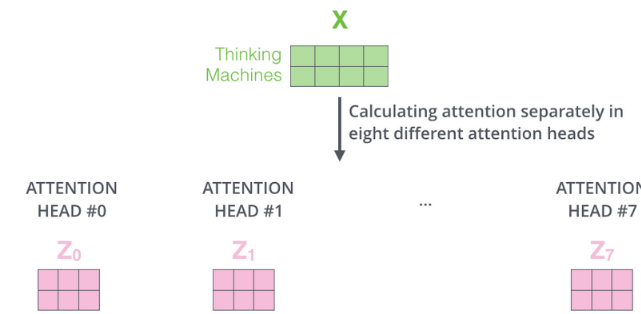
Concatenating the outputs Z of multiple attention mechanisms:

Finally, feed into the fully connected layer to obtain the final result.
The vector dimensions representing this process:
Multi-head: n_head
Input x: tensor(bs,seq_len,n_model)
Output of n_head self-attention mechanism modules: tensor(bs,seq_len,n_model)
Concatenation: (bs,seq_len,n_model*n_head)
Fully connected layer weights: tensor(n_model*n_head,n_model)
Output after feeding into the fully connected layer: tensor(bs,seq_len,n_model)
We achieve the multi-head attention mechanism module through matrix thinking, where each row of the matrix represents a word’s embedding vector, the number of rows represents the number of words, and the number of columns represents the embedding dimension.
3.3 Why Use Self-Attention Mechanism
This mechanism allows the model to automatically determine the importance of different elements in the input sequence for generating a specific output. This weight distribution method enables the model to better understand the contextual relationships within the sequence while handling order-agnostic data.
4. Layer Normalization Module
The layer normalization module is used to adjust the data range and accelerate model training. LayerNorm calculates the mean and variance of all dimensions on each sample, which allows it to be independent of the number of samples.
The vector dimensions representing this process:
x: tensor(bs,seq_len,n_model)
LayerNorm(x): tensor(bs,seq_len,n_model)
5. Residual Module
This is relatively simple; anyone familiar with deep learning should know about the ResNet network.
The vector dimensions representing this process:
x: tensor(bs,seq_len,n_model)
selfAttentions(x): tensor(bs,seq_len,n_model)
y: tensor(bs,seq_len,n_model)
LayerNorm(y): tensor(bs,seq_len,n_model)
6. Feed-Forward Neural Network Module
The FFN module improves the model’s ability to understand and represent the information of the input sequence through feature transformation and dimensional expansion, thus enhancing performance in natural language processing tasks. The module is implemented through two fully connected layers.
self.linear1 = nn.Linear(d_model, hidden)self.linear2 = nn.Linear(hidden, d_model)The vector dimensions representing this process:
Input x: tensor(bs,seq_len,n_model)
x=linear1(x): tensor(bs,seq_len,hidden)
linear2(x): tensor(bs,seq_len,n_model)
7. Cross Multi-Head Attention Module
The cross multi-head attention module is located in the red rectangle marked in the figure:
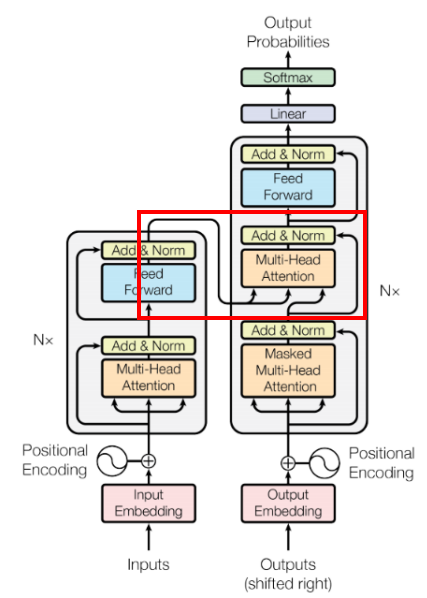
Except for the different meanings of Q, K, and V, the cross multi-head attention module is very similar to the multi-head attention mechanism. The cross attention mechanism calculates the attention between two sequences, used to handle the semantic relationships between the two sequences. In the paper, it calculates the attention between the input and output sequences, where K and V come from the input sequence, and Q comes from the output sequence. The multi-head attention mechanism calculates the attention of a single sequence, with Q, K, and V all coming from the same sequence.
The vector dimensions representing this process:
q: tensor(bs,encoder_seq_len,d_model)
v: tensor(bs,encoder_seq_len,d_model)
k: tensor(bs,decoder_seq_len,d_model)
where bs, encoder_seq_len, decoder_seq_len, and d_model respectively represent the number of samples, the length of the input sequence, the length of the output sequence, and the word embedding dimension.
x = multi_head_attention(q,k,v) # Multi-head attention module
The dimension of x: tensor(bs,decoder_seq_len,n_model)
8. Masked Multi-Head Attention Mechanism Module
The masked multi-head attention mechanism module is located in the red rectangle marked in the figure:
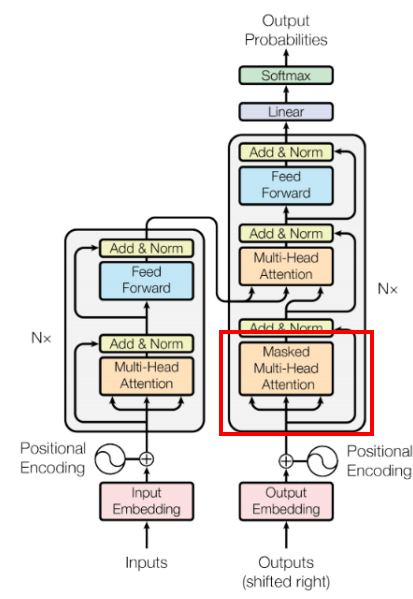
The purpose of the mask is to prevent the network from seeing content it should not see. The output sequence has a sequential relationship; during transformer inference, we output one word at a time, but doing so during training is inefficient. We still want to encompass all output words using vector thought, so we provide the target sequence to the transformer all at once, using the mask to select the word sequence for the attention mechanism calculation.
8.1 How to Implement
We only need to change the correlation coefficients after the matrix product of Q and K to implement the mask.
For example, the first word only has a vector.
Then the correlation coefficient matrix coef:
For the encoded vectors, the first two words of the word sequence have vectors, and the second word’s encoded vector is:
The first word vector:
It can be seen that the known values have changed; if they do not change, they need to be set to 0, that is:
This can be generalized to the encoding of the nth word of the sentence:
The code sets the mask to negative infinity, which becomes 0 after the softmax transformation.
Reference link: http://jalammar.github.io/illustrated-transformer/
