
Jin Chen, Contributor at Quantum Bits | WeChat Official Account QbitAI
This time, it’s not about rolling parameters or computing power, but about rolling “cross-domain learning” —
Let Stable Diffusion be the teacher, teaching multimodal large models (like Llama-3.2) how to “describe images”!
Performance skyrocketed by 30%.
The latest research by Chinese researchers in collaboration with the DeepMind team, “Lavender: Diffusion Instruction Tuning,” allows models like Llama-3.2 to achieve a 30% performance boost on multimodal question-answering tasks with just 1 day of training and 2.5% of the usual data volume, even preventing “specialization” (with a 68% improvement on out-of-distribution medical tasks).
Moreover, the code, models, and training data will all be open-sourced!
Let’s take a closer look.
Imitating Stable Diffusion’s Cross-Attention Mechanism
The current problem is:
Traditional multimodal large models (VLM) consistently fail in their “visual courses”? Data is insufficient, overfitting occurs, and details are not captured accurately… resembling a student who fails after cramming for exams.

In response, the team proposed a new solution:
Let Stable Diffusion, the “class representative for image generation,” directly share its “top student notes” — the attention distribution.
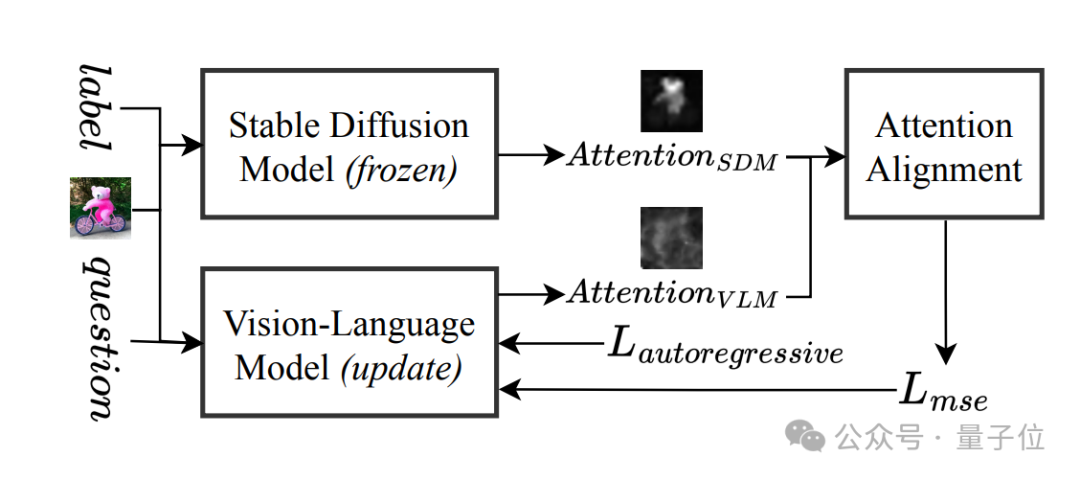
To elaborate, its cross-domain teaching can be divided into three steps:
Step 1: Apprenticeship. VLM (like Llama-3.2) learns from Stable Diffusion how to “see images” by mimicking its cross-attention mechanism through a lightweight alignment network (Aligner).
Step 2: Efficient Tutoring. Training with only 130,000 samples (2.5% of the usual data volume) on 8 GPUs for 1 day, without rolling data or burning cards.
Step 3: Anti-Specialization Techniques. Introduce LoRA technology to “lighten the load,” maintaining the original model’s capabilities while focusing on weak areas.

Now let’s look at the specific results.
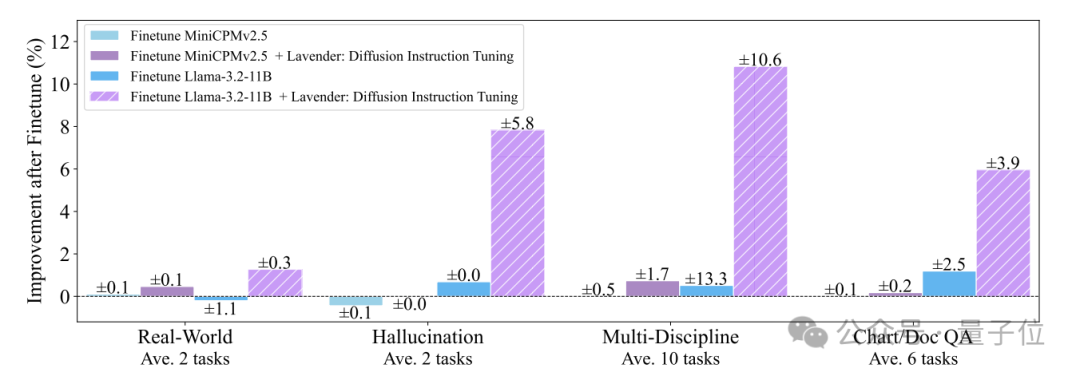
According to the results shown in the paper, the performance of Llama-3.2 after being trained with Lavender improved significantly across 16 visual-language tasks —
In the small model track with limited budget, it surpassed SOTA (the current best model) by 50%.
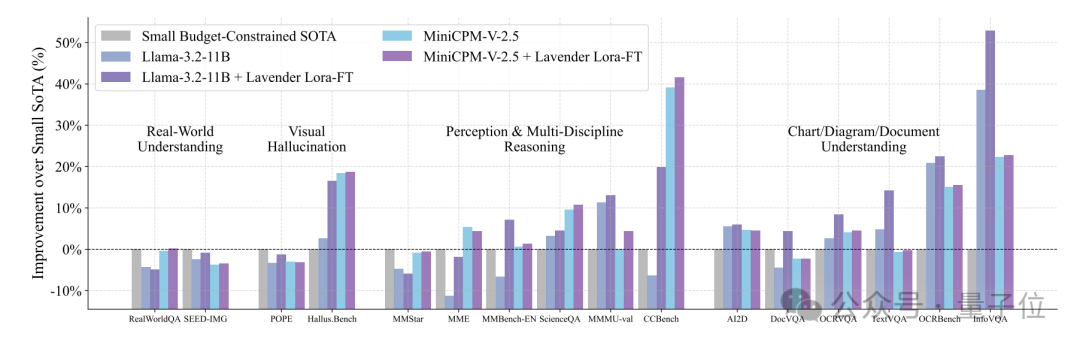
In the realm of large models, the Lavender-tuned Llama-3.2-11B can surprisingly compete with those “behemoth” SOTAs.
It is important to note that these competitors typically have sizes over ten times that of Llama-3.2.
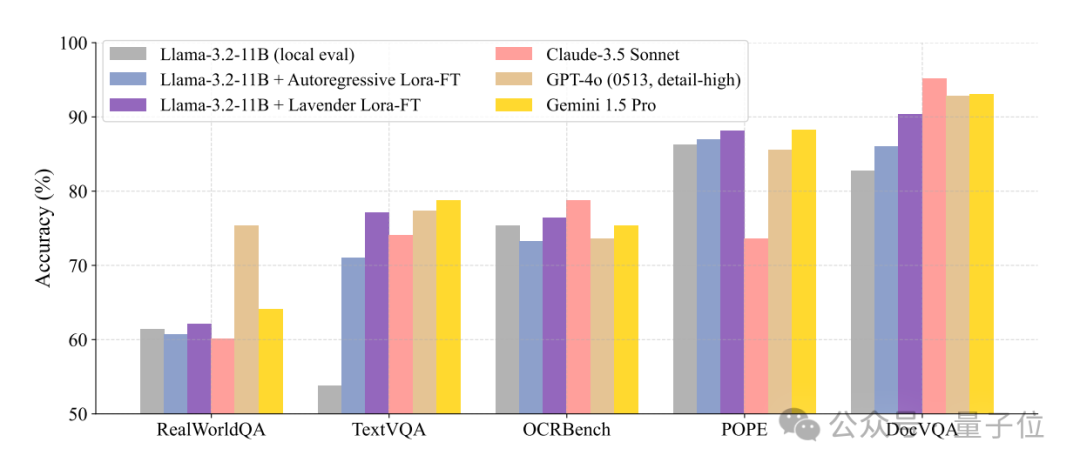
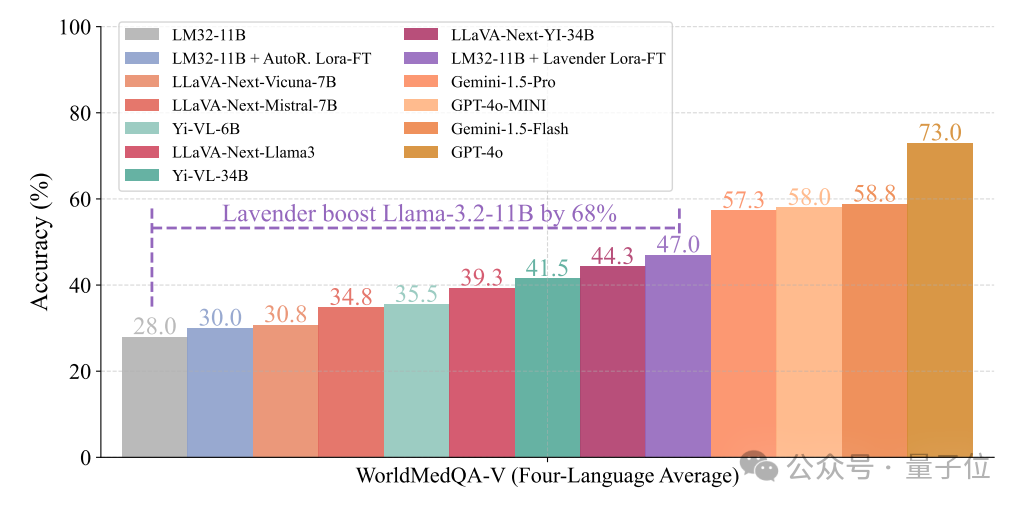
Even more surprisingly, Lavender achieved a 68% score increase in the “out-of-syllabus exam” WorldMedQA without any “extra tutoring” on medical data.
See the specific scores in the chart (the bar chart is marked).
Code/Model/Training Data Fully Open-Sourced
In summary, the main technical highlights of the new research are as follows:
1. Attention Alignment: Stable Diffusion’s “Exclusive Teaching Materials”.
The attention mechanism of traditional VLMs is like a “myopic patient,” while the attention distribution of Stable Diffusion is like a “high-definition microscope.” Lavender uses the MSE loss function to teach VLM the “focusing techniques” of Stable Diffusion, directly enhancing visual comprehension accuracy.
2. Not Enough Data? Knowledge Distillation to the Rescue.
No need for massive labeled data; directly distill visual knowledge from image generation models, making it a “small sample learning artifact.” As the paper team humorously remarks: “This is probably the AI world’s ‘one-on-one tutoring class’ with a famous teacher.”
3. Anti-Overfitting Buff: LoRA + Attention Constraints.
By locking core parameters through low-rank adaptation (LoRA), it avoids the model’s tendency to “memorize.” Experiments show that Lavender outperforms traditional SFT methods in robustness on out-of-distribution tasks, possessing an “anti-specialization constitution.”
Additionally, in terms of specific application scenarios, Lavender’s visual comprehension capabilities are maximized.
Whether it’s table titles or small data points in graphs, Lavender can quickly lock onto key information without going “off-topic”; and for complex shapes and size relationships, Lavender can also avoid visual misguidance, easily mastering them.
Experiments show that from medical lesion localization to multilingual question answering, Lavender not only sees accurately but also answers correctly, even Spanish questions pose no challenge to it.

Currently, the team has not only made the paper public but has also open-sourced the code/models/training data.
-
Training data: High-quality aligned samples labeled by Stable Diffusion;
-
Pre-trained model: Lavender adapted version based on Llama-3.2, MiniCPMv2.5 architectures;
-
Tuning guide: A practical manual for “attention alignment” from beginner to advanced;
Regarding the aforementioned research, the team leader stated:
We hope to demonstrate that efficient, lightweight model optimization has a brighter future than mindlessly stacking parameters.
Paper:https://arxiv.org/abs/2502.06814Project Homepage:https://astrazeneca.github.io/vlm/