

Author: Yang Chongyang, Harbin Institute of Technology SCIR
1. Introduction
Traditional natural language processing methods are interpretable, including rule-based methods, decision tree models, hidden Markov models, logistic regression, etc., which are also known as white-box techniques. In recent years, deep learning models using language embeddings as features (black-box techniques) have emerged, which, although significantly improving model performance in many cases, have made the models difficult to interpret. Users find it challenging to understand the processes by which data yields the desired results, leading to many issues, such as weakening the interaction between users and systems (e.g., chatbots, recommendation systems, etc.). The machine learning community’s recognition of the importance of interpretability has grown, creating an emerging field called Explainable Artificial Intelligence (XAI). There are various definitions regarding interpretability, resulting in differences in arguments in most related articles. Here, we focus on the interpretability that Explainable AI provides to users regarding how models derive results, referred to as the outcome explanation problem[1]. In Explainable AI, explanations can help users build trust in NLP-based AI systems. This article discusses the classification of interpretability based on previous reviews[2], introduces techniques that can provide explanations, and briefly describes each technique and its representative papers.
2. Classification of Explanations
Explanations can be classified in two main ways[1][3].
2.1 Local vs Global Explanations
Local explanations provide explanations for the prediction results of specific inputs, while global explanations reveal the process of how predictions are made, independent of specific inputs.
2.2 Self-Explaining vs Post-Hoc Explanations
In addition to being classified as local and global explanations, another classification method exists based on whether explanations are part of the prediction process or require post-processing of prediction results, namely self-explaining and post-hoc explanations. Self-explaining methods, also known as directly interpretable[4], use information generated during the prediction process as explanations, producing explanations simultaneously with the model’s prediction results. Decision trees and rule-based models are global self-explaining models, while methods like attention mechanisms are local self-explaining models. Post-hoc explanation methods require additional operations after providing prediction results; for example, LIME uses simple models to explain complex models, where the simple model serves as an additional operation after the complex model provides prediction results, illustrating a case of local post-hoc explanation.
Table 1 Classification of Explanations

3. Explainable Techniques
This section investigates five explainable techniques that provide explanations to users using different mechanisms.
3.1 Feature Importance
The main idea is to derive explanations by studying the extent to which different features influence the final prediction results. These methods can be built on different types of features, such as manually extracted features using feature engineering[6], lexical features like words/tokens and n-grams[7][8], or latent features learned by neural networks[9]. Attention mechanisms[10] and first-derivative saliency[11] are two widely used explainable techniques based on feature importance. Text-based features are inherently easier for humans to interpret than general features, which is why attention-based methods are widely used in NLP.
3.2 Surrogate Models
Model predictions can be explained by learning another model with interpretability as a surrogate. A very typical example is LIME[5], which uses a technique called input perturbation to learn a similar surrogate model. Surrogate model methods are model-agnostic and can be used to achieve local[12] or global[13] explanations. However, the learned surrogate model may have a completely different mechanism for making predictions than the original model, leading to skepticism about whether surrogate-based methods are faithful to the original model.
3.3 Example-Driven Explanations
This method explains the predictions of input instances by identifying and presenting other labeled instances that are semantically similar to the input instance. They are conceptually similar to nearest neighbor-based methods[14] and have been applied to various NLP tasks, such as text classification[15] and question answering[16].
3.4 Provenance-Based Explanations
This is an intuitive and effective explainability technique that shows part or all of the derivation process of predictions when the final prediction results from a series of reasoning steps. Many works in the question-answering field have adopted this explanatory approach[16][17][18].
3.5 Declarative Induction
This method directly uses human-readable and understandable representations, such as rules[19], tree structures[6], and programs[20] as explanations.
4. Operations for Implementing Explanations
4.1 First-Derivative Saliency
The size of the derivative (absolute value) indicates the sensitivity of the final result to changes in a specific dimension, i.e., the contribution of a specific dimension of that word to the final decision. The saliency score is given by the following formula:
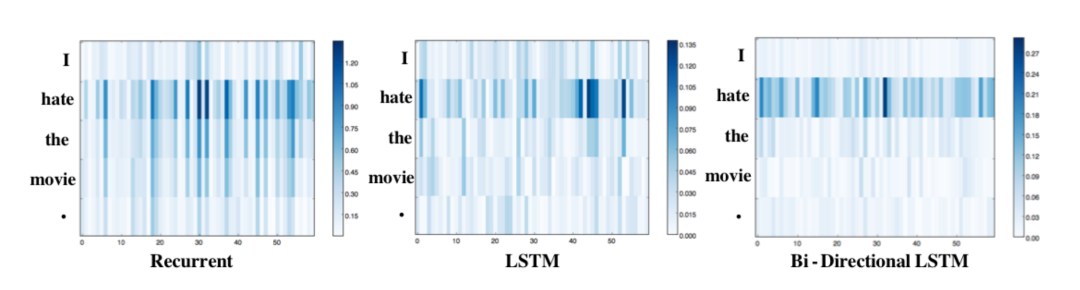
In these three models, “hate” has the highest saliency score, diminishing the influence of other tokens. LSTM focuses more clearly on “hate” than the standard recurrent model, while the bidirectional LSTM shows the most pronounced effect, with almost no influence from other words besides “hate”. This may be due to the gating mechanisms in LSTMs and Bi-LSTMs controlling the flow of information, allowing these architectures to filter out less relevant information better. Moreover, first-derivative saliency is commonly used in neural network models, as it can be calculated by simply invoking the automatic differentiation provided by deep learning engines. Recent work has also proposed improvements to first-derivative saliency[21]. As its name and definition suggest, first-derivative saliency can achieve interpretability of feature importance, especially at the token-level features.
4.2 Layer-Wise Relevance Propagation
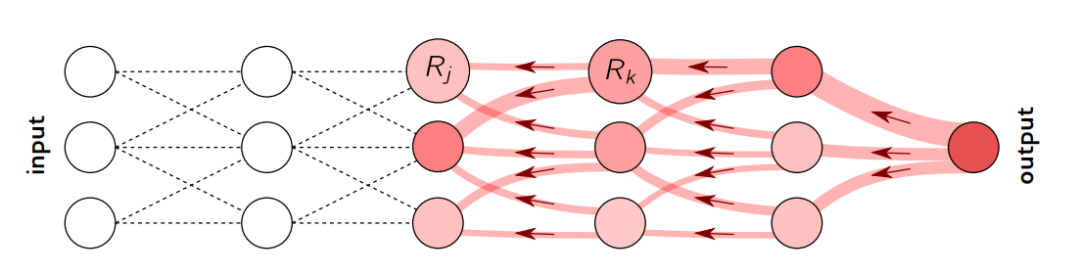
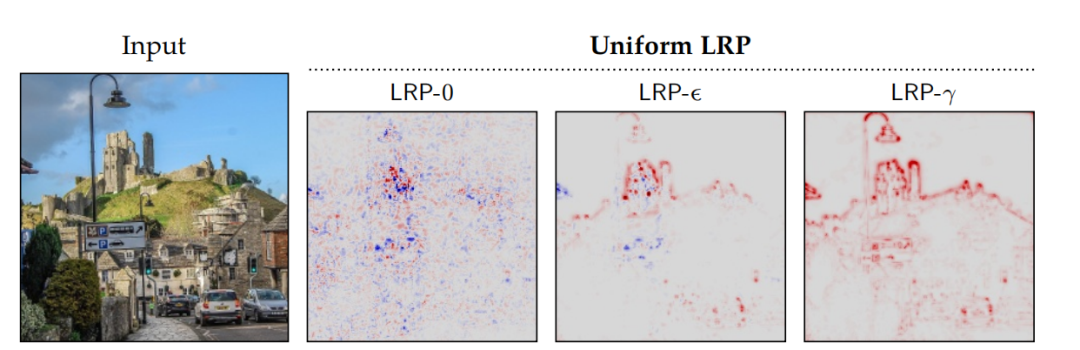
4.3 Input Perturbations
Using the LIME[5] model as an example, input perturbations can explain the output of input x by generating random perturbations of input x and training an interpretable model (usually a linear model). The main idea of LIME is to explain how the original model makes predictions by training a simpler model that simulates the original model. Therefore, a simpler model (also known as a surrogate model) can be used to explain the predictions of the original model. This method does not involve the internal mechanisms of the model but instead perturbs the input significantly and slightly (e.g., removing different words) and observes the changes in the outputs of the black-box model, then trains a simple and interpretable model based on these input-output observations. Since the surrogate model is a simple linear classifier that predicts by assigning a weight to each word, we can see the weights assigned to each word to understand how each word affects the final prediction. The final effect is shown in the following figure:
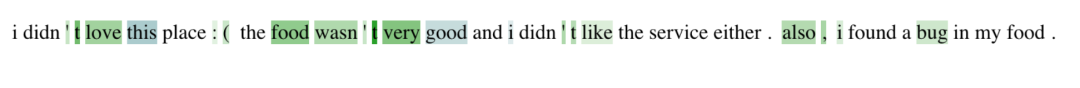
As exemplified by LIME, such operations are commonly used in surrogate models[5]12].
4.4 Attention Mechanism
The Attention mechanism [10] is one of the most commonly adopted explainable methods in the field of natural language processing, significantly enhancing model performance across a range of tasks, especially in sequence-to-sequence models based on recurrent neural network structures. The attention mechanism simulates the human behavior of focusing on certain keywords when understanding language, achieved through weight allocation. Meanwhile, previous works have introduced the attention layer into neural networks to realize interpretability of feature importance[8][9]. However, the extent to which it can achieve this is not well understood. “Attention! Is the attention mechanism interpretable?” This note discusses the interpretability of attention in detail (click the card below to view the article).
4.5 Explainability-Aware Architecture Design
This method designs neural network architectures that mimic the human problem-solving process, incorporating components that simulate human cognition, making the learned model (partially) interpretable. Such model architectures can be used to solve mathematical problems MathQA[18][20] or sentence simplification problems[24]. This design can also be applied to explainable surrogate models. For example, in MathQA, test-takers are often required to provide step-by-step explanations of how they arrived at their answers; if any key steps in the derivation are missing, the test-taker is unlikely to receive full credit. The MathQA model attempts to reproduce this derivation process using an explainable structural design. MathQA is a large dataset of multiple-choice math problems in English, with training data labeled through crowdsourcing. For a problem, annotators are asked to iteratively perform the following steps: first select an operation (addition, subtraction, multiplication, division, squaring, etc.), then label the parameters needed for that method from the problem stem or previous calculation results until the obtained set of operations can jointly yield the answer. The intended outcome in practical training is an encoder-decoder structure that treats the input problem stem as encoded data and aims to decode it into a sequence of various operations. Through this sequence, the entire solution process can be clearly understood. The instance effect is shown below:
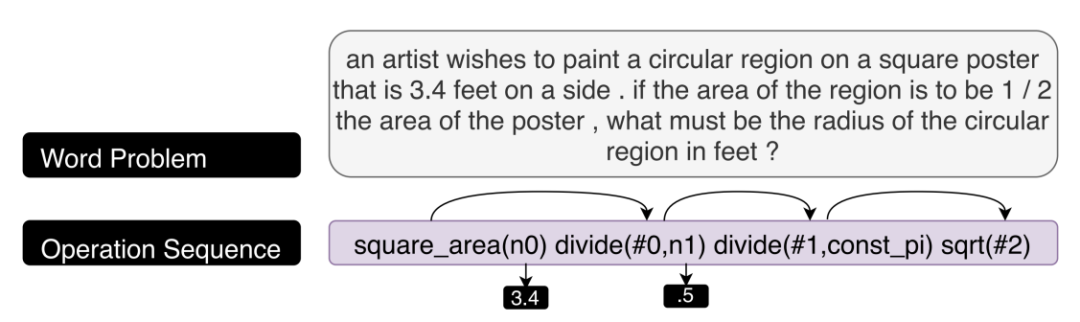
5. Conclusion
This article discusses the main classifications of explanations (local vs global explanations, self-explaining vs post-hoc explanations), common techniques for achieving explainability, and the specific operations of these explainable techniques. In addition, there are other explainability operations, such as using reinforcement learning to learn simple negation rules, etc.[19]. Explainable AI still faces many issues that need to be addressed, including clearer definitions of related concepts in the field, a more explicit understanding of interpretability, and how to establish connections with goals. We look forward to more work in the future to improve this field and promote interaction between users and AI.
References
Guidotti R, Monreale A, Ruggieri S, et al. A Survey of Methods for Explaining Black Box Models[J]. ACM Comput. Surv., New York, NY, USA: Association for Computing Machinery, 2018, 51(5).
[2]Danilevsky M, Qian K, Aharonov R, et al. A Survey of the State of Explainable AI for Natural Language Processing[J]. 2020(Section 5).
[3]Tjoa E, Guan C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020: 1–21.
[4]Arya V, Bellamy R K E, Chen P-Y,et al. One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques[J]. 2019.
[5]Ribeiro M T, Singh S, Guestrin C. “Why should I trust you?” Explaining the predictions of any classifier[A]. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining[C]. 2016: 1135–1144.
[6]Voskarides N, Meij E, Tsagkias M, et al. Learning to explain entity relationships in knowledge graphs[J]. ACL-IJCNLP 2015 – 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Proceedings of the Conference, 2015, 1: 564–574.
[7]Godin F, Demuynck K, Dambre J, et al. Explaining Character-Aware Neural Networks for Word-Level Prediction: Do They Discover Linguistic Rules?[J]. 2018.
[8]Mullenbach J, Wiegreffe S, Duke J, et al. Explainable Prediction of Medical Codes from Clinical Text[J]. 2018.
[9]Xie Q, Ma X, Dai Z, et al. An Interpretable Knowledge Transfer Model for Knowledge Base Completion[J]. 2017.
[10]Bahdanau D, Cho K H, Bengio Y. Neural machine translation by jointly learning to align and translate[A]. 3rd International Conference on Learning Representations, ICLR 2015[C]. 2015.
[11]Li J, Chen X, Hovy E H, et al. Visualizing and Understanding Neural Models in NLP[A]. HLT-NAACL[C]. 2016.
[12]Alvarez-Melis D, Jaakkola T. A causal framework for explaining the predictions of black-box sequence-to-sequence models[A]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing[C]. 2017: 412–421.
[13]Liu N, Huang X, Li J, et al. On interpretation of network embedding via taxonomy induction[A]. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining[C]. 2018: 1812–1820.
[14]Dudani S A. The distance-weighted k-nearest-neighbor rule[J]. IEEE Transactions on Systems, Man, and Cybernetics, IEEE, 1976(4): 325–327.
[15]Croce D, Rossini D, Basili R. Auditing deep learning processes through kernel-based explanatory models[A]. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)[C]. 2019: 4028–4037.
[16]Abujabal A, Roy R S, Yahya M, et al. Quint: Interpretable question answering over knowledge bases[A]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations[C]. 2017: 61–66.
[17]Zhou M, Huang M, Zhu X. An interpretable reasoning network for multi-relation question answering[J]. arXiv preprint arXiv:1801.04726, 2018.
[18]Amini A, Gabriel S, Lin S, et al. MathQA: Towards interpretable math word problem solving with operation-based formalisms[J]. arXiv, 2019: 2357–2367.
[19]Pröllochs N, Feuerriegel S, Neumann D. Learning interpretable negation rules via weak supervision at document level: A reinforcement learning approach[A]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies[C]. Association for Computational Linguistics, 2019, 1: 407–413.
[20]Ling W, Yogatama D, Dyer C, et al. Program induction by rationale generation: Learning to solve and explain algebraic word problems[J]. arXiv preprint arXiv:1705.04146, 2017.
[21]Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks[A]. International Conference on Machine Learning[C]. PMLR, 2017: 3319–3328.
[22]Poerner N, Roth B, Schütze H. Evaluating neural network explanation methods using hybrid documents and morphological agreement[J]. arXiv e-prints, 2018: arXiv-1801.
[23]Croce D, Rossini D, Basili R. Explaining non-linear classifier decisions within kernel-based deep architectures[A]. Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP[C]. 2018: 16–24.
[24]Dong Y, Li Z, Rezagholizadeh M, et al. EditNTS: An Neural Programmer-Interpreter Model for Sentence Simplification through Explicit Editing[A]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics[C]. 2019: 3393–3402.
Recommended Reading:
Overview of Causal Inference and Basic Method Introduction (Part One)
Overview of Causal Inference and Basic Method Introduction (Part Two)
Research Progress on Multi-label Text Classification
Click the card below to follow the official account “Machine Learning Algorithms and Natural Language Processing” for more information: