Click the above “Visual Learning for Beginners” and choose to add a “Star” or “Top”
Important content delivered first time
The Attention mechanism has become one of the most important concepts in natural language processing in recent years, widely applied across various subfields of NLP. Models like Transformer, BERT, and GPT, which are centered around the attention mechanism, have continuously topped benchmarks in various tasks. Among them, Luong Attention and Bahdanau Attention are the two most classic attention mechanisms. While they are conceptually similar, they have many differences in implementation details.
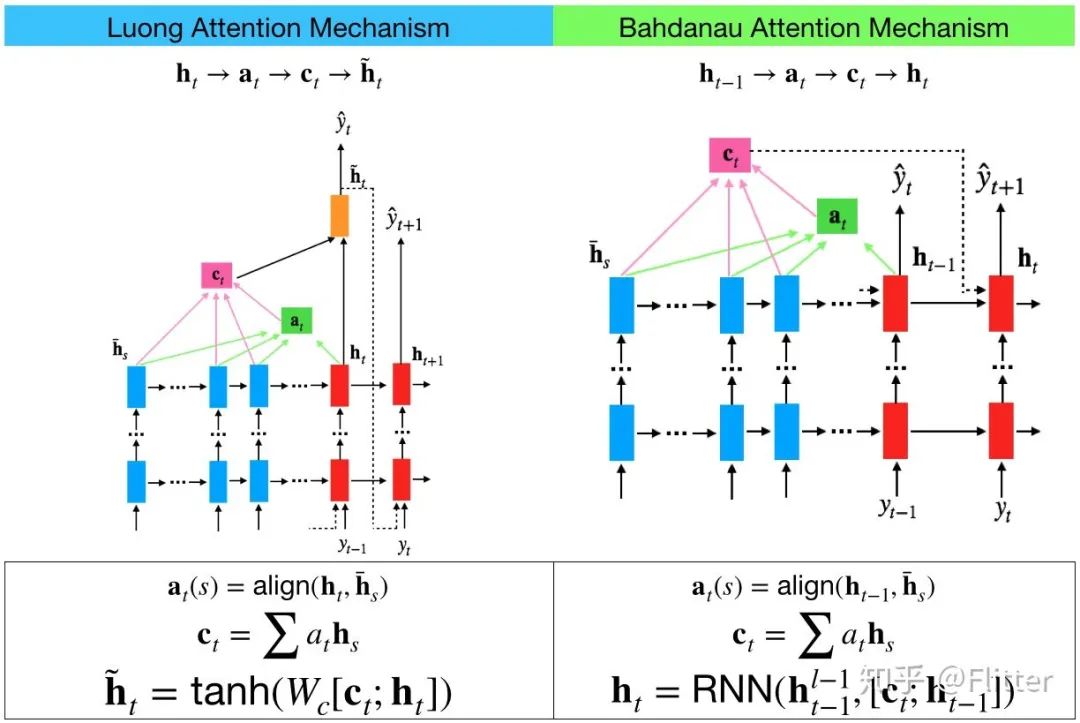
In simple terms, the main differences between Luong Attention and Bahdanau Attention are as follows:
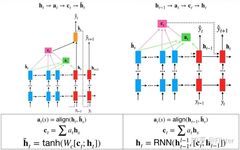
1. Different methods of calculating attention In the Luong Attention mechanism, the attention  at step t is calculated by weighting the hidden state
at step t is calculated by weighting the hidden state  of the decoder at step t with each hidden state
of the decoder at step t with each hidden state  in the encoder. In the Bahdanau Attention mechanism, the attention
in the encoder. In the Bahdanau Attention mechanism, the attention  at step t is calculated by weighting the hidden state
at step t is calculated by weighting the hidden state  of the decoder at step t-1 with each hidden state
of the decoder at step t-1 with each hidden state  in the encoder.
in the encoder.
 and the hidden state
and the hidden state  from the previous step, resulting in the hidden state
from the previous step, resulting in the hidden state  for step t, which is then directly outputted
for step t, which is then directly outputted  . In contrast, the Luong Attention mechanism establishes an additional network structure in the decoder, concatenating the attention
. In contrast, the Luong Attention mechanism establishes an additional network structure in the decoder, concatenating the attention  with the original hidden state of the decoder at step t to get the hidden state
with the original hidden state of the decoder at step t to get the hidden state  and output
and output  .
.
To summarize, the computation flow of the Bahdanau Attention mechanism is  , while the computation flow of the Luong attention mechanism is
, while the computation flow of the Luong attention mechanism is  . Comparatively, the decoder in the Luong attention mechanism uses the current step’s (rather than the previous step’s) hidden state to compute attention, which is logically more natural but requires an additional RNN decoder layer to compute the output.
. Comparatively, the decoder in the Luong attention mechanism uses the current step’s (rather than the previous step’s) hidden state to compute attention, which is logically more natural but requires an additional RNN decoder layer to compute the output.
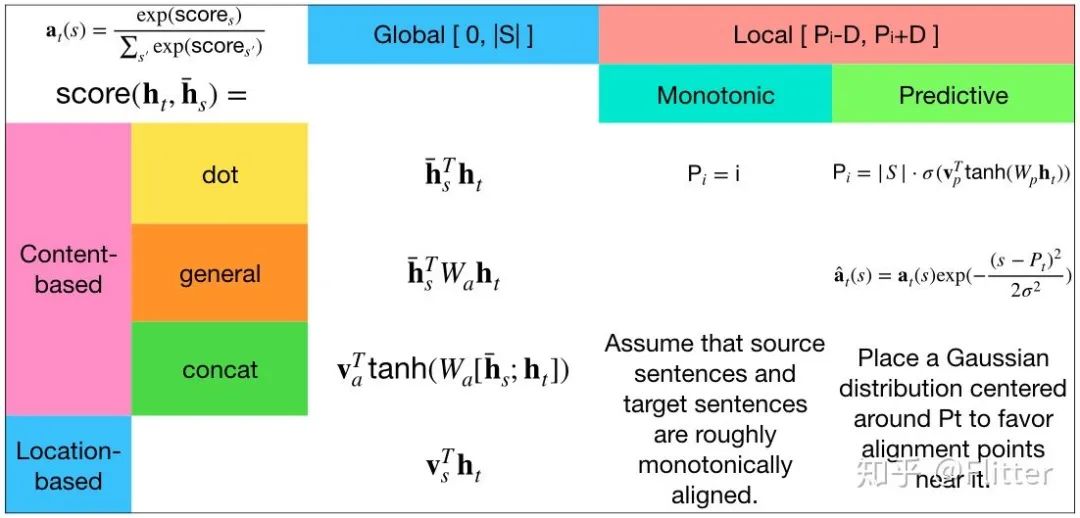
Additionally, the Bahdanau Attention paper only attempted to use concat as an alignment function, while the Luong Attention paper experimented with various alignment functions.
Based on the size of the computation area, alignment functions can be divided into global attention and local attention mechanisms. The global attention mode computes attention for each hidden state at each step of the encoder, while the local attention mode computes attention for a subset of hidden states.
Based on the information used, alignment can be divided into content-based alignment and position-based alignment. The former considers both the encoder’s hidden state  and the current step’s decoder hidden state
and the current step’s decoder hidden state  , while the latter only considers the current step’s decoder hidden state
, while the latter only considers the current step’s decoder hidden state  .
.
Reference Links
1. Neural Machine Translation by Jointly Learning to Align and Translate: https://arxiv.org/abs/1409.0473
2. Effective Approaches to Attention-based Neural Machine Translation: https://arxiv.org/abs/1508.04025
3. Attention Variants: http://cnyah.com/2017/08/01/attention-variants/
4. Introduction to Bahdanau Attention and Luong Attention Mechanisms – CSDN Blog: https://blog.csdn.net/u010960155/article/details/82853632
5. Wu Wenxing: Two Attention Mechanisms in seq2seq (Figures + Formulas): https://zhuanlan.zhihu.com/p/70905983
Good News!
Visual Learning for Beginners Knowledge Circle
Is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply “Extension Module Chinese Tutorial” in the backend of the “Visual Learning for Beginners” public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Projects 52 Lectures
Reply “Python Visual Practical Projects” in the backend of the “Visual Learning for Beginners” public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply “OpenCV Practical Projects 20 Lectures” in the backend of the “Visual Learning for Beginners” public account to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please follow the format; otherwise, you will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed. Thank you for your understanding~