Transformers Mimic Brain Functionality and Outperform 42 Models

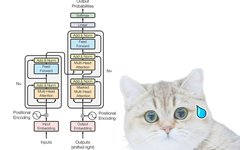
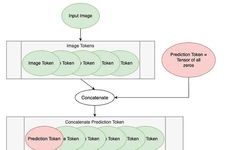
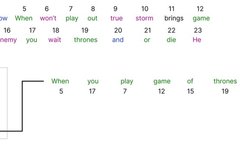
Follow our official account to discover the beauty of CV technology This article is reprinted from Quantum Bit. Pine from Aofeisi Quantum Bit | Official Account QbitAI Many AI application models today cannot avoid mentioning one model structure: Transformer. It abandons traditional CNN and RNN structures, consisting entirely of the Attention mechanism. Transformers not only … Read more