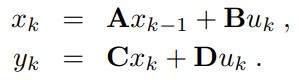Follow the public account to discover the beauty of CV technology
This article is reprinted from Machine Heart, edited by Panda W.Transformers are powerful but not perfect, especially when dealing with long sequences. State Space Models (SSMs) perform quite well on long sequences. Researchers proposed last year that SSMs could replace Transformers, as seen in the article “Pre-training Without Attention, Scaling to 4096 Tokens is No Problem, Comparable to BERT”. Recently, the Mamba based on the SSM method has emerged, achieving an inference throughput five times that of Transformers, as referenced in “Five Times Throughput, Performance Fully Surrounds Transformer: New Architecture Mamba Explodes in the AI Circle”.However, SSMs and Transformers are not mutually exclusive architectures; they can be combined!A recently published NeurIPS 2023 paper, “Block-State Transformers,” adopts this approach, supporting ultra-long inputs of 65k tokens effortlessly while maintaining high computational efficiency, with speeds potentially ten times faster than Transformers using recurrent units! This paper was also praised by Mamba author Tri Dao, who stated: “SSMs and Transformers seem to complement each other.”
Before introducing this new method, let’s briefly discuss Transformers. Transformers have performed exceptionally well on many different Natural Language Processing (NLP) tasks. It can be said that Transformers have largely replaced Recurrent Neural Networks (RNNs). Moreover, they are making significant strides in fields beyond NLP, such as images and videos.There are many reasons for their success, including computational efficiency and architectural inductive bias, which make them highly suitable for large-scale training on natural language tasks. In terms of computation, Transformers can process input sequences’ tokens in parallel, allowing them to fully utilize modern accelerator hardware. Additionally, the attention mechanism enables Transformers to find relationships between longer sequences by reading all information extracted from past tokens when inferring the next token. Compared to RNNs and LSTMs, self-attention has two advantages: (1) the ability to store information and use that information directly as context is greatly enhanced, and (2) training on longer sequences can be more stable.Despite many advantages over RNNs, Transformers still encounter issues when scaling input sequence lengths, related to computational performance and quality. Furthermore, the runtime of Transformers grows quadratically with the increase in input sequence length, which raises the cost of training these models.Additionally, it is well known that attention-based Transformers perform poorly on long input classification tasks. The basic Transformer may be unstable when trained on long sequences, and the importance of tokens is focused on a local receptive field of about 50 tokens around the current time step.Recently, increasing research has shown that State Space Models (SSMs) can replace Transformers, as SSMs can capture dependencies in extremely long sequences while offering higher computational efficiency and better parallelization capabilities.Although SSMs are still autoregressive sequence models, their underlying linear time-invariant dynamic systems can efficiently process sequences using FFT-based parallelizable convolution operators, with a complexity of only 𝒪(𝐿 log 𝐿), where 𝐿 is the length of the sequence. Moreover, by borrowing online function approximation methods and deriving recurrent update rules, it can ensure the retention of past information over long sequences, even reaching thousands of time steps. On the Long-Range Arena benchmark, SSMs even outperform Transformers significantly, as reported in Machine Heart’s article “Six Tasks, Multiple Data Types, Google and DeepMind Propose Efficient Transformer Evaluation Benchmark”.While SSMs have been very successful in long-range classification tasks, they still do not match Transformers as ready-to-use sequence models for general language modeling.Recent research, “Long Range Language Modeling via Gated State Spaces,” suggests that Transformers and SSMs can completely complement each other.The new architecture Block-State Transformer (BST) proposed by institutions like DeepMind combines the strong inductive bias of local attention with long-term context modeling capabilities into a single layer.
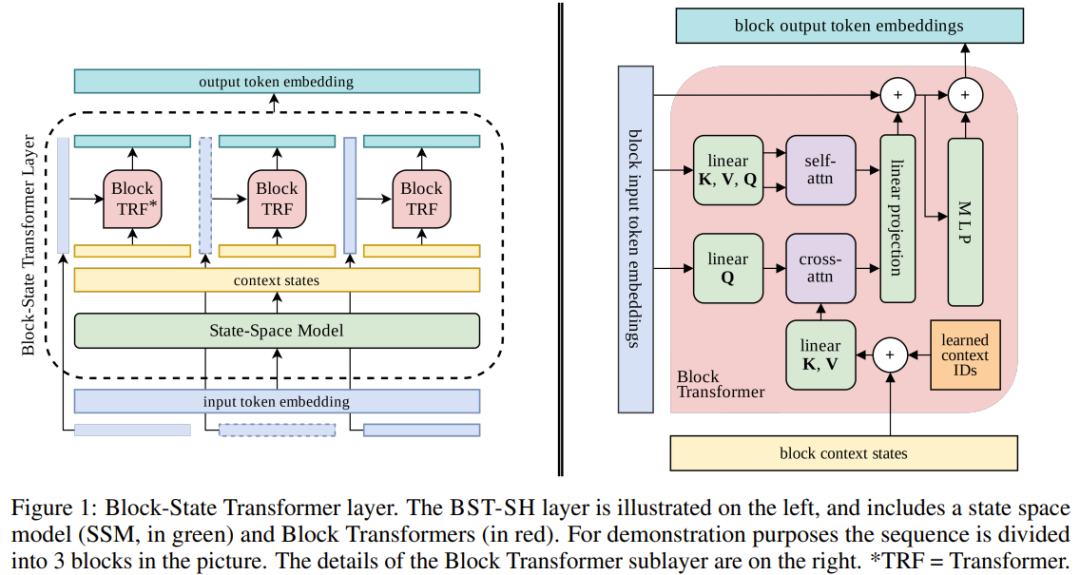
Paper link:https://arxiv.org/pdf/2306.09539.pdfIt is reported that this model can integrate the attention mechanism while processing long input sequences to predict the next token. Compared to Transformer-based layers, BST is fully parallelizable and can scale for much longer sequences while being up to 10 times faster.In each BST layer, there is an SSM that maps the entire input sequence into a context sequence of the same length. This SSM sub-layer uses FFT-based convolution. The context sequence is then divided into equally sized context blocks, with the size being the window length W; each context block is then input into a Transformer layer, which focuses on a sub-sequence of size W. Afterward, cross-attention is applied to the input token embedding blocks and their corresponding context state blocks, as shown in Figure 1.
Note that by using SSM as a contextualization method, there is no need for sequence recurrence, allowing this SSM-Transformer hybrid layer to run in a fully parallel manner.The final runtime complexity can be expressed as a sum: 𝒪(𝑊²) + 𝒪(𝐿 log 𝐿), where the first term represents the time complexity of the Transformer sub-layer, and the second term is the time complexity of the SSM sub-layer.As long as hardware supports parallel computation, this is a significant improvement compared to the 𝒪(𝐿𝑊) of Block-Recurrent Transformers. Additionally, due to hardware-imposed constraints, the runtime complexity of SSM on complete sequences is comparable to that of Block Transformers on token blocks, further indicating that the BST layer does not have a speed bottleneck. The team verified this through experiments using sequences containing hundreds of thousands of tokens.MethodThis study investigates the next token prediction problem through a decoder-only language model.Preliminary Notes on State SpaceState Space Models can be divided into two main categories:State Space: Structured kernels S4, S5, S4D, DSS follow a structured initialization of convolution kernels, unfolding a linear time-invariant (LTI) dynamic system, as shown below:
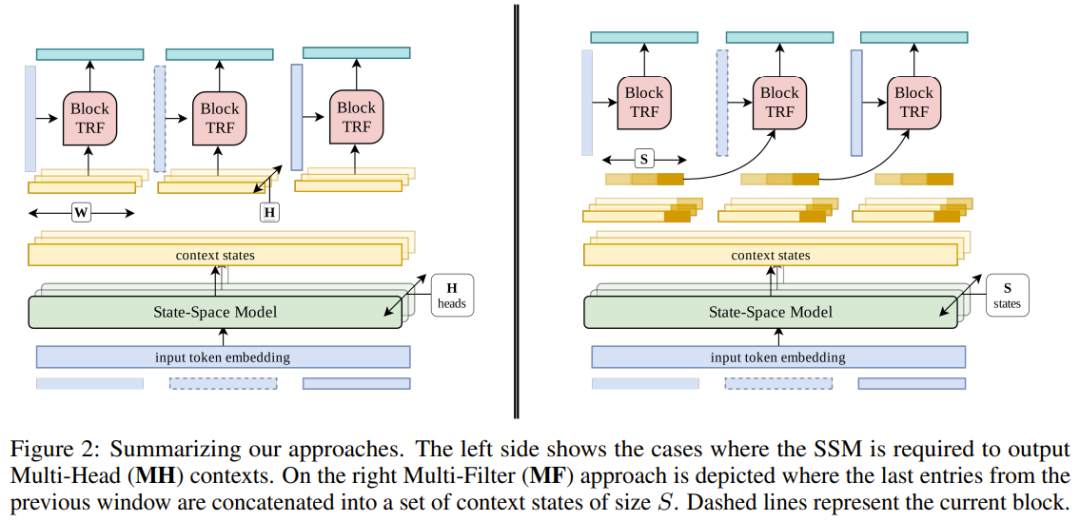
Parameters include state matrix 𝚨∈ℝ^{N×N}, vectors 𝐁∈ℝ^{N×1}, 𝐂∈ℝ^{1×N}, 𝐃∈ℝ^{1×1}. SSM maps a one-dimensional input signal u_k to a one-dimensional output signal y_k.Explicitly parameterized filters. Unlike structured kernels, convolution kernels can also be parameterized as trainable weights and optimized. However, this can lead to poor performance unless specific types of regularization methods are used on these kernels. Attention-free models that replace Transformers also utilize trainable kernels, such as Hyena, which involves exponential decay of weights along the kernel.Block-State Transformer (BST) LayerThe Block-State Transformer layer combines SSM with Block Transformers. In each training iteration, a sequence containing L tokens is sampled from a long document. This token is then embedded and fed into the model. The model consists of stacked Block-State Transformer layers. Each BST layer selectively includes an SSM sub-layer, which provides long-range context for the Block Transformer layer, similar to the functioning of Block-Recurrent Transformer (BRECT) units. The input to this SSM sub-layer is the token embedding sequence from the previous layer, and the output is a sequence of the same length L.This output undergoes context encoding, meaning that each time step’s item may contain information about all previous time steps in that sequence. They collect a certain number S of “context states” from the context sequence, ensuring S ≪ L.These context states are fed into the Block Transformer, replacing the “recurrent state vector” in the Block-Recurrent Transformer. As shown on the right side of Figure 1, subsequent operations remain unchanged, but there is no need to run the recurrent unit of the BRECT unit, as context is now maintained through SSM. In addition to the context states, the input to the Block Transformer also includes blocks/windows of token embeddings of length W; cross-attention is then applied over this window and the context states. The output of this cross-attention operation is then concatenated with the output of self-attention on the input embeddings, followed by a simple projection.SSMs can retain information over longer time scales, and using SSM to maintain context instead of recurrent units results in layers with higher computational efficiency. By integrating SSM into Transformer layers, the recurrent parts can be removed, allowing the Block-State Transformer layer to be fully parallelizable.Context StatesAlthough technically, the latest SSM outputs contain information about the entire sequence, retrieving a single token from the final state may not be feasible. To address this, the team connected a series of states corresponding to the latest token block. This is similar to the method employed by BRECT. This representation can ensure retrievability and accessibility through redundancy.In the newly proposed method, context states are constructed using the outputs of SSMs and fed into the attention heads of Transformers. There are many ways to construct these context states. To guide design decisions, the team considered various design schemes, including using single-head, multi-head, or multi-filter designs. The single-head design is shown in Figure 1. Figure 2 illustrates the designs for multi-head and multi-filter.
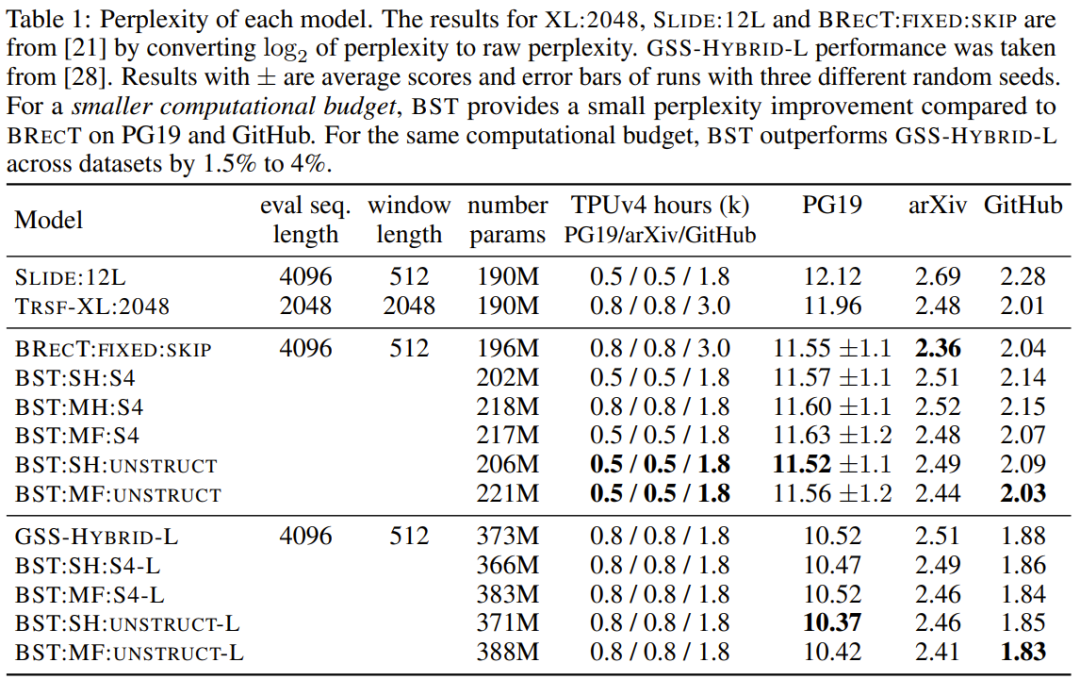
Comparatively, the multi-filter design has the least redundancy in memory states, followed by multi-head, with single-head exhibiting the most redundancy.ResultsThe team conducted experiments on the PG19, GitHub, and arXiv datasets to test the effectiveness of the newly proposed BST on English texts of varying lengths, latex scientific articles, and source code. Table 1 summarizes the experimental results.
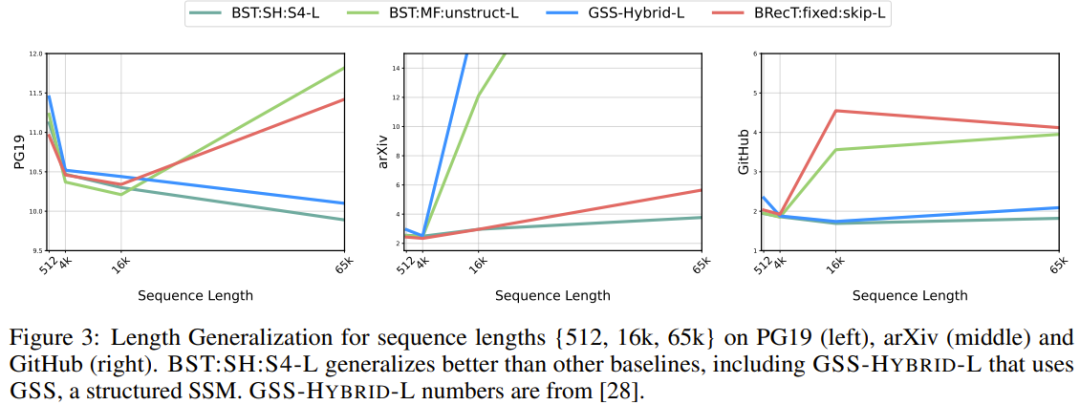
Figure 3 shows the length generalization analysis and reports perplexity. In the experiments, both the new model and the baseline model had approximately 400 million parameters, with a training sequence length of 4k and testing sequence lengths of {512, 16k, 65k}.It can be seen that on PG19, GitHub, and arXiv, when the sequence length is 65k, the perplexity of BST:SH:S4-L is the best.
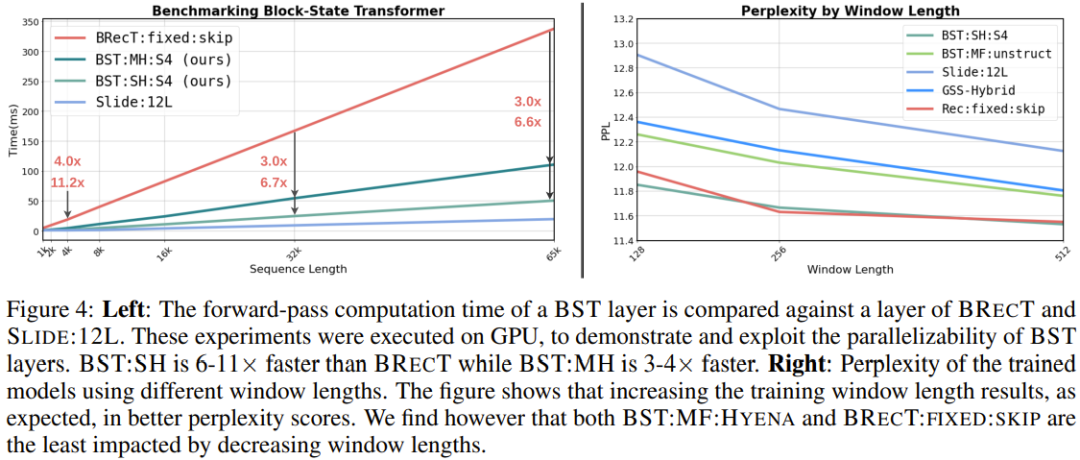
In terms of efficiency, Figure 4 (left) presents the benchmarking results of the BST layer on GPUs.It can be seen that SSM brings significant improvements—6-11 times faster than Block-Recurrent Transformers with recurrent units; even when the sequence length reaches 65k tokens, there is still a 6-fold improvement, at which point the hardware begins to saturate. When using structured SSMs, computational complexity is closely related to the internal memory state size N of the SSM. For the reported performance, N = 16.
The researchers stated that if faster hardware-aware implementations recently introduced in other automatic differentiation frameworks are used, the speed of the BST method can be further improved.For more technical details and experimental results, refer to the original paper.