
Starting in the second half of 2024, the application ecosystem of large models has rapidly exploded. The first one that shocked me was Cursor, which achieved a remarkably high accuracy in intent recognition. The second was DeepSeek during the Spring Festival, which showed me the possibilities of local deployment and fine-tuning for the first time. This article briefly introduces some common applications of large models in the “data warehouse” field and shares some of my own insights.
The representative works are tools like Cursor and WindSurf. Initially, we thought auxiliary coding would save some repetitive tasks, such as table creation and writing comments. However, after using it, I found that for the vast majority of requirements, Cursor could help us implement them quickly.
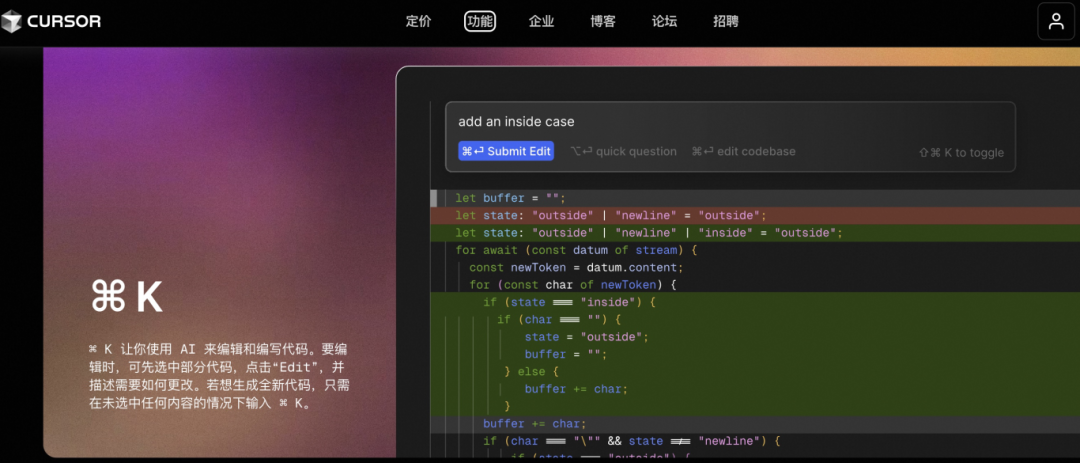
For example:
(1) Convert requirements into a textual description: The following is the requirement content, read the xx table;
(2) Write statistical requirements: by daily dimension, count access PV, GMV, payment order count, payment UV;
(3) Supplement some implementation details: for example, the method of obtaining order labels refers to xxx, which requires generating table structures and executing SQL;
(4) Execute, Cursor will automatically generate the data based on our requirement content and the xx table.
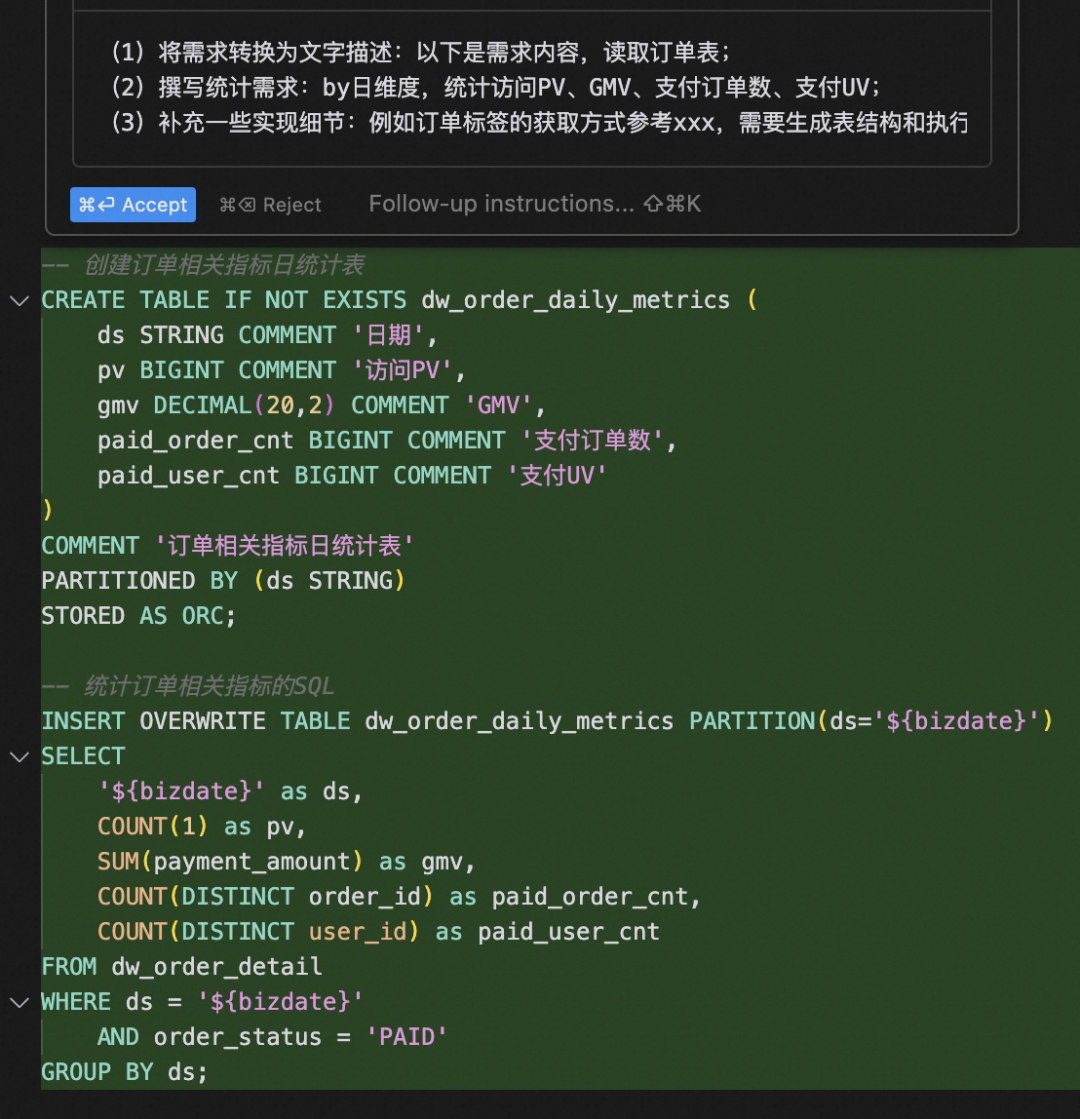
In fact, if we can provide some previously implemented SQL to Cursor as a reference, we basically do not need to make secondary modifications and can directly use the results written.
In daily work, it is conservatively estimated that development efficiency can be improved by more than 30%. If the requirements provided by the business side are relatively standardized, achieving over 50% is not a problem. The main improvement point is that I do not need to think; I can just be a pure copy-paste tool. If the large model makes a mistake, I can keep asking, and it will automatically correct itself.
However, there are several issues with using such tools:
(1) Data security issues, with risks of sensitive data leakage;
(2) Sometimes the code can also be wrong, and it cannot be fully trusted;
(3) It relies on a relatively standardized team documentation library. If the data itself is ambiguous, the large model cannot solve it.
Therefore, after DeepSeek appeared, I was very happy because it provided a means to avoid data security risks and also allowed for fine-tuning. This has a significant impact on our research and development.
When the ChatGPT 3.5 version was released, we thought about whether we could use large models to extract data for business users who do not understand SQL. We already have a relatively complete data warehouse system, and this capability is not difficult to implement.
The core implementation idea is: the user inputs a sentence, and the large model identifies the indicators to be retrieved from the user’s input and automatically generates SQL, then sends the SQL to the execution engine and finally returns the execution results.
However, we quickly found that this approach also has drawbacks because our target users are not professional technical personnel. Moreover, the same thing may be understood and articulated completely differently by different people, which makes semantic recognition very difficult, and users also cannot determine whether the output results are accurate. For example, what is a “new customer”? If there is no prior definition, the probability of getting it wrong is quite high.
Therefore, this path quickly developed into either asking some fixed, routine questions or requiring users to have their own ability to discern whether the data is accurate. In short, data extraction is a highly personalized task but has clear right or wrong conclusions. In our product function design, we tend to let users determine the accuracy of the results, which somewhat limits the promotion of the tool.
Therefore, if a business is very new or many new employees have joined, this tool is still quite useful; but if it is a relatively mature business or a highly stable team, this capability becomes somewhat redundant. Everyone already has more efficient methods for data extraction, such as building a data portal.
This direction can be simply summarized as: “Can we generate analytical conclusions with one sentence?”
In the early days, we all believed that the reasoning capability of large models could replace the responsibilities of data analysts. For example, analyzing the reasons for fluctuations in the North Star metric yesterday, allowing the large model to drill down by dimension and tell me what the main influencing factors are.
However, in reality, this can only solve some relatively routine analytical problems because routine problems are those that everyone encounters frequently, and the solutions are relatively fixed. Therefore, it is a way to “solve repetitive labor”. For instance, anomaly attribution, market insights, potential assessments, and churn predictions still fundamentally require us to design and implement based on existing business experience, and we need to define the indicator decomposition paths and output documentation in advance.
Thus, in the future, low-end development roles, like BI, will likely be replaced by large models, but high-end roles that provide solutions will still be needed.
However, if we have enough tokens, we can allow the large model to directly read our raw data to analyze the questions we want to consider. This method is more efficient and better suited for the “self-service analysis” scenario. Because once it can read detailed data, the large model can often infer answers that are beyond our expectations, which can be seen as a form of “crowdsourcing” to some extent.
When we tried this before, consuming tokens required payment. Now with DeepSeek, everyone can try it out, which truly demonstrates how open-source can promote the vigorous development of the industry. Full Guide to DeepSeek: The Ultimate Guide from Beginner to Pro (with Download)
This is an application that everyone is familiar with but may actually overlook. In the field of data development, not only is writing code important, but also adding understandable comments to the code is equally important.
Similarly, the efficiency of coding tools for code error correction, code rewriting, modifying comments, and generating templates has gradually been applied in development tools. Currently, it seems that the efficiency improvement is around 5%, and we are waiting for more features to be launched in the future to increase accuracy, which will further boost efficiency.
Recently, there was news that Facebook began to try using large models to complete the vast majority of business logic writing, and then on February 10, they initiated large-scale layoffs, which is truly a pure capitalist move. If all business logic is implemented using large models, then document writing will no longer be necessary.
Besides writing documents, large models excel in tasks related to external inquiries. Many scenarios that previously required human intervention can now be replaced by large models. The Indian customer service issues we often complain about may be resolved in this round of technological revolution.
This round of AI revolution is exploding. From the trend, it seems that most programmers will indeed be eliminated in the future. The good news is that organizing underlying data and documentation, ensuring accuracy, will still be a “basic need”; there will still be a place for data warehouse jobs in the future. The bad news is that once a business matures, this part will also only require minimal maintenance costs.
Therefore, in the future, as a data warehouse engineer, one must focus on business understanding. Because pushing everyone to the front line to make money and meet the needs of capitalists for growth, this social rule has not changed.
First Release:Tsinghua University produced! 104-page DeepSeek Beginner to Expert Guide (Downloadable)A few days ago, produced by Tsinghua University, it instantly became popular online.The experts from Tsinghua shared many practical tips without reservation, from tricks to avoid AI hallucinations to secrets for designing excellent prompts.
Second Release:DeepSeek from Beginner to Expert: 7 Major Scenarios + 50 Major Cases + Complete Prompt Set – 112 Pages (with Open Download)From 0 to 1, 1 to 100, from beginner to advanced, and from advanced to expert, the DeepSeek guide and usage guide covers workplace, daily life, family education, entrepreneurship, and self-media fields, applicable across industries,all are practical content that can be directly applied.
