Source: Algorithm Advancement
This article is approximately 4500 words long and is recommended for a 9-minute read.
This article introduces the Graph Transformer, a novel and powerful neural network model capable of effectively encoding and processing graph-structured data.
Graph neural networks (GNNs) and Transformers represent a recent advancement in machine learning, providing a new type of neural network model for graph-structured data. The combination of Transformers and graph learning demonstrates strong performance and versatility across various graph-related tasks.
This review provides an in-depth overview of the latest advancements and challenges in Graph Transformer research. We first introduce the foundational concepts of graphs and Transformers, then explore Graph Transformers from a design perspective, focusing on how they integrate graph inductive bias and graph attention mechanisms into the Transformer architecture. Additionally, we propose a taxonomy categorizing Graph Transformers based on depth, scalability, and pre-training strategies, summarizing key principles for developing efficient Graph Transformer models. Besides technical analysis, we also discuss the applications of Graph Transformer models in node-level, edge-level, and graph-level tasks, exploring their potential in other application scenarios. Finally, we identify remaining challenges in the field, such as scalability and efficiency, generalization and robustness, interpretability, dynamic and complex graphs, and data quality and diversity, outlining future directions for Graph Transformer research.
Graphs, as highly expressive data structures, are widely used to represent complex data across various domains, such as social media, knowledge graphs, biology, chemistry, and transportation networks. They capture structural and semantic information from data, facilitating the development of tasks such as recommendation systems, question-answering systems, anomaly detection, sentiment analysis, text generation, and information retrieval. To effectively handle graph-structured data, researchers have developed various graph learning models, such as Graph Neural Networks (GNNs), which can learn meaningful representations of nodes, edges, and graphs. In particular, GNNs that follow the message-passing framework excel in various graph-based tasks by iteratively aggregating neighbor information and updating node representations. Applications ranging from information extraction to recommendation systems benefit from GNN modeling of knowledge graphs.
Recently, as an emerging and powerful graph learning approach, Graph Transformers have garnered significant attention in both academia and industry. The research on Graph Transformers is inspired by the successful application of Transformers in natural language processing (NLP) and computer vision (CV), and it combines the advantages of GNNs. Graph Transformers effectively process graph data by incorporating graph inductive bias (e.g., prior knowledge or assumptions about graph properties). Moreover, they can adapt to dynamic and heterogeneous graphs, leveraging features and attributes of nodes and edges. Various adaptations and extensions of Graph Transformers have demonstrated superiority in addressing various challenges in graph learning, such as large-scale graph processing. Additionally, Graph Transformers have been successfully applied across various domains and applications, showcasing their effectiveness and versatility.
Existing reviews have not adequately covered the latest advancements and comprehensive applications of Graph Transformers. Furthermore, most reviews fail to provide a systematic classification of Graph Transformer models. For instance, Chen et al. primarily focus on the applications of GNNs and Graph Transformers in CV but do not summarize the classification of Graph Transformer models or address other fields such as NLP. Similarly, Muller et al. provide an overview of Graph Transformers and their theoretical properties but do not offer a comprehensive review of existing methods or evaluate their performance across various tasks. Lastly, Min et al. focus on the architectural design aspects of Graph Transformers, systematically assessing the performance of different components across various graph benchmarks but do not include significant applications of Graph Transformers or discuss open issues in the field.
To fill these gaps, this review aims to comprehensively and systematically revisit the latest advancements and challenges in Graph Transformer research from both design and application perspectives. Compared to existing reviews, our main contributions are as follows:
-
We comprehensively review the design perspectives of Graph Transformers, including graph inductive bias and graph attention mechanisms. We categorize these techniques and discuss their advantages and disadvantages.
-
We propose a new taxonomy of Graph Transformers based on depth, scalability, and pre-training strategies, providing guidelines for selecting effective Graph Transformer architectures for different tasks and scenarios.
-
We review the application perspectives of Graph Transformers across various graph learning tasks, as well as their application scenarios in other fields such as NLP and CV tasks.
-
We identify key open questions and future directions in Graph Transformer research, such as model scalability, generalization, interpretability, efficient temporal graph learning, and data-related issues.
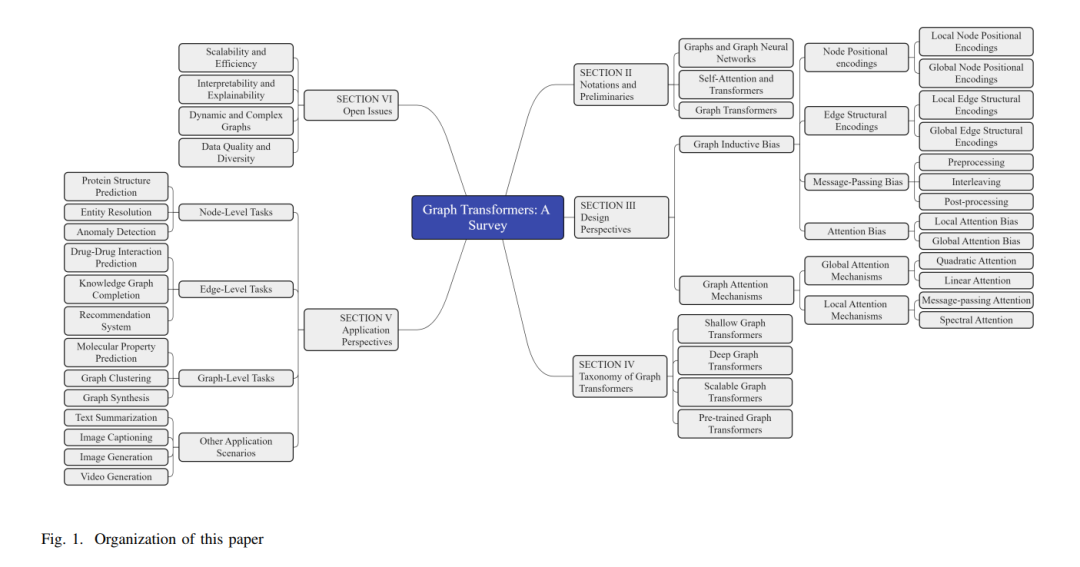
The overview of this article is illustrated in Figure 1. The structure of the subsequent review is as follows: Section 2 introduces the symbols and preparatory knowledge related to graphs and Transformers. Section 3 delves into the design perspectives of Graph Transformers, including graph inductive bias and graph attention mechanisms. Section 4 presents the taxonomy of Graph Transformers, categorizing them based on their depth, scalability, and pre-training strategies. Additionally, it provides guidelines for selecting appropriate Graph Transformer models to tackle different tasks and domains. Section 5 explores the application perspectives of Graph Transformers across various node-level, edge-level, and graph-level tasks, as well as other application scenarios. Section 6 identifies open questions and future directions in Graph Transformer research. Finally, Section 7 summarizes this article and emphasizes its main contributions.
Taxonomy of Graph Transformers
In recent years, Graph Transformers have attracted significant interest. This section delves into the four main categories found in the current literature: shallow Graph Transformers, deep Graph Transformers, scalable Graph Transformers, and pre-trained Graph Transformers. By analyzing representative models in each category, we aim to provide valuable guidance for designing efficient Graph Transformers.
A. Shallow Graph Transformers
Shallow Graph Transformers represent a class of GNNs that leverage self-attention mechanisms to obtain node representations from graph-structured data. These models are inspired by the ability of Transformers to effectively capture long-range dependencies in sequential data through self-attention, extending this concept to graph data by computing self-attention weights based on node features and graph topology. The primary goal of shallow Graph Transformers is to achieve excellent performance while minimizing computational complexity and memory usage.
Shallow Graph Transformers can be viewed as a generalized version of Graph Attention Networks (GAT). GAT employs a multi-head attention mechanism to compute node embeddings. However, GAT has limitations, such as the inability to model edge features and a lack of diversity among attention heads. Several GAT extensions have been proposed in the literature to address these issues. For example, GTN introduced by Yun et al. incorporates an edge self-attention mechanism to include edge information into node embeddings. The Graph Attention Transformer Encoder (GATE) proposed by Ahmad et al. applies a masked self-attention mechanism to enable different nodes to learn distinct attention patterns. GATE also utilizes position feedforward networks and dropout to enhance model capacity and generalization ability. A summary of shallow Graph Transformer methods can be found in Table II.
Shallow Graph Transformers are efficient and adaptable, capable of handling various graph learning tasks and different types of graphs, but their lack of depth and recursion may limit their ability to capture complex dependencies. Their performance may also be influenced by the choice of mask matrix and the number of attention heads, indicating a need for further research on their optimization design and regularization.
B. Deep Graph Transformers
Deep Graph Transformers consist of multiple stacked self-attention layers, which may include optional skip connections, residual connections, or dense connections between layers. They aim to achieve higher performance by increasing model depth and complexity. Deep Graph Transformers extend shallow Graph Transformers by hierarchically applying self-attention layers to node features and graph topology.
However, deep Graph Transformers also face several challenges that need to be addressed. One challenge is the difficulty of training deeper models, which can be alleviated using techniques such as PairNorm introduced in DeeperGCN. Another challenge is the over-smoothing problem, which can be mitigated by employing gated residual connections and generalized convolution operators (as proposed in DeeperGCN). Additionally, the disappearance of global attention capability and the lack of diversity among attention heads are issues that require resolution, which can be addressed by methods like DeepGraph, which introduces substructure tokens and local attention to improve the focus and diversity of global attention.
Although deep Graph Transformers are complex, they can achieve top performance across various graph learning tasks and adapt to different types of graphs and domains. However, their high computational cost, optimization difficulty, and sensitivity to hyperparameters require further research to optimize design and training. A summary of deep Graph Transformer methods can be found in Table III.
C. Scalable Graph Transformers
Scalable Graph Transformers are a class of Graph Transformers designed to address scalability and efficiency challenges when applying self-attention to large-scale graphs. These Transformers are specifically designed to reduce computational costs and memory usage while maintaining or improving performance. Various techniques are employed to reduce the complexity of self-attention, such as sparse attention, local attention, and low-rank approximations. Scalable Graph Transformers can be viewed as enhanced versions of deep Graph Transformers, addressing challenges like over-smoothing and limited global attention capability.
Several scalable Graph Transformer models have been proposed to improve the scalability and efficiency of Graph Transformers. For instance, GPS introduced by Rampašek et al. employs low-rank matrix approximations to reduce computational complexity and achieves state-of-the-art results across various benchmarks. GPS separates local real edge aggregation from fully connected Transformers and combines different positional information and structural encoding to capture graph topology. It also provides a modular framework supporting various encoding types and local and global attention mechanisms. DyFormer developed by Cong et al. is a dynamic graph Transformer that utilizes substructure tokens and local attention to enhance the focus and diversity of global attention. DyFormer employs a time-joined graph structure and subgraph-based node sampling strategies to achieve efficient and scalable training.
Scalable Graph Transformers represent an innovative and efficient class of Graph Transformers that excel at processing large-scale graphs while minimizing computational costs and memory usage. However, scalable Graph Transformers also face limitations, including trade-offs between scalability and expressiveness, challenges in selecting optimal hyperparameters and encodings, and a lack of theoretical analysis regarding their convergence and stability. Therefore, further research is required to explore optimal designs and evaluations of scalable Graph Transformers in various applications. A comprehensive overview of scalable Graph Transformer methods can be found in Table IV.
D. Pre-trained Graph Transformers
Pre-trained Graph Transformers leverage large-scale unlabeled graphs to obtain transferable node embeddings. These embeddings can be fine-tuned for downstream tasks to address data scarcity and domain adaptation challenges in graph learning. These Transformers are similar to pre-trained large language models (LLMs), using self-supervised learning objectives on graph datasets, such as masked node prediction, edge reconstruction, and graph contrastive learning. These objectives aim to capture the inherent properties of graph data independently of external labels or supervision. By combining specific task layers or loss functions and optimizing on labeled data, pre-trained models can be fine-tuned for specific downstream tasks, enabling them to transfer knowledge obtained from large-scale graph datasets to subsequent tasks, achieving better performance than training from scratch.
Pre-trained Graph Transformers face several challenges, such as selecting appropriate pre-training tasks, integrating domain knowledge, incorporating heterogeneous information, and evaluating pre-training quality. To address these issues, KPGT and KGTransformer have been proposed. KPGT utilizes additional domain knowledge for pre-training, while KGTransformer applies a unified knowledge representation and fusion (KRF) module across various tasks. Despite their powerful and flexible capabilities, pre-trained Graph Transformers also encounter issues related to graph data heterogeneity and sparsity, domain adaptation, model generalization, and performance interpretation. A summary of pre-trained Graph Transformer methods can be found in Table V.
E. Guidelines for Designing Efficient Graph Transformers
Developing efficient Graph Transformers requires careful attention to detail and thorough consideration. This guide provides general principles and tips for designing Graph Transformers for various scenarios and tasks.
-
Select the appropriate type of Graph Transformer based on the nature and complexity of the graph data and tasks. For simple and small-scale graph data, a few layers of shallow Graph Transformers may suffice. For complex and large-scale graph data, deep Graph Transformers with more layers can learn more expressive representations. For dynamic or streaming graph data, scalable Graph Transformers are more efficient. Pre-trained Graph Transformers are more suitable for sparse or noisy graph data.
-
Design suitable structural and positional encodings for graph data. These encodings capture the structure of the graph and are added before inputting node or edge features into the Transformer layers. The choice of encoding depends on the characteristics of the graph data, such as directionality, weights, and homogeneity. Careful design of these encodings can ensure their informativeness.
-
Optimize the self-attention mechanism to adapt to graph data. The self-attention mechanism computes attention scores between all pairs of nodes or edges in the graph, capturing long-range dependencies and interactions. However, this introduces challenges such as computational complexity, memory consumption, overfitting, over-smoothing, and compression. Techniques such as sampling, sparsification, partitioning, hashing, masking, regularization, and normalization can be employed to address these challenges and improve the quality and efficiency of the self-attention mechanism.
-
Utilize pre-training techniques to enhance the performance of Graph Transformers. Pre-training techniques leverage pre-trained models or data from other domains or tasks to transfer knowledge or parameters to specific graph learning tasks. Methods such as fine-tuning, distillation, and adaptation can be used to adjust pre-trained models or data. Leveraging pre-training techniques is particularly beneficial when there is a wealth of pre-training data or resources available.
Graph Transformers are a novel and powerful class of neural network models capable of effectively encoding and processing graph-structured data. This review provides a comprehensive overview of Graph Transformers from design perspectives, taxonomies, applications, and open questions. We first discuss how Graph Transformers integrate graph inductive bias, including node positional encodings, edge structural encodings, message-passing biases, and attention biases, to encode the structural information of graphs. Then, we introduce the design of graph attention mechanisms, including both global and local attention mechanisms. Next, we propose a taxonomy of Graph Transformers. This review also includes design guidelines for efficient Graph Transformers, providing best practices and recommendations for selecting appropriate components and hyperparameters. Additionally, we review the application scenarios of Graph Transformers based on various graph-related tasks (such as node-level, edge-level, and graph-level tasks) as well as tasks in other fields. Finally, we identify the current challenges and future directions for Graph Transformers. This review aims to provide valuable references for researchers and practitioners interested in Graph Transformers and their applications.
Link:
https://arxiv.org/pdf/2407.09777
Data Pie THU, as a public account for data science, is backed by Tsinghua University’s Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for gathering data talent, creating the strongest group of big data in China.

Sina Weibo: @Data Pie THU
WeChat Video Account: Data Pie THU
Today’s Headline: Data Pie THU