Click the above “Visual Learning for Beginners” to select “Star” or “Pin”
Important content delivered at the first time
This article is adapted from | Deep Learning This Little Thing
-
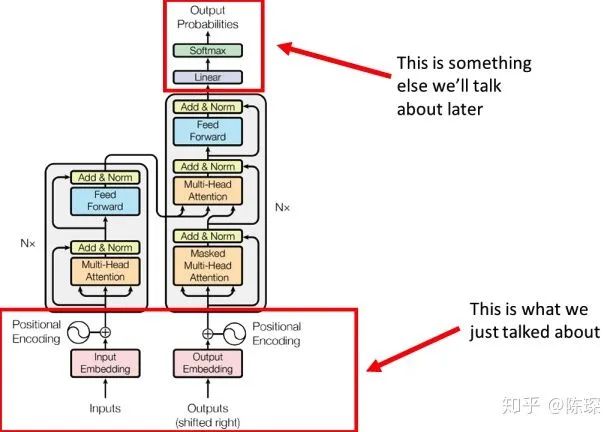
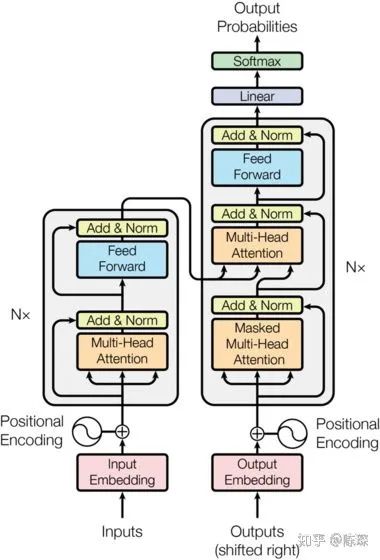
Overall Architecture Description
-
Input & Output Embedding
-
OneHot Encoding
-
Word Embedding
-
Positional Embedding
-
Input Short Summary
-
Encoder
-
Encoder Sub-layer 1: Multi-Head Attention Mechanism
-
Step 1
-
Step 2
-
Step 3
-
Encoder Sub-layer 2: Position-Wise Fully Connected Feed-Forward
-
Encoder Short Summary
-
Decoder
-
Diff_1: “masked” Multi-Headed Attention
-
Diff_2: Encoder-Decoder Multi-Head Attention
-
Diff_3: Linear and Softmax to Produce Output Probabilities
-
Greedy Search
-
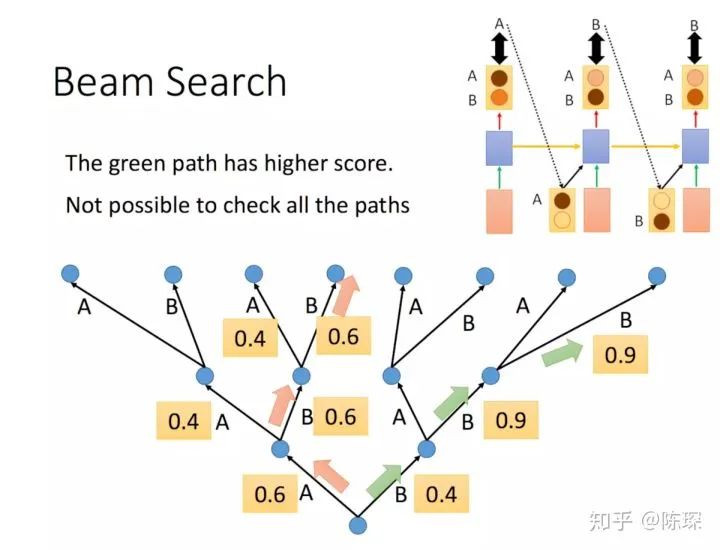
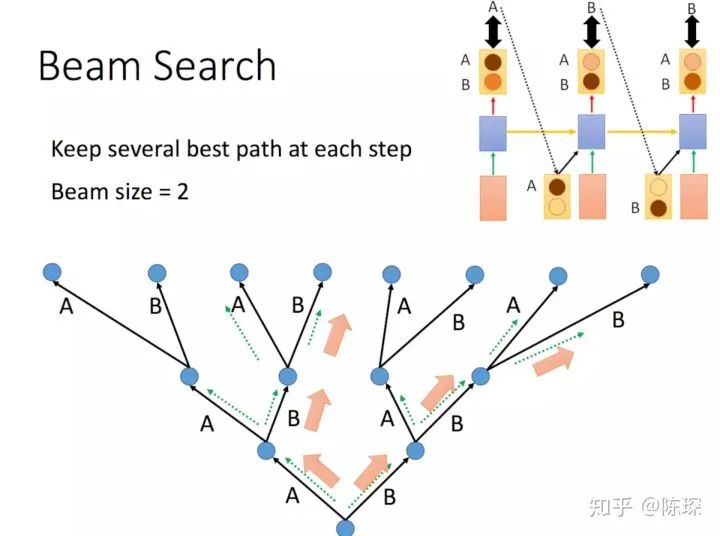
Beam Search
-
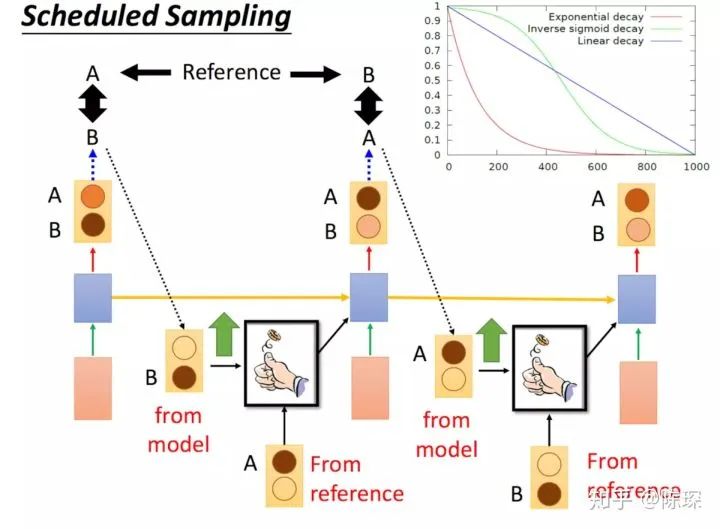
Scheduled Sampling
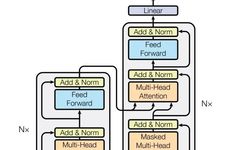
0. Model Architecture
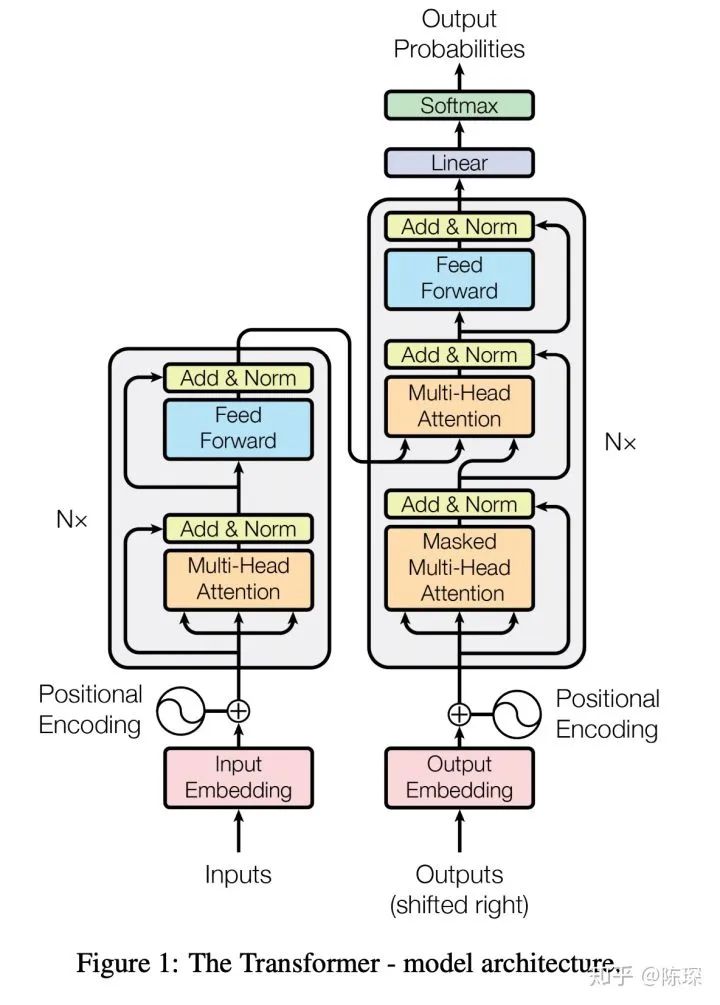

-
Embedding Part
-
Encoder Part
-
Decoder Part
1. Representation of Input and Output
1.1 Representation of Input
1.2 Word Embedding
-
Use pre-trained embeddings and fix them; in this case, it is effectively a lookup table.
-
Randomly initialize it (of course, we can also choose pre-trained results) but set it to be trainable. This way, we continuously improve the embeddings during the training process.
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
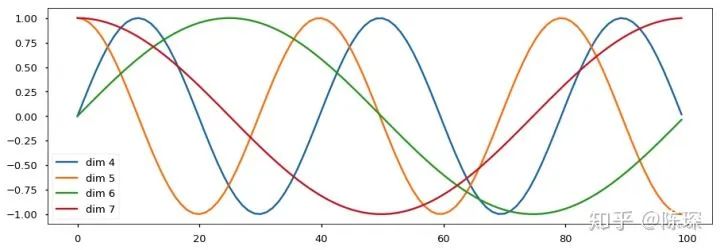
1.3 Positional Embedding
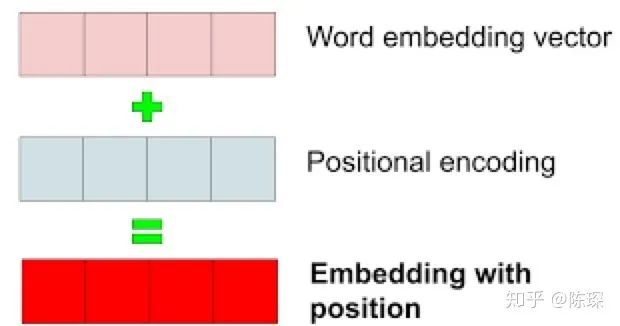
-
Learn positional encoding vectors through training
-
Use formulas to calculate positional encoding vectors
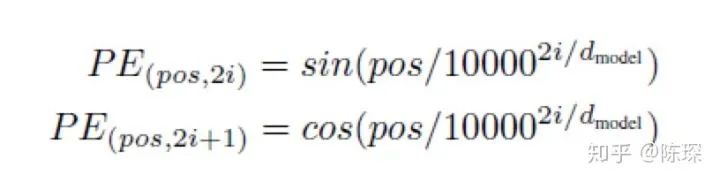
-
pos refers to the position of the word in the sentence
-
i refers to the embedding dimension. For example, if d_model=512 is chosen, then i counts from 1 to 512

class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],requires_grad=False)
return self.dropout(x)
1.4 Input Short Summary
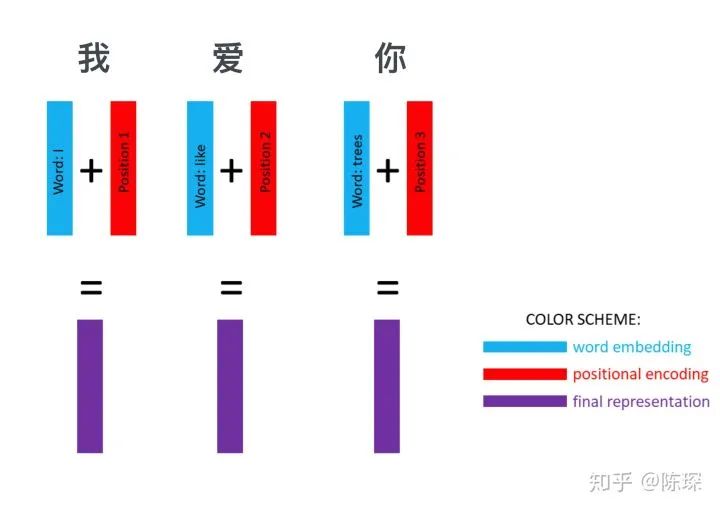
-
nbatches refers to the defined batch size
-
L refers to the length of the sequence (for example, “我爱你”, L = 3)
-
512 refers to the embedding dimension
2. Encoder
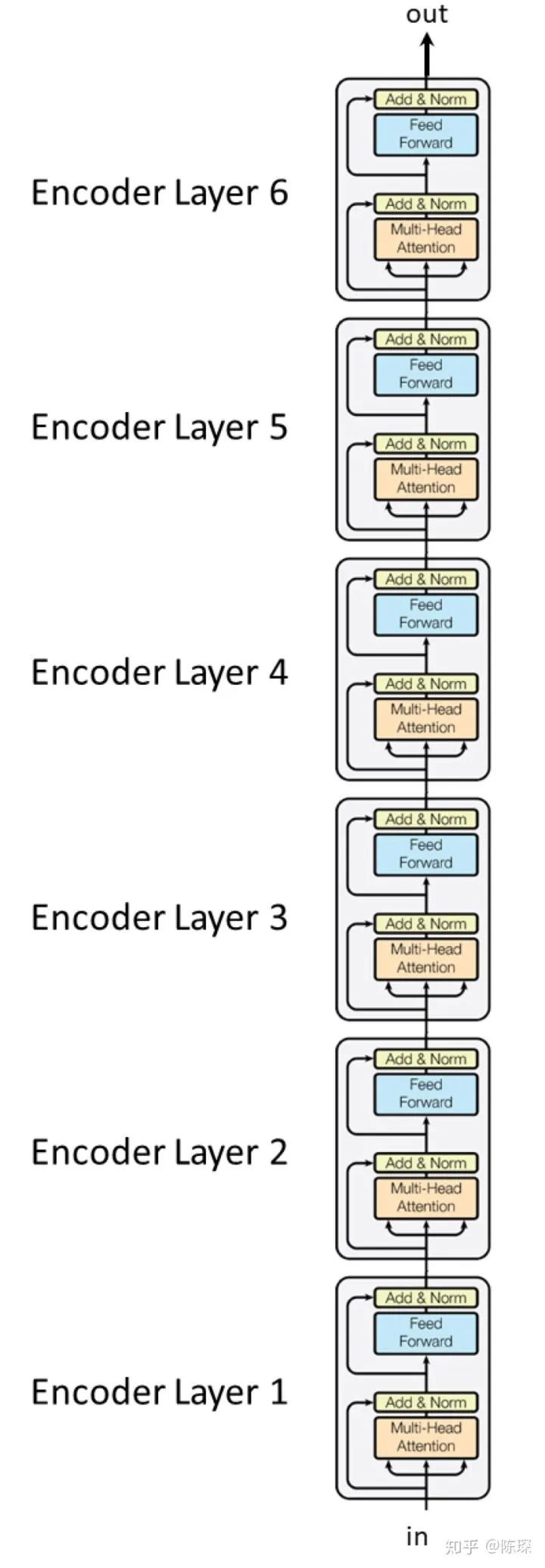
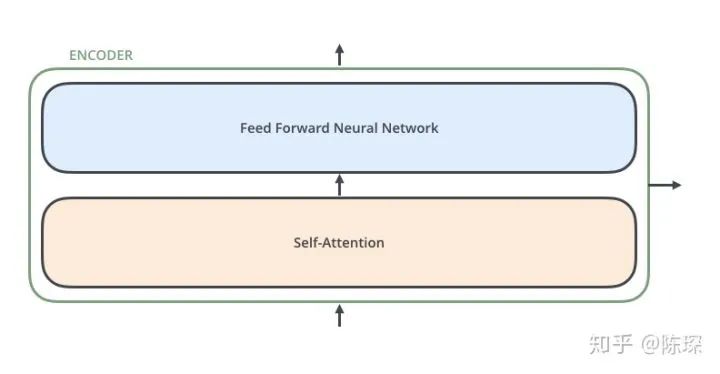
-
The first is the “multi-head self-attention mechanism”
-
The second is a “simple, position-wise fully connected feed-forward network”

class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
-
The class “Encoder” stacks <layer> N times, which is an instance of the class “EncoderLayer”.
-
“EncoderLayer” initialization requires specifying <size>, <self_attn>, <feed_forward>, <dropout>:
-
<size> corresponds to d_model, which is 512 in the paper
-
<self_attn> is an instance of the class MultiHeadedAttention, corresponding to sub-layer 1
-
<feed_forward> is an instance of the class PositionwiseFeedForward, corresponding to sub-layer 2
-
<dropout> corresponds to the dropout rate
2.1 Encoder Sub-layer 1: Multi-Head Attention Mechanism
-
key = linear_k(x)
-
query = linear_q(x)
-
value = linear_v(x)
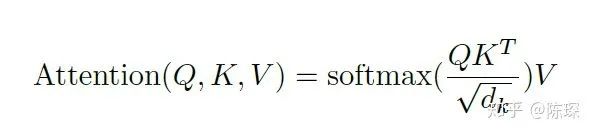
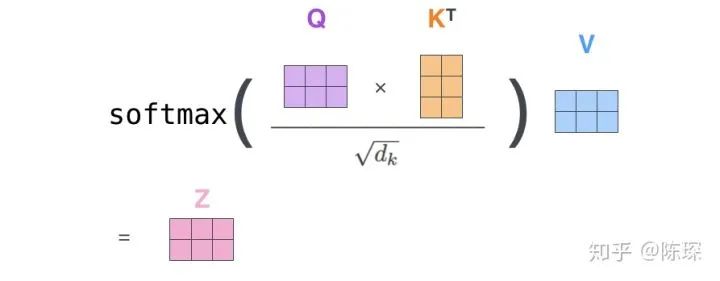
 from becoming too large, which would push the softmax function into regions where it has extremely small gradients. The values after applying softmax are between 0 and 1, which can be understood as obtaining attention weights. Then, based on these attention weights, we calculate the weighted sum of V to obtain Attention(Q, K, V).
from becoming too large, which would push the softmax function into regions where it has extremely small gradients. The values after applying softmax are between 0 and 1, which can be understood as obtaining attention weights. Then, based on these attention weights, we calculate the weighted sum of V to obtain Attention(Q, K, V).class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
-
<h> = 8, which is the number of “heads”. In the base model of the Transformer, there are 8 heads
-
<d_model> = 512
-
<dropout> = dropout rate = 0.1
 . In the above example, d_k = 512 / 8 = 64.
. In the above example, d_k = 512 / 8 = 64.
-
nbatches corresponds to the batch size
-
L corresponds to the sequence length, where for example, L = 3 for “我爱你”
-
“key” and “value” also have the shape of [nbatches, L, 512]
-
Perform linear transformation on “query”, “key”, and “value”; their shape remains [nbatches, L, 512].
-
Reshape them using view() to the shape of [nbatches, L, 8, 64]. Here, h=8 corresponds to the number of heads, and d_k=64 is the dimension of the keys.
-
Transpose to swap dimensions 1 and 2, resulting in a shape of [nbatches, 8, L, 64].
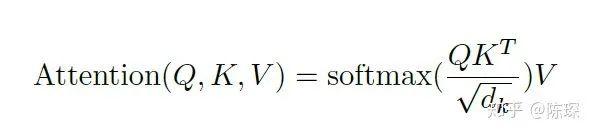
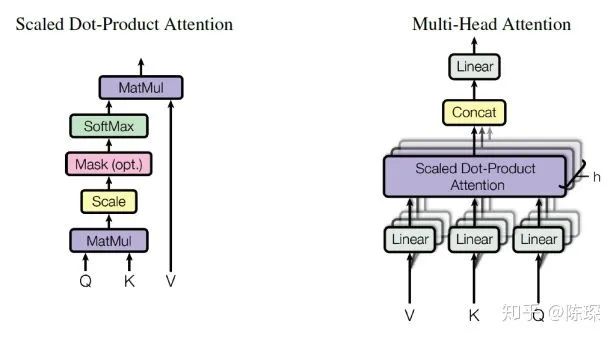
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
2.2 Encoder Sub-layer 2: Position-Wise Fully Connected Feed-Forward Network
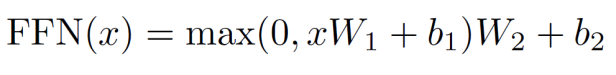
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
2.3 Encoder Short Summary
-
SubLayer-1 performs Multi-Headed Attention
-
SubLayer-2 performs a feedforward neural network
3. The Decoder
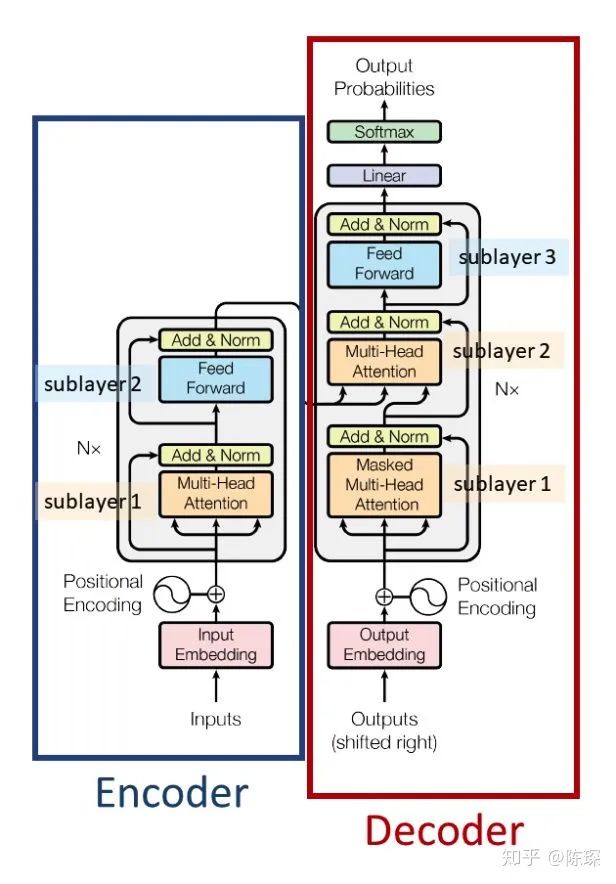
-
Diff_1: The Decoder SubLayer-1 uses a “masked” Multi-Headed Attention mechanism to prevent the model from seeing the data it is supposed to predict, thus preventing leakage.
-
Diff_2: SubLayer-2 is an encoder-decoder multi-head attention.
-
Diff_3: The Linear Layer and Softmax Layer are applied to the output of SubLayer-3 to predict the corresponding word probabilities.
3.1 Diff_1: “masked” Multi-Headed Attention
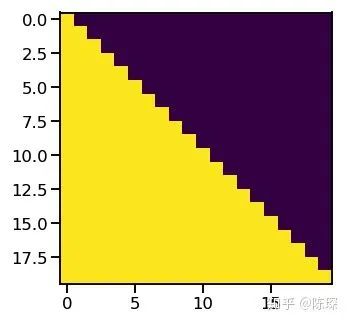
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
3.2 Diff_2: Encoder-Decoder Multi-Head Attention
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)

3.3 Diff_3: Linear and Softmax to Produce Output Probabilities
-
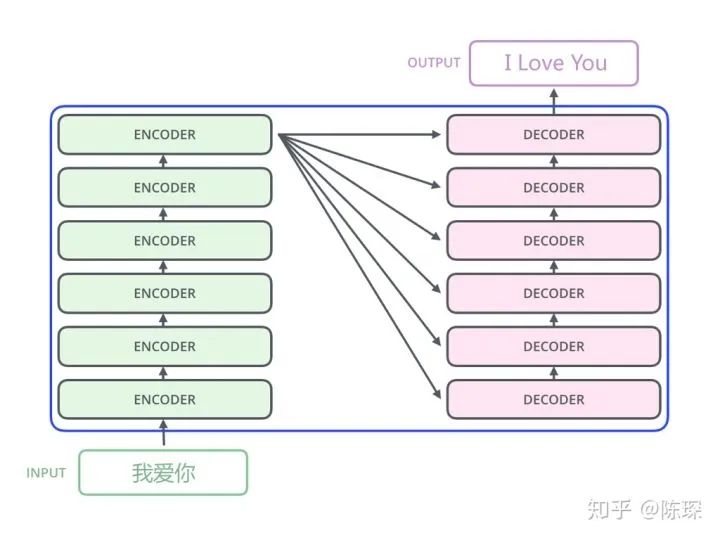
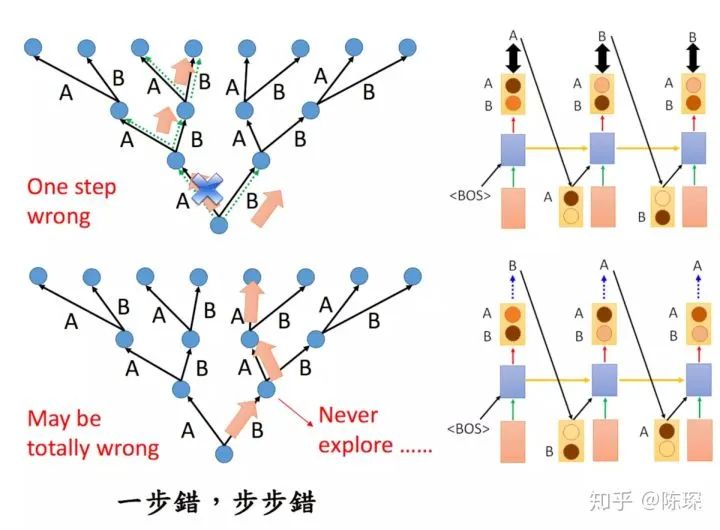
Feed the decoder the embedding result of the entire sentence from the encoder and a special start symbol </s>. The decoder should produce the prediction “I”.
-
Feed the decoder the embedding result from the encoder and “</s>I”; at this step, the decoder should produce the prediction “Love”.
-
Feed the decoder the embedding result from the encoder and “</s>I Love”; at this step, the decoder should produce the prediction “China”.
-
Feed the decoder the embedding result from the encoder and “</s>I Love China”; the decoder should generate the end-of-sentence marker, outputting “</eos>”.
-
After generating </eos>, the translation is complete.
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
—The End—
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, three-dimensional vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future), please scan the WeChat ID below to join the group, and note: “nickname + school/company + research direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please follow the format; otherwise, you will not be approved. After successfully adding, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for understanding~

