Text Matching Methods Series – BERT Matching Model
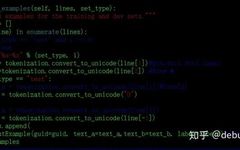
Follow the official account “ML_NLP“ Set as “Starred“, essential content delivered promptly! From | Zhihu Address | https://zhuanlan.zhihu.com/p/85506365 Author | debuluoyi Editor | Machine Learning Algorithms and Natural Language Processing Official Account This article is for academic sharing only. If there is infringement, please contact us to delete it. 1. Overview Before introducing deep interaction … Read more