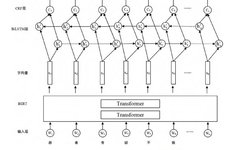
1 Algorithm Introduction
The full name of BERT is Bidirectional Encoder Representation from Transformers, which is a pre-trained language representation model. It emphasizes that pre-training is no longer conducted using traditional unidirectional language models or by shallowly concatenating two unidirectional language models, but rather by adopting a new masked language model (MLM) to generate deep bidirectional language representations. The BERT paper mentioned achieving new state-of-the-art results in 11 NLP (Natural Language Processing) tasks, which is astonishing.
The model has the following main characteristics:
1) It uses MLM to pre-train bidirectional Transformers to generate deep bidirectional language representations.
2) After pre-training, only an additional output layer needs to be added for fine-tuning, enabling state-of-the-art performance across various downstream tasks without requiring task-specific structural modifications to BERT.
2 Algorithm Principles
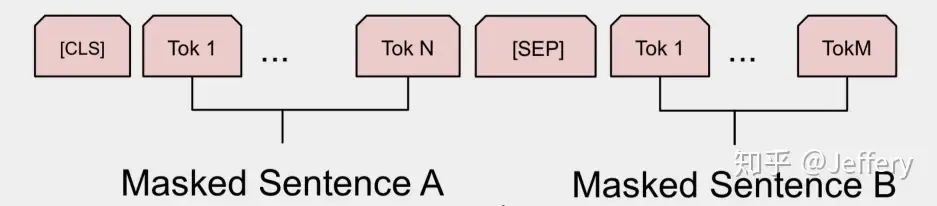
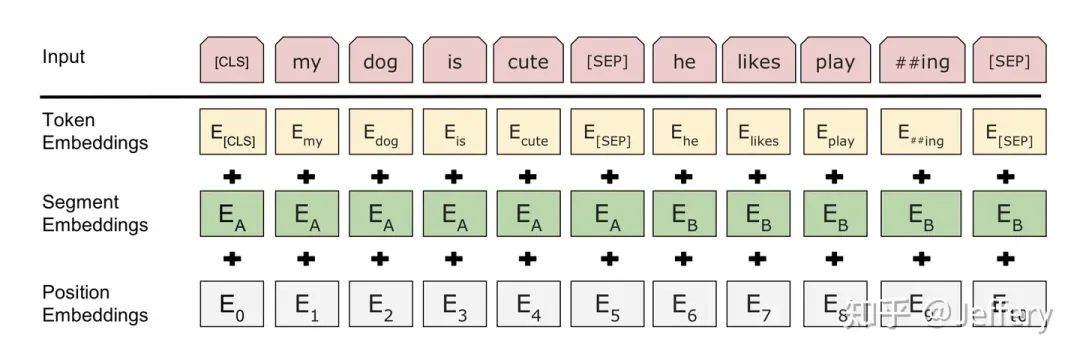
1) In the sequence tokens, a separator token ([SEP]) is inserted after each sentence to separate different sentence tokens.
2) A learnable segmentation embedding is added to each token representation to indicate whether it belongs to sentence A or sentence B.

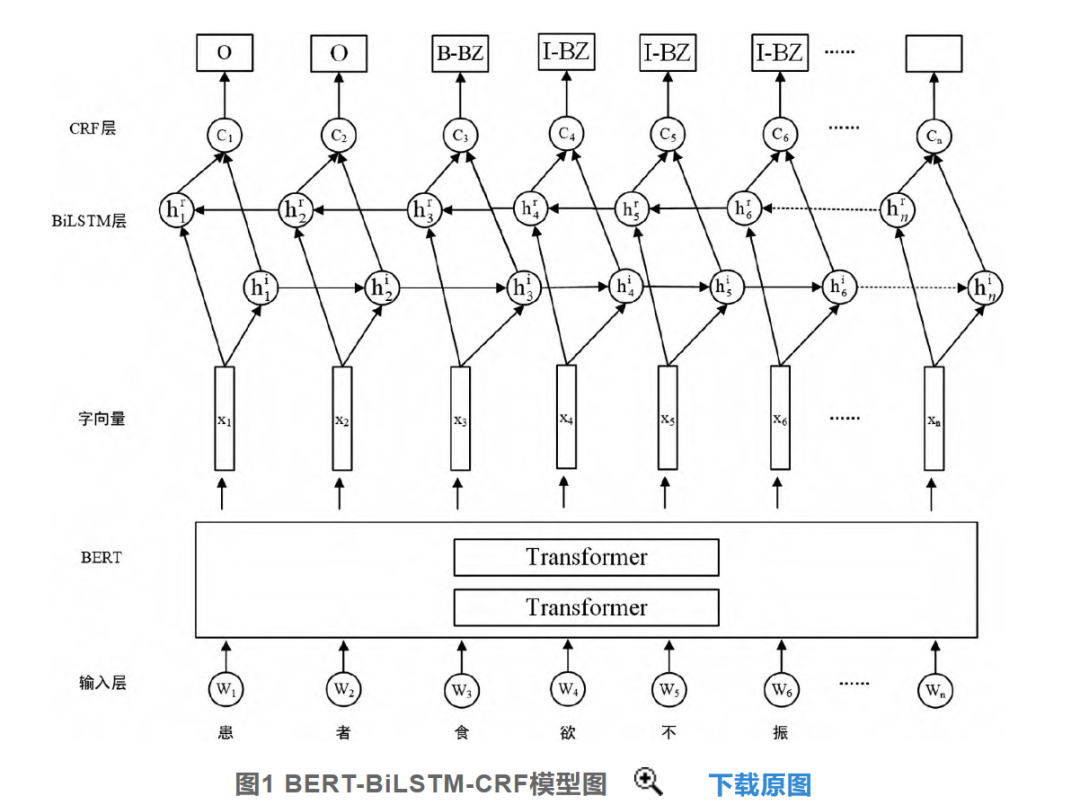
3 Algorithm Applications
4 Conclusion
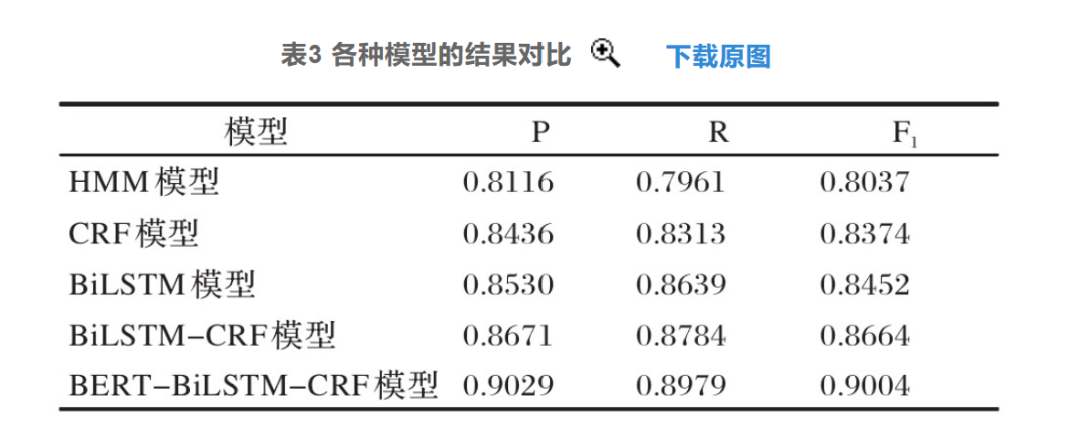
BERT can perform concurrent execution compared to the original RNN and LSTM while extracting the relational features of words in sentences and can extract relational features at multiple different levels, thereby reflecting the semantics of sentences more comprehensively. Compared to word2vec, it can also obtain word meanings based on the context of sentences, thus avoiding ambiguity. However, the BERT model also has disadvantages such as too many parameters, a large model size, susceptibility to overfitting with small training data, and poor support for generative tasks and long sequence modeling.
-
References: [1] Zhihu Column. “Understanding BERT, This Article is Enough”. Accessed on February 28, 2024. https://zhuanlan.zhihu.com/p/403495863. -
[2] Zhihu Column. “Understanding BERT, This Article is Enough”. Accessed on February 28, 2024. https://zhuanlan.zhihu.com/p/403495863. -
[3] Hu Wei, Liu Wei, Shi Yujing. Method for Named Entity Recognition of Traditional Chinese Medicine Cases Based on BERT-BiLSTM-CRF [J]. Computer Era, 2022(09):119-122+135. DOI:10.16644/j.cnki.cn33-1094/tp.2022.09.027. -
Recommended Reading: -
Deep Convolutional Neural Networks – The More Armed, The Stronger -
Factor Analysis – To “Strike”, First Reduce Dimensions -
Independent Component Analysis (ICA) – The “Butcher’s Knife” for Mixed Data Signals


Ancient and Modern Medical Cases Cloud Platform
Providing Over 500,000 Ancient and Modern Medical Case Retrieval Services
Supports Manual, Voice, OCR, and Batch Structured Entry of Medical Cases
Designed Nine Analysis Modules, Close to Clinical Needs
Supports Collaborative Analysis of Massive Medical Cases and Personal Medical Cases
EDC Traditional Chinese Medicine Research Case Collection System
Supports Multi-Center, Online Random Grouping, Data Entry
SDV, Audit Trails, SMS Reminders, Data Statistics
Analysis and Other Functions
Supports Customizable Form Design
Users can log in at: https://www.yiankb.com/edc
Free Experience!
Institute of Traditional Chinese Medicine Information Research, Chinese Academy of Traditional Chinese Medicine
Intelligent R&D Center for Traditional Chinese Medicine Health
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com