Source: Computer Vision and Machine Learning
Author: Jay Alammar
Link: https://jalammar.github.io/illustrated-bert/
This article is about 4600 words long and is recommended to read in 8 minutes.
In this article, we will study the BERT model and understand how it works, which is of great reference value for students in other fields.
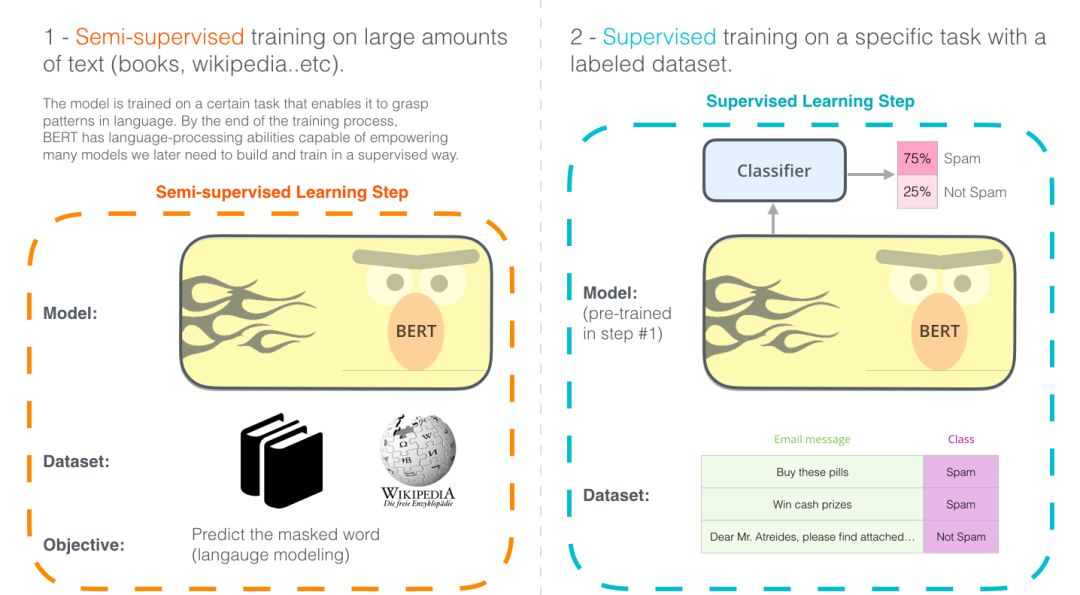
Since Google announced BERT’s outstanding performance on 11 NLP tasks at the end of October 2018, BERT has become a sensation in the NLP field. In this article, we will study the BERT model and understand how it works, which is of great reference value for students in other fields.
2018 is indeed a landmark year for Natural Language Processing (NLP), as we have made significant progress in how to assist computers in understanding the conceptual meaning of sentences in a way that captures potential semantic relationships. Additionally, several open-source communities in the NLP field have released many powerful components that we can download and use for free during our model training process. (It can be said that this year is the ImageNet moment for NLP, as it is similar to the development of computer vision a few years ago.)
 The latest released BERT is a milestone model for NLP tasks, and its release is bound to bring about a new era in NLP. BERT is an algorithm model that has broken numerous records in various natural language processing tasks. Shortly after the release of the BERT paper, Google’s R&D team also open-sourced the model’s code and provided some pre-trained algorithm models for download on large datasets. By open-sourcing this model and providing pre-trained models, Google has enabled everyone to build an NLP algorithm model using it, saving a lot of time, effort, knowledge, and resources required to train language models.
The latest released BERT is a milestone model for NLP tasks, and its release is bound to bring about a new era in NLP. BERT is an algorithm model that has broken numerous records in various natural language processing tasks. Shortly after the release of the BERT paper, Google’s R&D team also open-sourced the model’s code and provided some pre-trained algorithm models for download on large datasets. By open-sourcing this model and providing pre-trained models, Google has enabled everyone to build an NLP algorithm model using it, saving a lot of time, effort, knowledge, and resources required to train language models.
 BERT integrates some of the top ideas in the NLP field in recent times, including but not limited to Semi-supervised Sequence Learning (by Andrew Dai and Quoc Le), ELMo (by Matthew Peters and researchers from AI2 and UW CSE), ULMFiT (by fast.ai founder Jeremy Howard and Sebastian Ruder), the OpenAI transformer (by OpenAI researchers Radford, Narasimhan, Salimans, and Sutskever), and the Transformer (Vaswani et al).
You need to pay attention to some things to properly understand the content of BERT. However, before introducing the concepts involved in the model, you can use BERT’s methods.
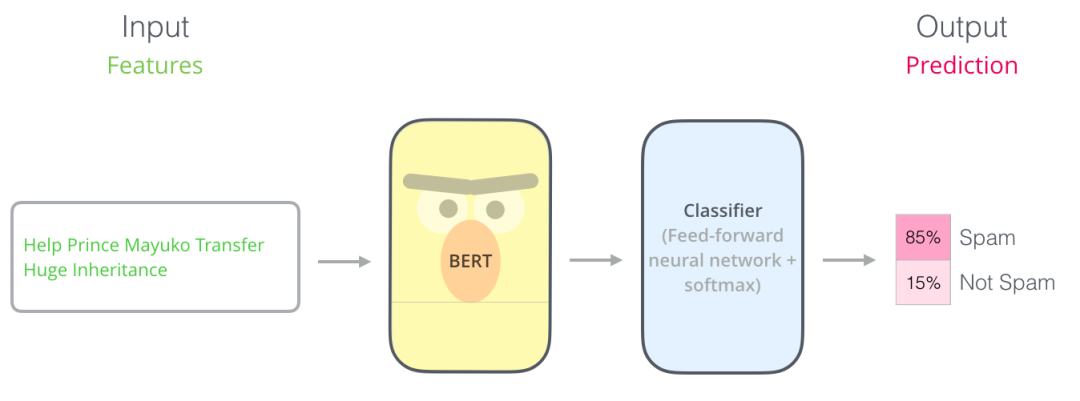
Example: Sentence Classification
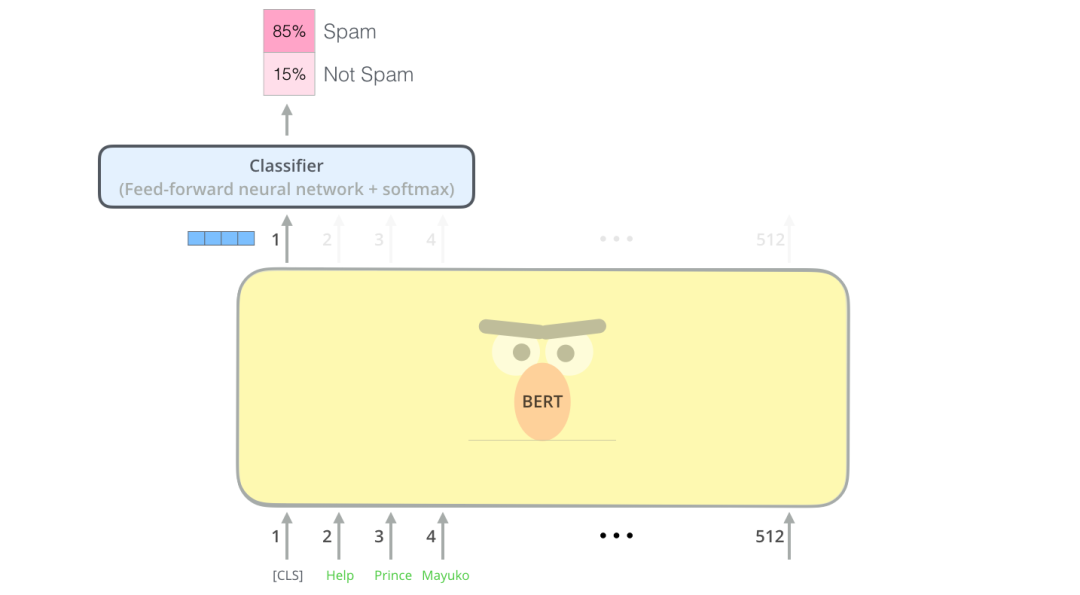
The simplest way to use BERT is to create a text classification model, and the structure of such a model is shown in the figure below:
To train such a model (mainly to train a classifier), the changes that occur in the BERT model during the training phase are minimal. This training process is called fine-tuning and originates from Semi-supervised Sequence Learning and ULMFiT.
For easier understanding, let’s take an example of a classifier. A classifier belongs to the field of supervised learning, which means you need some labeled data to train these models. For the example of a spam classifier, the labeled dataset consists of two parts: the content of the emails and the categories of the emails (categories are divided into “spam” or “not spam”).
Other examples of this use case include:
Input: Movie/Product Reviews. Output: Is the review positive or negative? Example Dataset: SST Fact-Checking Input: Sentences. Output: “Claim” or “No Claim” More ambitious/futuristic examples: Input: Sentences. Output: “True” or “False”
Now that you understand how to use BERT through the example, let’s take a closer look at how it works.
The BERT paper introduces two versions:
BERT integrates some of the top ideas in the NLP field in recent times, including but not limited to Semi-supervised Sequence Learning (by Andrew Dai and Quoc Le), ELMo (by Matthew Peters and researchers from AI2 and UW CSE), ULMFiT (by fast.ai founder Jeremy Howard and Sebastian Ruder), the OpenAI transformer (by OpenAI researchers Radford, Narasimhan, Salimans, and Sutskever), and the Transformer (Vaswani et al).
You need to pay attention to some things to properly understand the content of BERT. However, before introducing the concepts involved in the model, you can use BERT’s methods.
Example: Sentence Classification
The simplest way to use BERT is to create a text classification model, and the structure of such a model is shown in the figure below:
To train such a model (mainly to train a classifier), the changes that occur in the BERT model during the training phase are minimal. This training process is called fine-tuning and originates from Semi-supervised Sequence Learning and ULMFiT.
For easier understanding, let’s take an example of a classifier. A classifier belongs to the field of supervised learning, which means you need some labeled data to train these models. For the example of a spam classifier, the labeled dataset consists of two parts: the content of the emails and the categories of the emails (categories are divided into “spam” or “not spam”).
Other examples of this use case include:
Input: Movie/Product Reviews. Output: Is the review positive or negative? Example Dataset: SST Fact-Checking Input: Sentences. Output: “Claim” or “No Claim” More ambitious/futuristic examples: Input: Sentences. Output: “True” or “False”
Now that you understand how to use BERT through the example, let’s take a closer look at how it works.
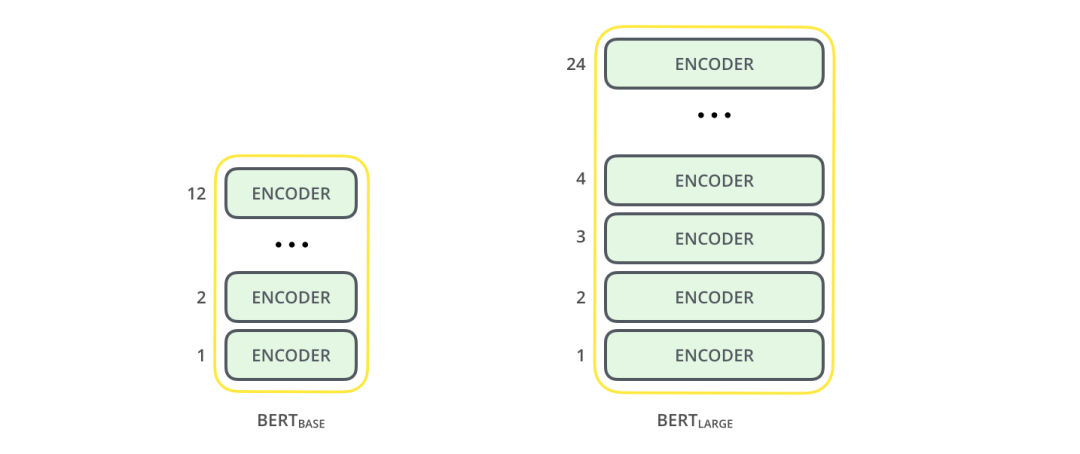
The BERT paper introduces two versions:
-
BERT BASE – Comparable in size to the OpenAI Transformer for performance comparison
-
BERT LARGE – A very large model that achieves state-of-the-art results presented in this paper.
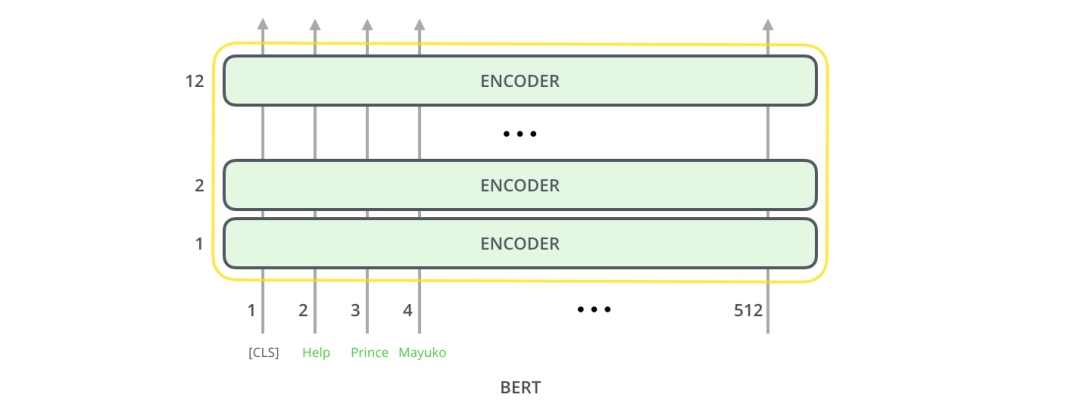
The basic integrated unit of BERT is the Encoder of the Transformer. For an introduction to the Transformer, you can read the author’s previous article: The Illustrated Transformer, which explains the basic concepts of the Transformer model – the fundamental concepts of BERT that we will discuss next.
Both BERT models have a large number of encoder layers (referred to as Transformer Blocks in the paper) – the base version has 12 layers, while the advanced version has 24 layers. It also has a large feedforward neural network (768 and 1024 hidden layer neurons) and many attention heads (12-16). This exceeds the reference configuration parameters in the Transformer paper (6 encoder layers, 512 hidden layer units, and 8 attention heads).
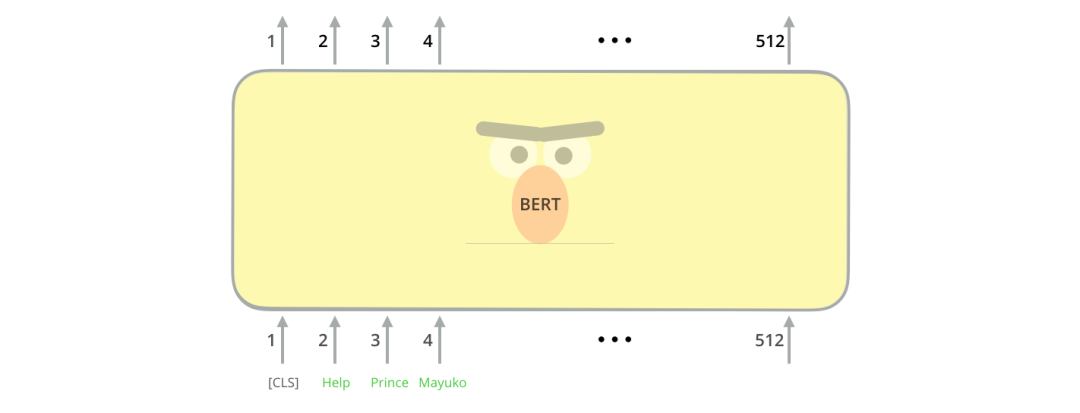
The first character of the input is [CLS], where the character [CLS] simply expresses the meaning of – Classification.
BERT encodes the input similarly to the Transformer. It takes a fixed-length string as input, and the data is passed for computation from bottom to top, each layer using self-attention and passing its results through a feedforward neural network to the next encoder.
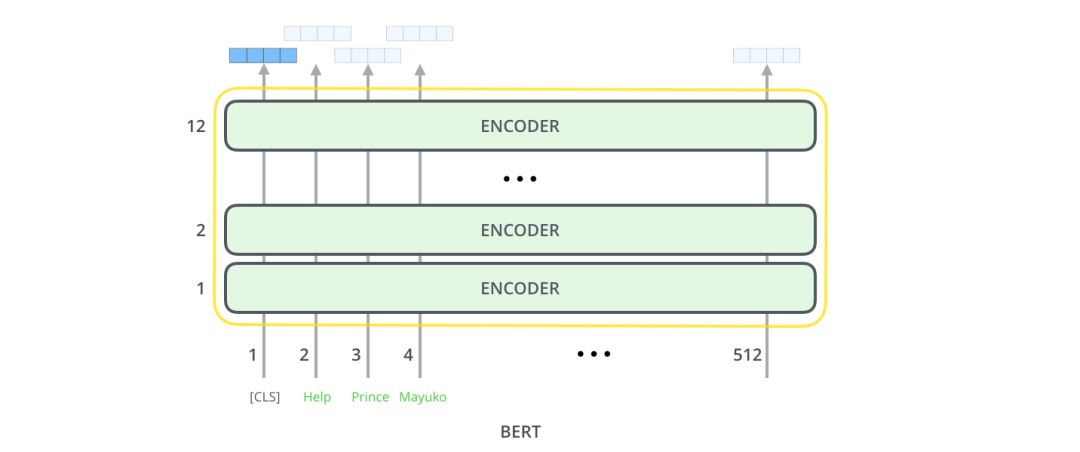
This architecture seems to follow the Transformer architecture (except for the number of layers, which is a parameter we can set). So what is the difference between BERT and the Transformer? It may lie in the model’s output, where we can find some clues.
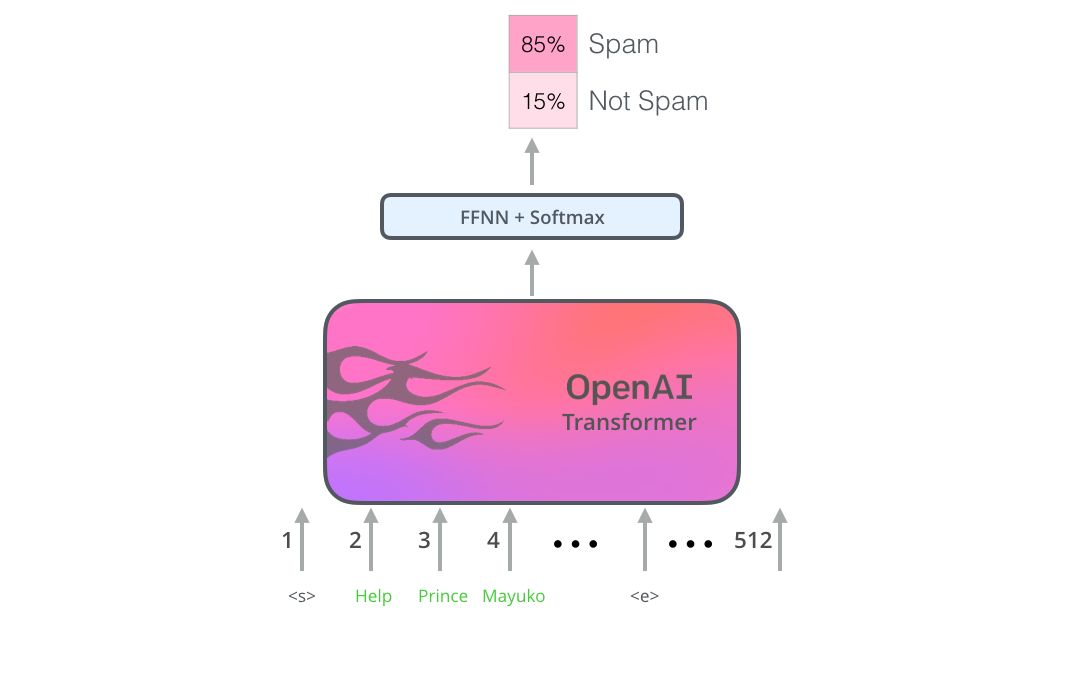
The output returned at each position is a vector of hidden layer size (768 for the base version of BERT). For text classification, we focus on the output at the first position (the first position is the classification identifier [CLS]). As shown in the figure below:
This vector can now be used as input to the classifier of our choice. The paper points out that using a single-layer neural network as a classifier can achieve good results. The principle is as follows:
In the example, there are only spam and non-spam categories. If you have more labels, you just need to increase the number of output neurons and change the final activation function to softmax.
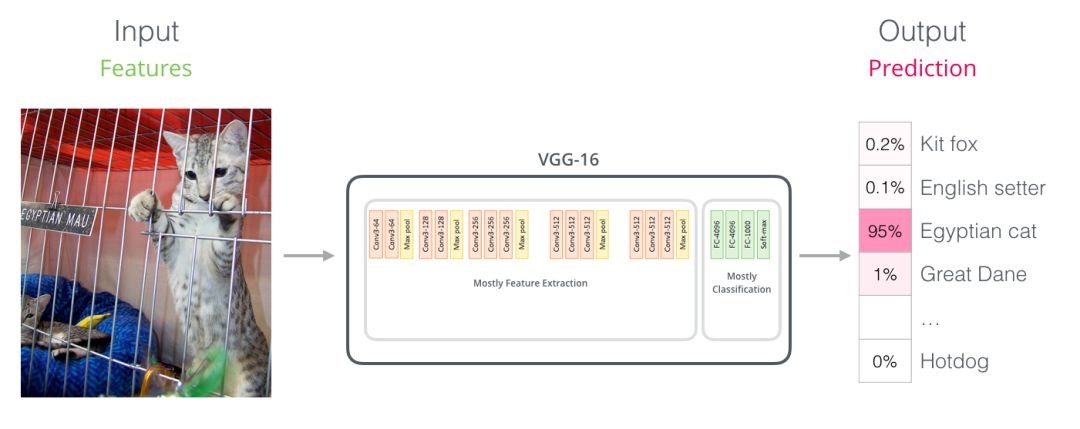
Parallels with Convolutional Nets (BERT VS Convolutional Neural Networks)
For those with a background in computer vision, this vector switch should remind you of what happens between the convolutional parts of networks like VGGNet and the fully connected classification part at the end of the network. You can understand it this way; it is essentially convenient to understand.
A New Era of Word Embeddings~
The open-sourcing of BERT has brought about an update in word embeddings. So far, word embeddings have become a major component for NLP models to handle natural language. Methods such as Word2vec and Glove have been widely used to address these issues. Before we use the new word embeddings, it is necessary to review their development.
A Review of Word Embeddings
To enable machines to learn the feature attributes of text, we need a way to numerically represent the text. The Word2vec algorithm represents words using a set of fixed-dimension vectors, and its calculation can capture the semantics of words and the relationships between words. Using the vectorized representation of Word2vec can be used to determine whether words are similar, opposites, or to assess the relationship between “man” and “woman” as being similar to “king” and “queen”. (Haven’t you heard this enough? ~ emmm essential for water articles). It can also capture some grammatical relationships, which is very useful in English. For example, the relationship between “had” and “has” is like the relationship between “was” and “is”.
With this approach, we can pre-train a word embedding model using a large amount of text data, and this word embedding model can be widely used for other NLP tasks. This is a good idea, allowing some startups or companies with insufficient computational resources to complete NLP tasks by downloading already open-sourced word embedding models.
ELMo: The Contextual Problem
The word embedding methods introduced above have a significant problem because they use pre-trained word vector models, which means that regardless of the contextual relationships, each word has a unique and fixed vector representation. “Wait a minute” – from (Peters et. al., 2017, McCann et. al., 2017, and yet again Peters et. al., 2018 in the ELMo paper)
This is actually similar to homophones in Chinese. Let’s take the character “长” as an example. In the term “长度” it represents measurement, while in “长高” it signifies increase. So why not determine its pronunciation or semantics based on whether “长” is surrounded by “度” or “高”? This question leads to contextualized word embedding models.
ELMo changes the way Word2vec classifies words into fixed-length vectors by looking at the whole sentence before assigning word vectors for each word, and it uses bi-LSTM to train the corresponding word vectors.
ELMo has made significant contributions to solving NLP’s contextual problems. Its LSTM can use a large amount of task-related text data for training and then use the trained model as a benchmark for word vectors in other NLP tasks.
What is the Secret of ELMo?
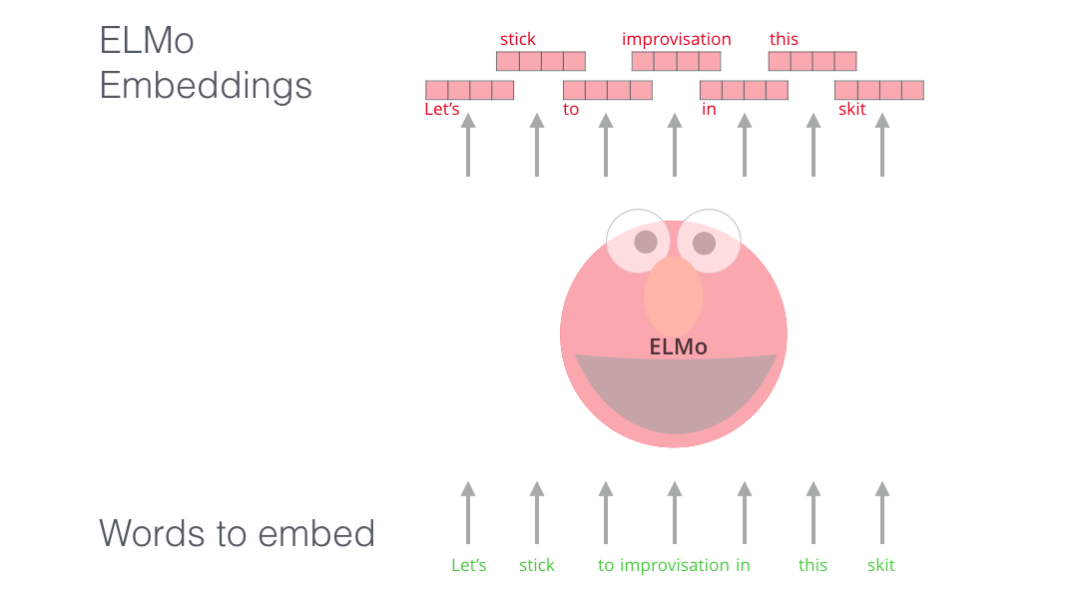
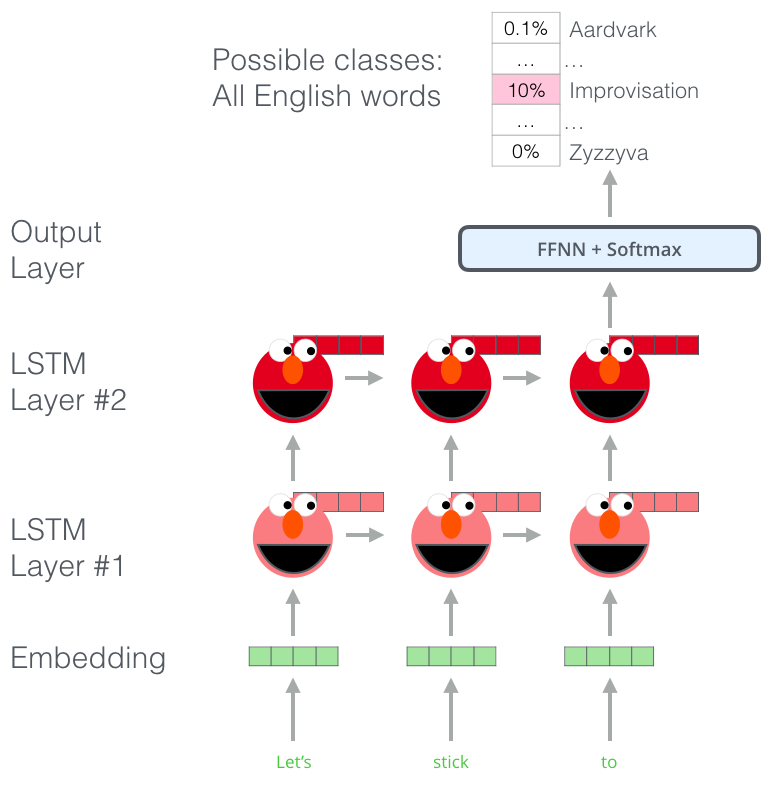
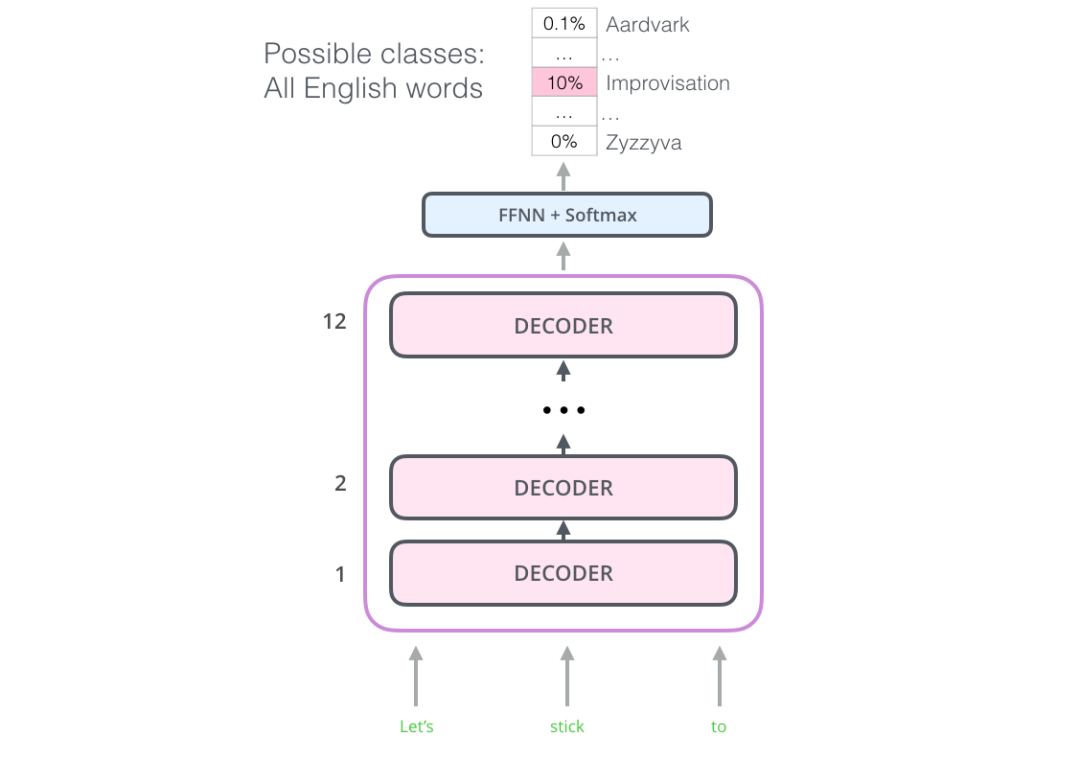
ELMo trains a model that accepts input of a sentence or word and outputs the most likely following word. Think about input methods; yes, it’s that principle. In NLP, we also refer to this as Language Modeling. This kind of model is easy to implement because we have a large amount of text data, and we can learn without needing labels.
The above figure introduces a part of the steps in the ELMo pre-training process: we need to complete a task like this: Input “Lets stick to”, predict the next most likely word. If trained with a large dataset during the training phase, we may accurately predict the next word we expect during the prediction phase. For example, if the input is “机器”, in “学习” and “买菜”, its most likely output would be “学习” rather than “买菜”.
From the above figure, we can see that each expanded LSTM completes the prediction at the last step.
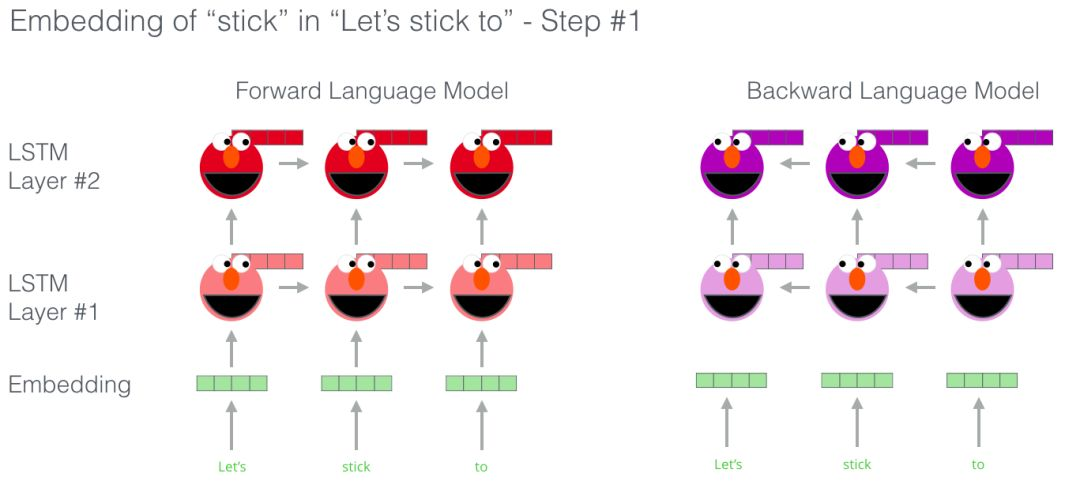
By the way, the real ELMo goes further; it can not only determine the next word but also predict the previous word. (Bi-LSTM)
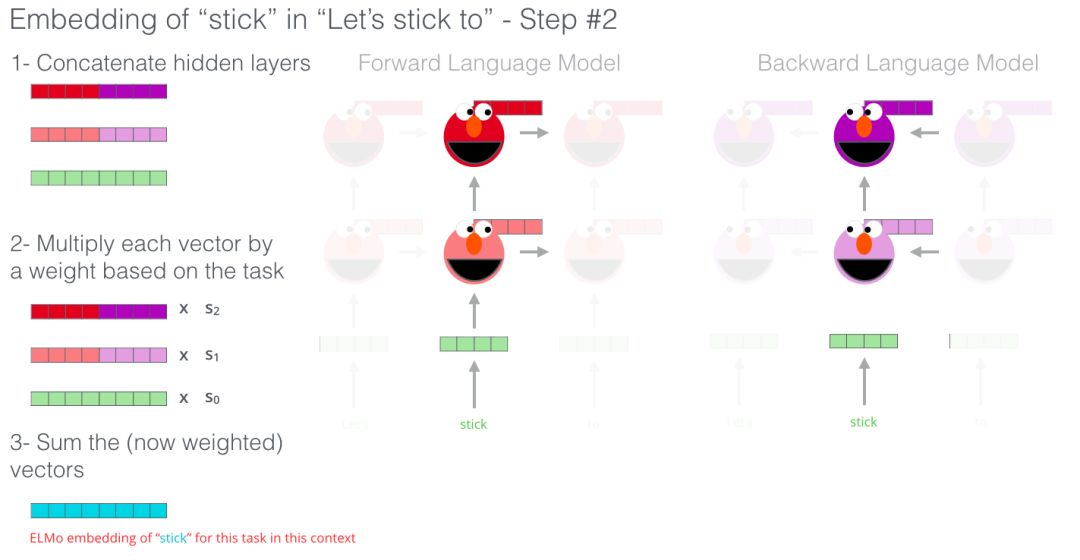
ELMo combines the initial hidden states (initial embeddings) in the manner shown in the figure below to refine the contextually meaningful word embeddings (weighted summation after full connection).
ULM-FiT: Transfer Learning in NLP Applications
The ULM-FiT mechanism allows for better utilization of the model’s pre-training parameters. The parameters used are not limited to embeddings or contextual embeddings; ULM-FiT introduces a Language Model and an efficient process for fine-tuning that Language Model to perform various NLP tasks. This enables NLP tasks to use transfer learning as conveniently as in computer vision.
The Transformer: A Structure Beyond LSTM
The release of the Transformer paper and code, along with its excellent results in tasks like machine translation, has led some researchers to believe it is a replacement for LSTM. In fact, the Transformer handles long-term dependencies better than LSTM. The structure of Transformer Encoding and Decoding is very suitable for machine translation, but how can we use it for text classification tasks? In fact, you only need to use it to pre-train a language model that can be fine-tuned for other tasks.
OpenAI Transformer: Transformer Decoder Pre-training for Language Models
It has been proven that we do not need a complete transformer structure to use transfer learning and a good language model to handle NLP tasks. We only need the decoder of the Transformer. The decoder is a good choice because it’s a natural choice for language modeling (predicting the next word) since it’s built to mask future tokens – a valuable feature when it’s generating a translation word by word.
This model stacks twelve decoder layers. Since there is no encoder in this setup, these decoders will not have the encoder-decoder attention layer that the Transformer decoder layers possess. Instead, there is a self-attention layer (masked so it doesn’t peek at future tokens).
Through this structural adjustment, we can continue training the model on similar language modeling tasks: using a large amount of unlabeled data to predict the next word. For example, you can feed your model 7000 books (books are excellent training samples~ much better than blogs and tweets). The training framework is as follows:
Transfer Learning to Downstream Tasks
Through the pre-training of OpenAI’s transformer and some fine-tuning, we can use the trained model for other downstream NLP tasks. (For example, training a language model and then using its hidden state for classification). Below is an introduction to this operation. (Still using the above example: dividing spam and non-spam)
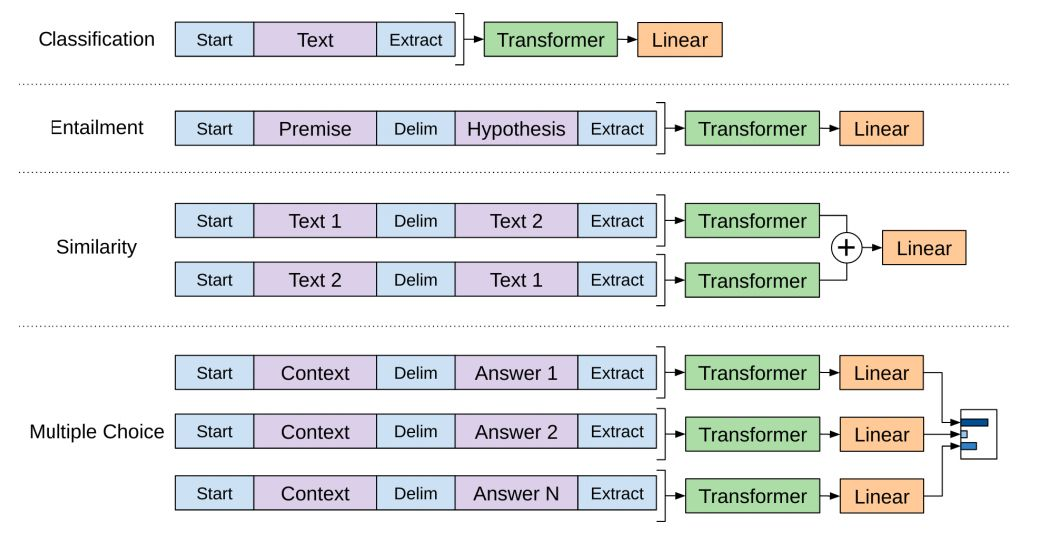
The OpenAI paper outlines many examples of using transfer learning with the Transformer to handle different types of NLP tasks. As shown in the figure below:
BERT: From Decoders to Encoders
The OpenAI transformer provides us with a sophisticated pre-trained model based on the Transformer. However, in the transition from LSTM to Transformer, we found that something was missing. The language model of ELMo is bidirectional, but the OpenAI transformer is a unidirectional language model. Can we also give our Transformer model the characteristics of Bi-LSTM?
BERT says: “I will use the encoders of the transformer”
Ernie scoffs: “Heh, you can’t consider the article like Bi-LSTM”
BERT confidently replies: “We will use masks”
The language model predicts the next word based on the previous words, but the attention of self-attention only focuses on itself, making it 100% predictable of itself, which is meaningless. So, we use a mask to block the words that need to be predicted.
As shown in the figure below:
Let’s review how the OpenAI transformer processes input transformations for different tasks. You will find that for certain tasks, we need two sentences as input and make some more intelligent judgments, such as whether they are similar. For example, providing a Wikipedia entry as input and simultaneously inputting a question regarding that entry; can our algorithm model handle this question?
To enable BERT to better handle the relationship between two sentences, the pre-training process includes an additional task: Given two sentences (A and B), are A and B similar? (0 or 1)
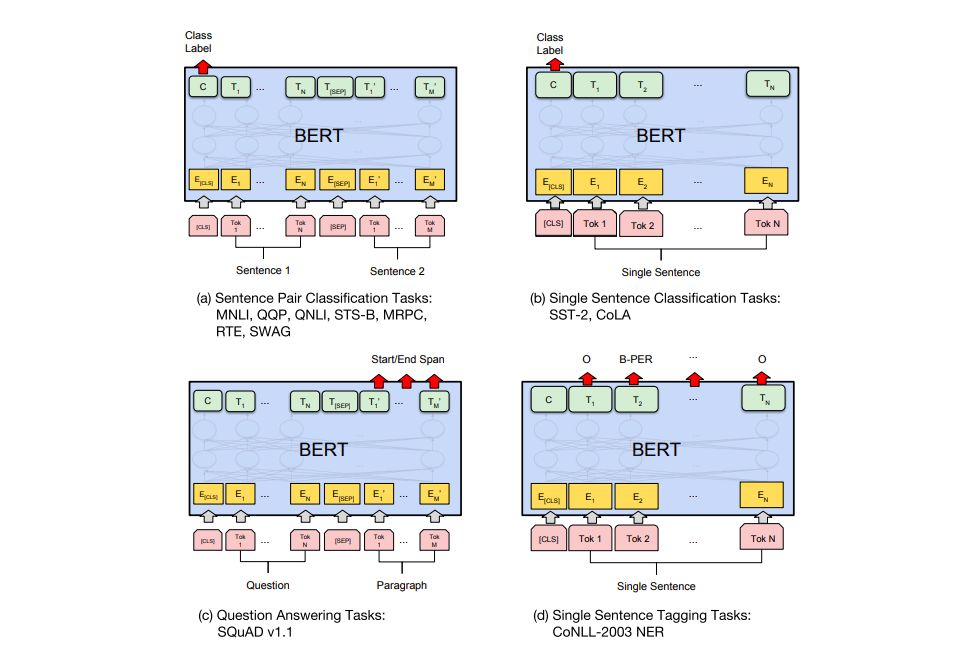
The BERT paper introduces several NLP tasks that BERT can handle:
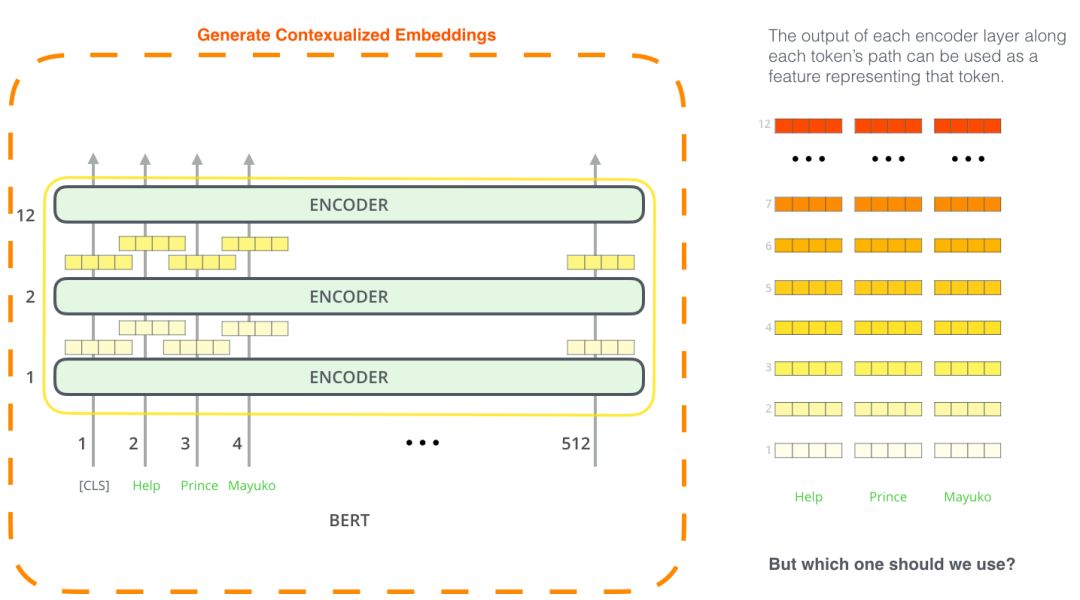
BERT as Feature Extractor
The fine-tuning method is not the only way to use BERT. Like ELMo, you can use the pre-trained BERT to create contextualized word embeddings. You can then provide these embeddings to existing models.
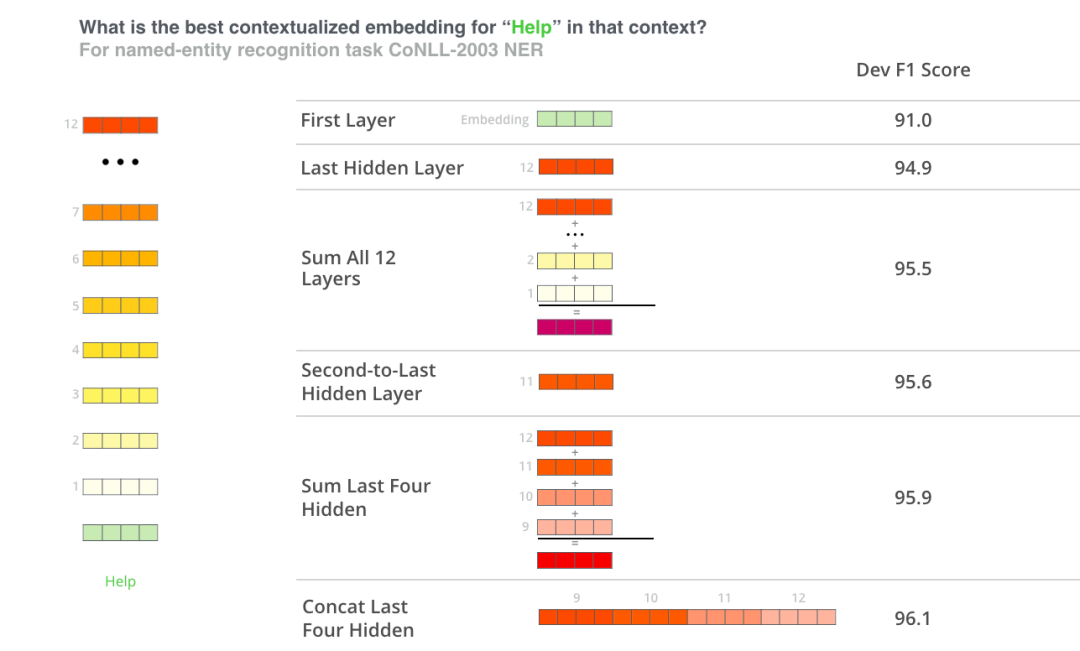
Which vector is most suitable as context input? I think it depends on the task. This article examines six options (with a score of 96.4 compared to fine-tuned models):
The best way to use BERT is through BERT Fine-Tuning with Cloud TPUs hosted on Google Cloud (https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb).
If you have never used Google Cloud TPU, you should give it a try; it’s a good experience. Additionally, BERT is also applicable to TPU, CPU, and GPU.
The next step is to check the code in the BERT repository:
1. The model is constructed in modeling.py (BertModel class), which is identical to the vanilla Transformer encoder.
(https://github.com/google-research/bert/blob/master/modeling.py)
2. run_classifier.py is an example of the fine-tuning process. It also constructs the classification layer of the supervised model.It also constructs the classification layer of the supervised model.
(https://github.com/google-research/bert/blob/master/run_classifier.py)
If you want to build your classifier, check the create_model() method in that file.
3. Several pre-trained models can be downloaded.
Multilingual models covering 102 languages, all trained on Wikipedia data.
BERT does not treat words as tokens. Instead, it focuses on WordPieces.
tokenization.py is the tokenizer that converts your words into suitable word pieces for BERT.
(https://github.com/google-research/bert/blob/master/tokenization.py)
You can also check the PyTorch implementation of BERT.
(https://github.com/huggingface/pytorch-pretrained-BERT)
The AllenNLP library uses this implementation to allow BERT embeddings to be used with any model.
(https://github.com/allenai/allennlp)
(https://github.com/allenai/allennlp/pull/2067)