MLNLP(Machine Learning Algorithms and Natural Language Processing) community is one of the largest natural language processing communities in China and abroad, gathering over 500,000 subscribers, with an audience covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning enthusiasts both domestically and internationally.
Source | The Algorithm House of Dialogue
Hello everyone, I am Dialogue.
BERT has been widely implemented in the industry, mainly applied in search, recommendation, and NLP. I will summarize my insights on using BERT as follows:
-
The Implementation of BERT in the Industry: New data pre-training, multi-tasking, distillation/cropping, and online applications of dual towers;
-
How to distill models;
-
What are the effective improvements based on BERT;
-
How to integrate knowledge graphs;
-
Relevance Framework: Considering business effectiveness, necessary pre/post rules may be effective; solving unrelated issues in two stages, as well as distinguishing between highly relevant and generally relevant;
-
Multiple Business Scenarios;
Next, let’s take a look at how companies like Alibaba, Meituan, and Baidu apply BERT in their businesses to enhance business metrics.

Industry Practices
Baidu – ERNIE
Paper: ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
GitHub: http://github.com/PaddlePaddle/ERNIE
Improvements: Introducing knowledge, using a MASK word and entity method based on BERT, learning the global signal of this word or entity in the sentence.
After BERT was proposed, we found an issue: it still learned the basic language unit’s Language Model and did not fully utilize prior language knowledge, which is particularly evident in Chinese. Its strategy is to MASK words, without MASKing knowledge or phrases. When predicting each character using the Transformer, it is easy to predict based on the collocation information of the words containing the character. For example, predicting the character “snow” does not require global information; it can be predicted using the character “ice.” Based on this assumption, we made a simple improvement, turning it into a MASK word and entity method to learn the global signal of this word or entity in the sentence.
Based on the above ideas, we released knowledge-enhanced semantic representations ERNIE (1.0).
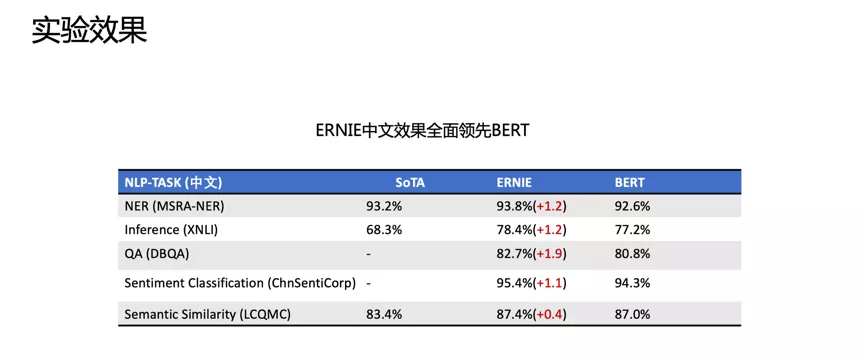
It was verified in English, and experiments showed that ERNIE (1.0) significantly improved performance on GLUE and SQuAd1.1. To verify the hypothesis, we conducted some qualitative analyses, found a cloze dataset, and predicted using ERNIE and BERT, as shown in the figure above.
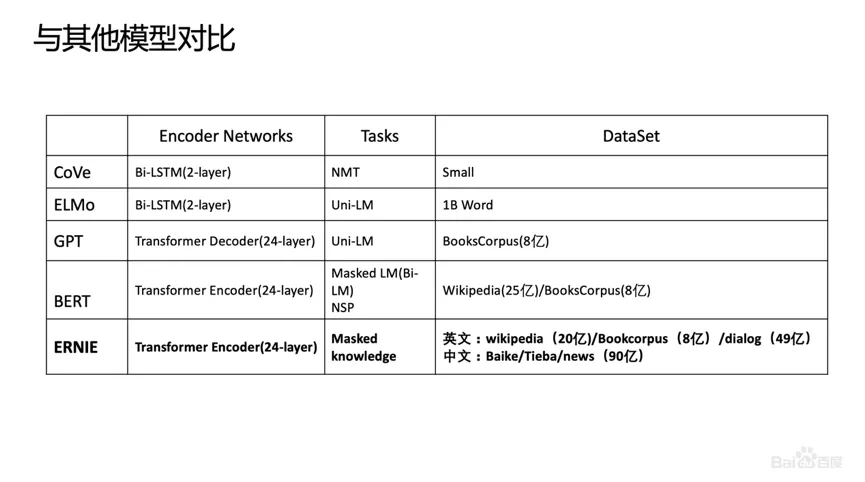
We compared ERNIE, BERT, CoVe, GPT, and ELMo models, and the results are shown in the figure above. ELMo is an early work on context-aware representation models, but it did not use Transformer; it used LSTM to learn through a unidirectional language model. Baidu’s ERNIE, like BERT and GPT, uses a Transformer, but ERNIE made some improvements when modeling tasks and achieved very good results.
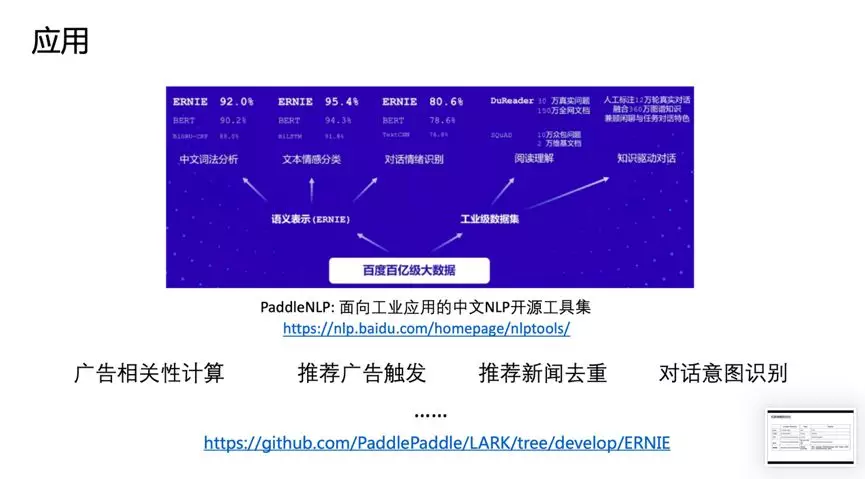
In application, ERNIE was verified in Baidu’s open-source toolset for Chinese NLP for industrial applications, including a comparative analysis of ERNIE and BERT on internal tasks such as lexical analysis and sentiment classification. Some products have already been implemented in areas such as advertising relevance calculation, triggering recommended ads, and news recommendations.
Later, Baidu ERNIE was upgraded, releasing a continual learning semantic understanding framework ERNIE 2.0, and leveraging the efficient training advantages of PaddlePaddle to release the ERNIE 2.0 pre-training model based on this framework. This model surpassed BERT and XLNet on a total of 16 Chinese and English tasks, achieving SOTA results.
Alibaba Entertainment – Poly Encoders
Paper: Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
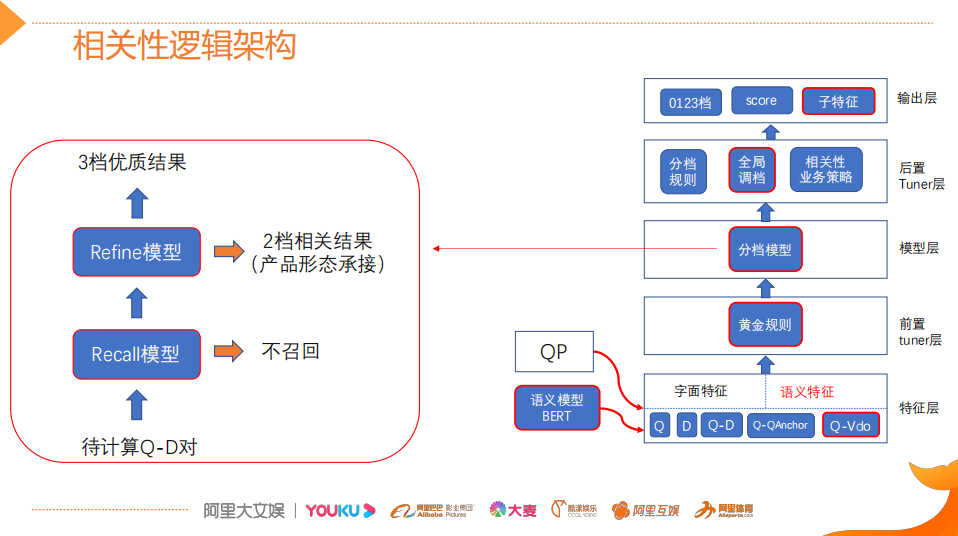
Relevance Logic Architecture:
Pre-tuner layer: Mainly includes some golden rules that have an accuracy rate exceeding 95% on the training set. When these conditions are met, no model processing is performed, and it is processed directly through rules.
Model layer: When golden rules cannot handle it, a tiered model is used as a fallback. The tiered model contains two sub-models, the Recall model and the Refine model. The two models have the same structure, but they use different features and sample selections. The advantage of the tiered model is that it decouples the functionality of the entire relevance tiering, one is used to discover high-relevance quality documents, and the other is used to reduce irrelevant deviations and perform filtering.
Post-tuner layer:This layer adds some manual fallback rules to supplement cases where the model did not learn due to uneven sample data or missing core features. For example, rules were created for understanding video content features. This layer also includes a global tuning Tuner, which adjusts based on global DOC matching.
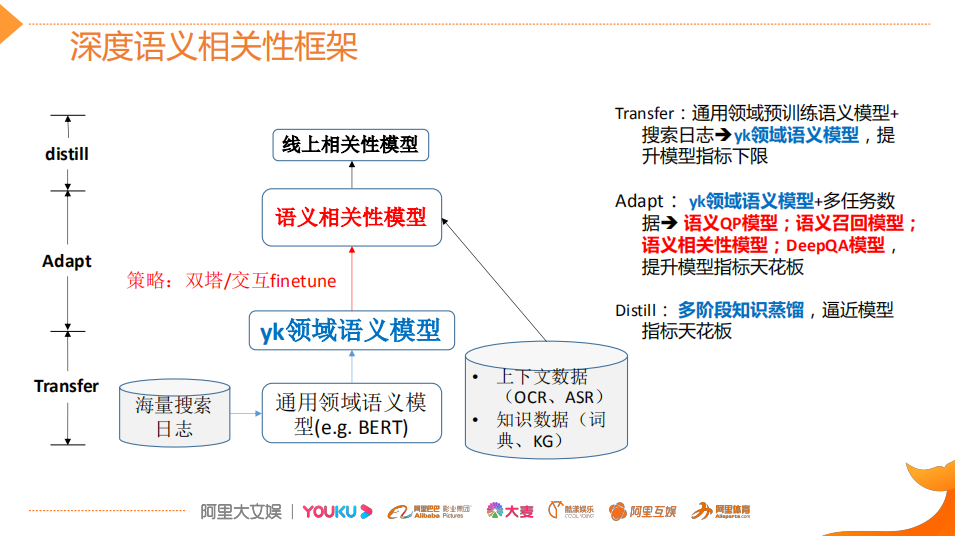
Common Three Steps for BERT Implementation in the Industry
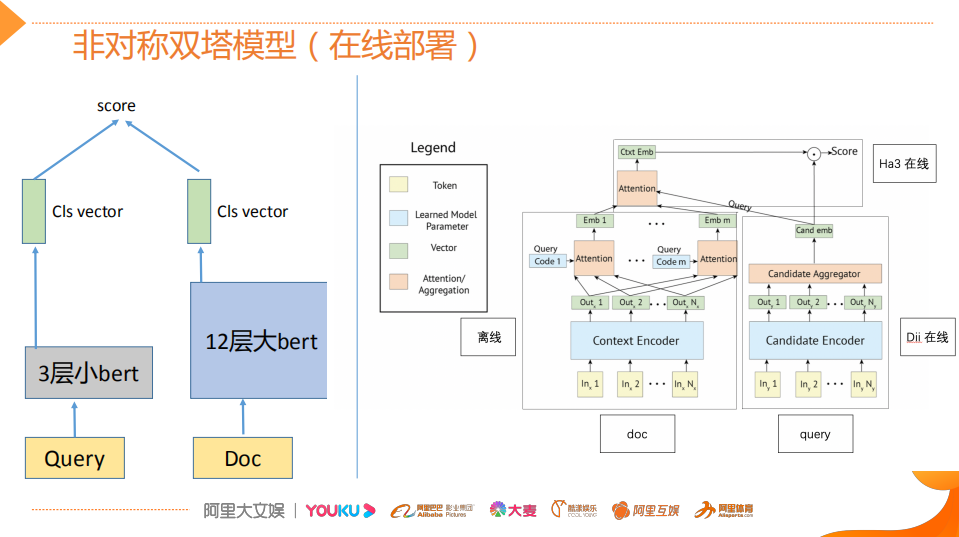
Asymmetric Dual Tower Model (Online Deployment)
If you directly change from interactivity (12-layer BERT) to dual towers (2 12-layer BERTs), the metrics drop significantly.
-
Doc (offline): In order to reduce the metric degradation of the dual tower model, the Doc side does not save a single embedding; instead, it saves M groups of embeddings, which can be understood as depicting the features of the Doc from M perspectives, maximizing the retention of rich information on the Doc side;
-
Query (online): Three-layer BERT, but it will also lead to metric degradation;
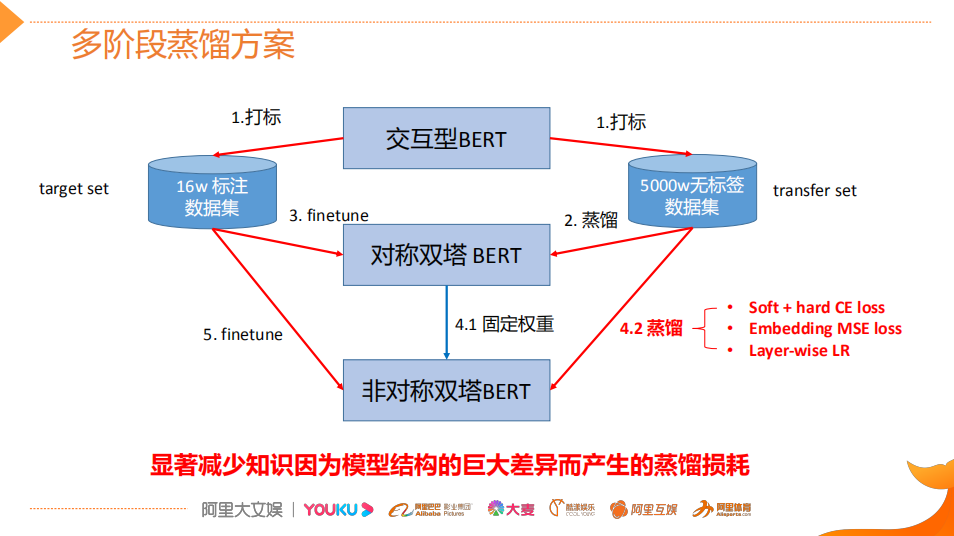
Multi-stage Distillation Model
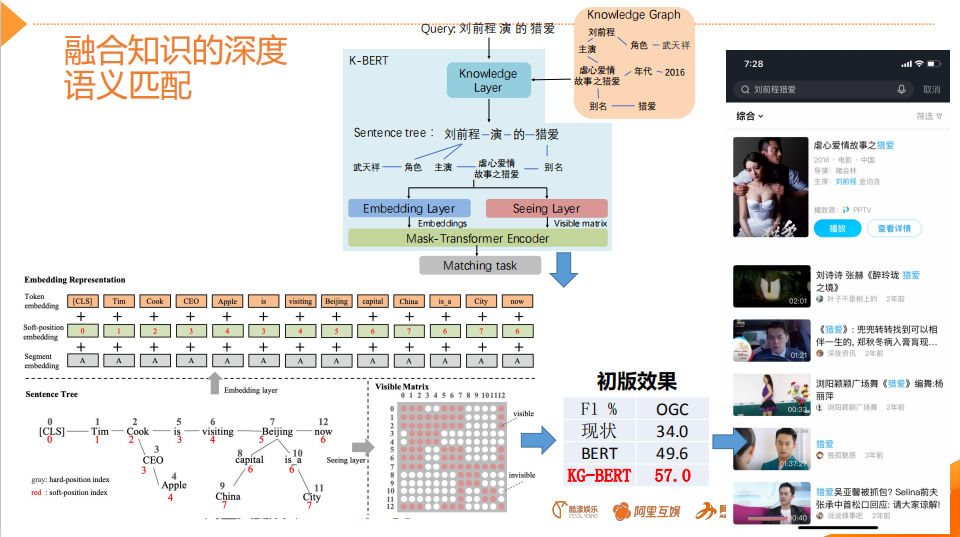
Deep Semantic Matching with Knowledge Integration
-
For queries, query the KG to find its subgraph, then encode the structured information of the subgraph into BERT’s universal serialized input, and then perform some attention supervision operations between the KG layer and the text layer.
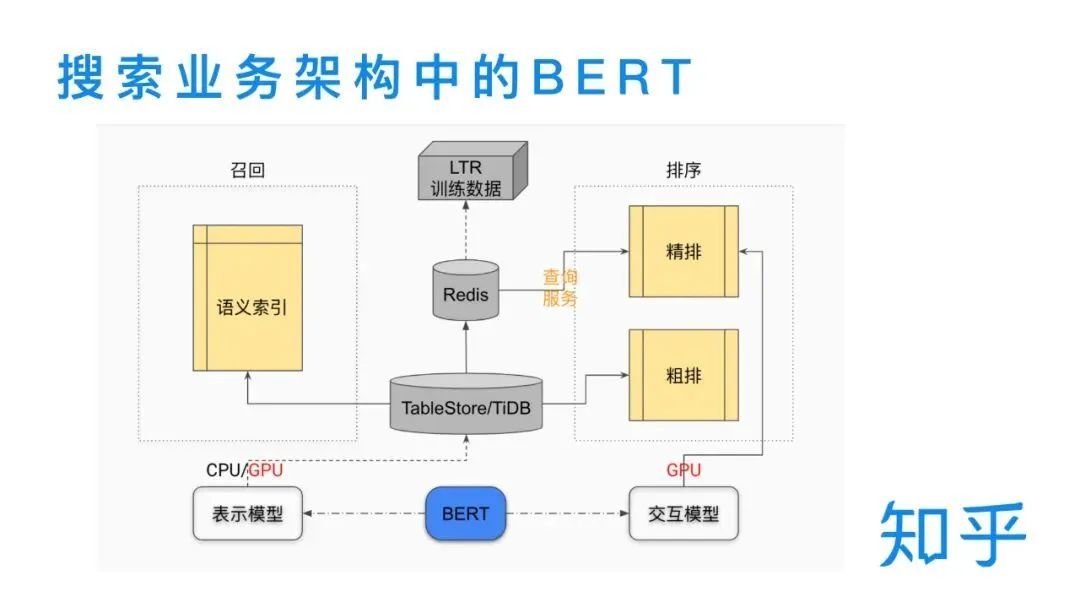
Zhihu – Search Text Relevance and Knowledge Distillation
Interactive BERT: Used for fine ranking
Representation BERT: Used in recall and coarse ranking, adopting the average of the BERT output token sequence vector as the sentence vector representation
Recall:The semantic recall model is an application of the dual tower representation model in the BERT relevance task. BERT serves as an encoder to represent queries and documents in vector form, constructing a semantic index for all document vectors based on faiss, and recalling in real-time using query vectors.
Next, I will introduce Zhihu’s semantic recall model in detail. First, let’s look at an example. For the case of “Maserati ghlib,” the user actually wants to search for the car “Maserati Ghibli,” but users generally find it challenging to remember the complete name and may make mistakes. In the case of a mistake, traditional term matching methods (like Google Search) can only recall documents related to “Maserati” and fail to recall this car model. In such scenarios, semantic recall is necessary. More generally, semantic recall can be understood as recalling documents that are semantically relevant but not literally matching.
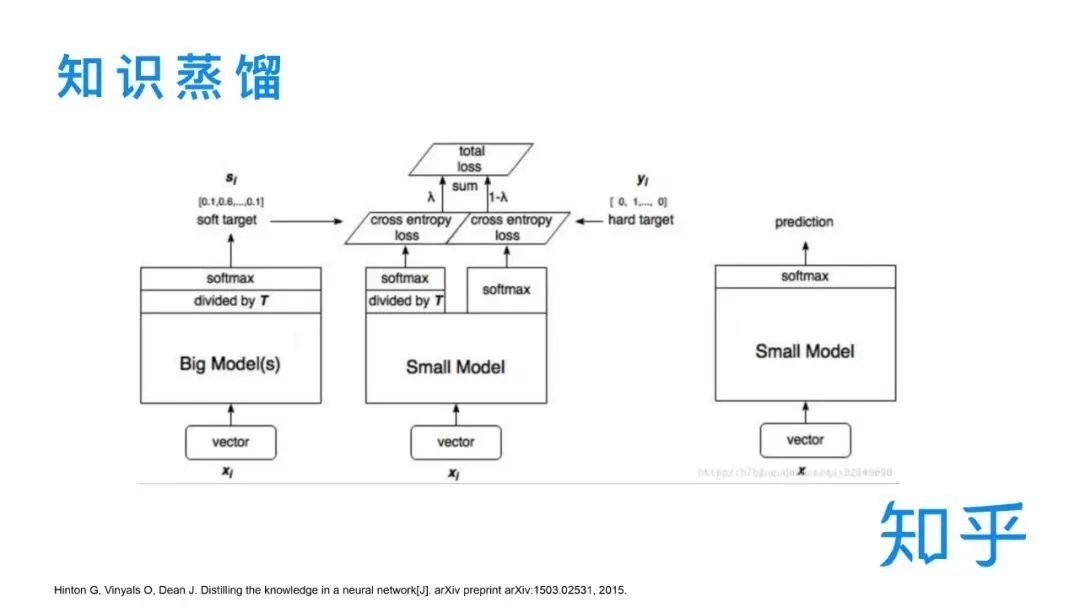
For BERT distillation, we conducted extensive research and summarized the current mainstream distillation schemes. From the task dimension, it mainly corresponds to the current pretrain + fine-tune two-stage training. Many schemes involve both the pre-training phase and the downstream task phase. In terms of techniques, it mainly includes different transfer knowledge and model structure designs. Later, I will briefly introduce two typical models.
The benefits of distillation are mainly divided into online and offline parts.
The number of layers in the interactive model is compressed from 12 layers to 6 layers, the relevance feature P95 is reduced to half, the overall search entry drops by 40ms, and the number of GPU machines required for model deployment is also halved, reducing resource consumption.
The storage scale of the semantic index for the representation model reduces the title dimension to 1/4, and the content dimension is compressed from 768 dimensions to 64 dimensions. Although the dimension is reduced by 12 times, the number of inverted index documents has increased, so the content ultimately reduces to 1/6, and there is also a significant improvement in semantic index recall, with the title reducing to 1/3 and content reducing to 1/2. The fine ranking module requires online real-time queries of offline calculated vectors, so the query service has also improved.
The construction time of the semantic index for the representation model is reduced to 1/4, and the self-developed TableStore/TIDB storage of Zhihu is reduced to 1/6 of the original. The training data and training time for LTR have significantly improved, and the early coarse ranking used basic features like BM25, later introducing 32-dimensional BERT vectors, improving fine ranking accuracy.
Meituan – Core Sorting of BERT Search
In the core search for “core sorting,” it is distilled into a 2-layer interactive BERT, and the predicted query-poi relevance score is used as a feature for sorting.
-
Using order data as positive samples, constructing negative samples from data that has not been clicked.
-
Skip-Above sampling: Due to the display screen effect of the App search scenario, it is impossible to ensure that the recalled POI is exposed all at once. If we directly use the unclicked POIs as negative examples, we may mistakenly sample unexposed but relevant POIs as negative examples. To ensure the accuracy of the training data, we adopt the Skip-Above method to eliminate these noisy negative examples, that is, sampling negative examples from unclicked POIs above the POIs clicked by the user (assuming the user browses POIs from top to bottom).
Introducing category information:
-
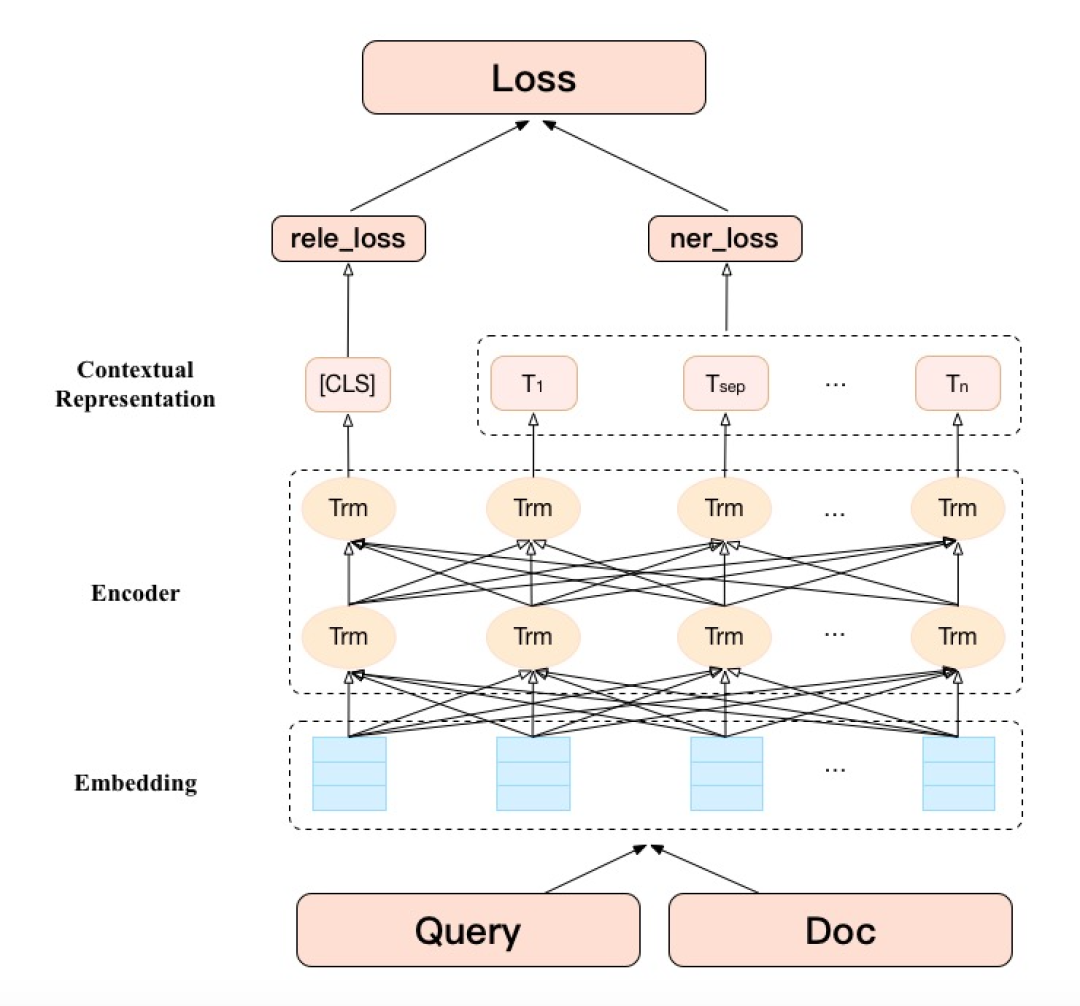
For the model input part, we concatenate Query, Doc title, and three-level category information, and use [SEP] to separate them, distinguishing three different sources of information. For segment vectors, the original BERT only has two types of segment encodings EA and EB, and after introducing category information, an additional segment encoding Ec is introduced. The purpose of introducing additional segment encoding is to prevent additional information from interfering with the Query and Doc title. Since we changed the input and output structure of BERT, we cannot directly perform relevance fine-tuning tasks based on MT-BERT. We made corresponding improvements to the pre-training method of MT-BERT, one of the pre-training goals of BERT is NSP (Next Sentence Prediction), which has no concept of preceding and following sentences in the search scenario. Given the user’s search keywords and merchant text information, we judge whether the user clicks to replace the NSP task.
Introducing entity task recognition, multi-task fine-tuning
-
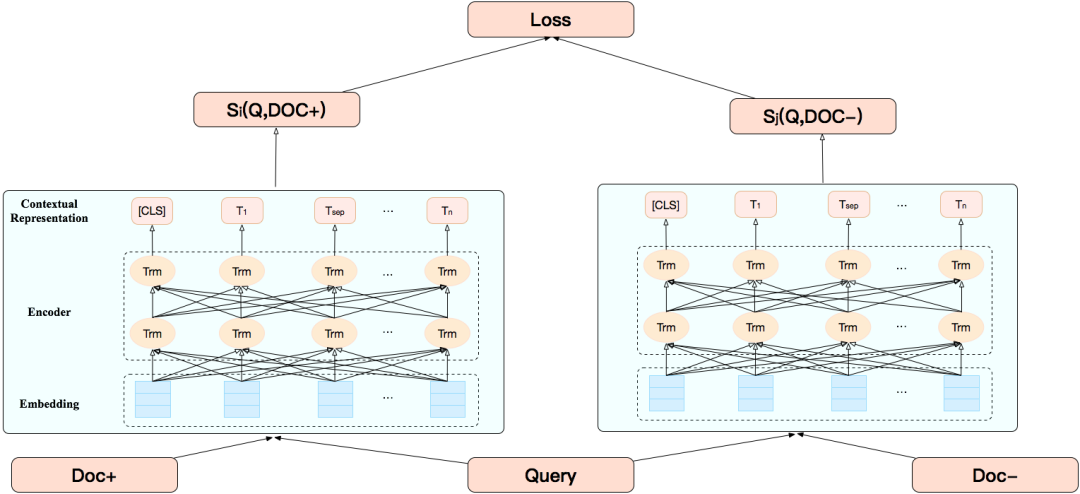
Sample: A single sample is a triplet <Query, Doc+, Doc–>;
-
Loss: In addition to the changes in the input samples, to consider the ordinal relationship between different samples in the search scenario, we optimized the training loss function by referring to RankNet[34].
Partition-model, multi-business issues
-
The idea of the Partition-model is to use all data for joint training across all scenarios while retaining specific characteristics of each scenario to solve the sorting problem of multiple business scenarios.
Loss function: The optimized NDCG Lambda Loss is selected.
-
Trimming, distilling, low-precision quantization.
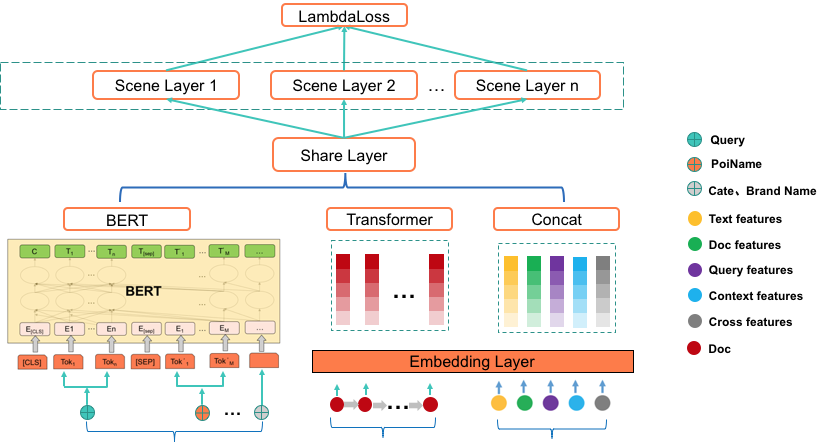
Alibaba Xianyu – Search Relevance
Feature Construction
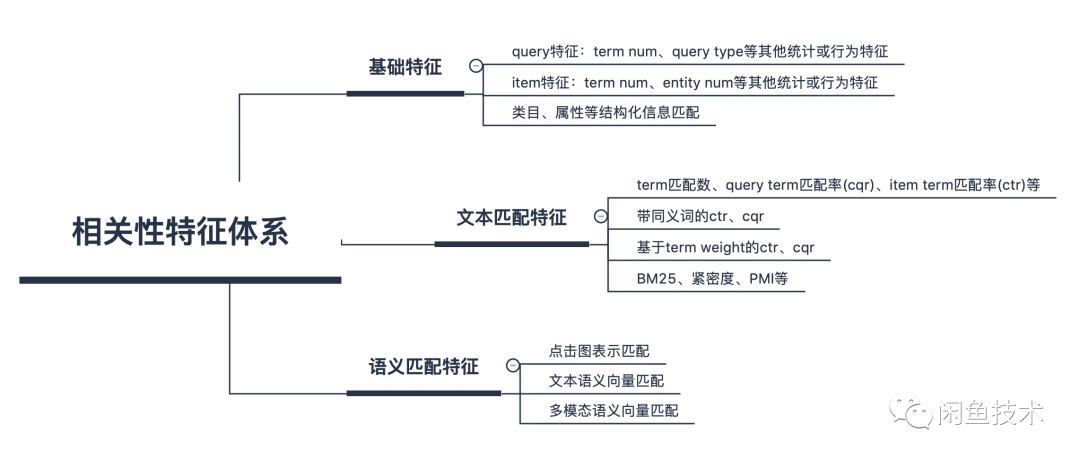
The features of search relevance are divided into three dimensions: basic features, text matching features, and semantic matching features. Basic features mainly include statistical features of the query and item, as well as structured matching features related to whether categories match, whether key attributes (category, brand, model, etc.) match. Text matching features mainly include literal matching features, such as the number of term matches, matching rates, matches with synonym strategies, matches with term weights, and the most basic BM25 scores.
Search relevance features
Among them, basic features and text matching features are relatively conventional and will not be elaborated further. Below, we will focus on further introducing semantic matching features:
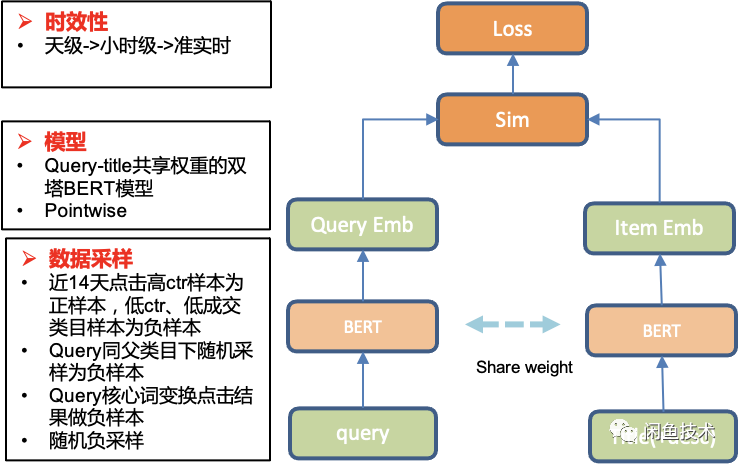
Text Semantic Matching
For performance considerations, the text semantic matching adopts a dual-tower vector matching model structure: the basic model uses open-source BERT, and the Query and Item share the same parameter weights. At the same time, to adapt to the downstream relevance tiering, the model adopts a Pointwise training method. Due to space constraints, the details of the model will not be elaborated. However, compared to the design of the model structure, the more important work in Xianyu search is the construction of training samples. Due to the current lack of accumulation of manually labeled data, the current work mainly addresses the following two issues:
• High-confidence sample mining to alleviate the issue of “clicked but irrelevant” in search click logs.
• Customized negative sample construction to avoid the model converging too quickly, only able to judge simple semantic relevance, while being unable to distinguish the difficult cases of “marginally relevant” mentioned above in the Xianyu scenario.
To address the above issues, we referenced the relevant experience of the group and combined observations and analyses of Xianyu search data to create the following sampling scheme:
• Sufficiently exposed high click CTR samples (CTR greater than the average click rate of items under the same query)
• Neighboring leaf category negative sampling from the same parent category.
• High exposure low click category samples: Under the same query search, based on the category distribution of clicked items, take relatively infrequent category samples as negative samples (e.g., items with category distribution ratio < 0.05 are treated as negative samples).
• Under sufficient exposure, samples that are less than 10% of the corresponding query’s average exposure click rate are treated as negative samples.
• Construct negative samples by replacing core terms based on the query: for example, for a query structured as “Brand A + Category,” use a query structured as “Brand B + Category” as its negative sample.
• Randomly constructed negative samples: To increase randomness, this part is implemented by using other samples in the same batch as negative samples during training, while introducing a batch hard sample mechanism.
The training data sampled using the above methods showed a random accuracy of over 90%, and after further sampling, the scale reached over 40,000. Based on this, we trained a dual-tower model, with the online method being offline extraction of embeddings, online lookup, and calculation of vector similarity.
This part of the work was independently launched in full, with random sampling of the top 300 queries + 200 random queries showing a satisfaction increase of +6.6%; similarly, the text semantic vector was reused in the i2i vector recall, repurposed for the Xianyu procurement scenario, with a core engagement metric increase of 20.45%.
Defining the top 10 products in search queries as completely relevant/basically relevant accounts for >80% satisfaction, with a group of query evaluation results being considered satisfactory if the proportion of queries deemed satisfactory is high.
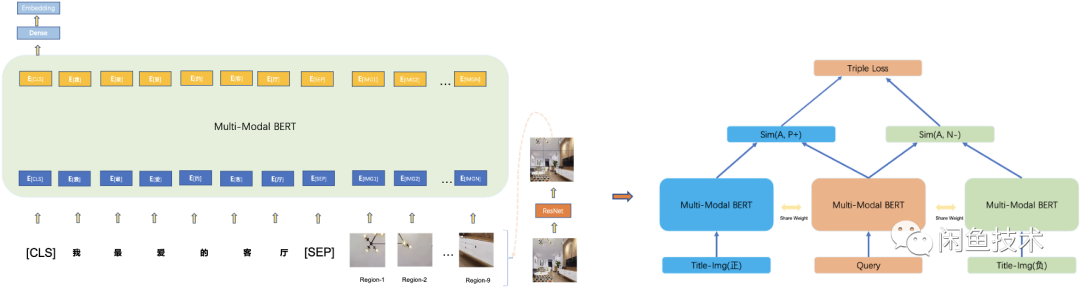
Multi-modal Semantic Matching
In addition to text semantic vector matching, this work also attempted multi-modal semantic vectors. The model side uses pre-trained multi-modal BERT. Similar work has been extensively attempted by the group, and this article mainly references ([1],[2]), making some adjustments to the model and strategy:
• Replacing multi-image feature extraction with primary image region feature extraction to create image feature sequences (feature sequences before resnet pooling), enhancing link efficiency;
• Replacing Bert-base with Electra-small to reduce model parameters (tested a 47M model with a downstream classification task accuracy loss of less than 2 points), facilitating end-to-end training with Resnet.
The downstream matching task still uses the dual-tower model strategy, and unlike the text semantic model, here a Triple Loss method is directly employed, mainly to increase the difference between models, allowing for greater room for subsequent model fusion.
Multi-modal Semantic Model
PS: The offline AUC for this part of the work is relatively high at 0.75, with an increase of over 1 point in AUC for downstream feature fusion. However, during the online process, due to the need for image processing, the incremental product feature update backflow is relatively delayed compared to other links, which easily leads to the loss of new product features, thus requiring further link optimization.
Click Graph Representation Matching
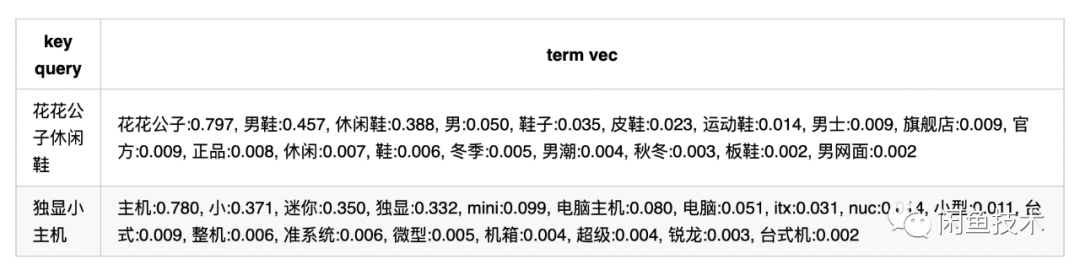
In addition to the semantic information introduced through semantic vectors mentioned above, we can also leverage the click behavior represented in search logs to construct a graph structure to introduce new semantic representations for queries or items. Among them, the graph-based matching algorithm SWING is widely used internally at Alibaba, and there are many relevant articles, which will not be elaborated here. For the Xianyu scenario, we first transformed the <user, item> click pair into <item, query> click pair, allowing us to directly use the existing swing tool to obtain a list of query2query. Aggregate all similar queries for the key query, perform tokenization, weight all terms, and after normalization, obtain the representation of the key query.
The weights are the scores output by the swing algorithm, and the default weight for the key query’s terms is 1. For long-tail queries with sparse behavior, we use the previously mentioned semantic vector recall to find the nearest head query to supplement its semantic representation. The final obtained query representation example:
After obtaining the query representation, the item similarly undergoes a similar normalization representation. During the online phase, sparse storage is utilized to calculate the weighted sum of matching terms as the click graph representation matching score.
After preparing the necessary relevance features, the next step is to effectively fuse the numerous features. This article uses the classic GBDT model to complete this step. The advantage of choosing the GBDT model is that one, the retrieval engine (Ha3) fine-ranking scoring plugin has existing components that can be reused directly, and two, compared to simpler LR models, it can save many feature preprocessing steps, making online strategies simpler.
The model training uses manually labeled training data, with the labeling target being four levels (completely relevant, basically relevant, marginally relevant, and completely irrelevant). During the training phase, the four levels are mapped to 1, 0.75, 0.25, and 0, respectively, and the GBDT model fits these quantiles through regression. Since this part of the strategy is an ensemble of sub-features, it does not require a large amount of training data (here the scale is on the order of tens of thousands).
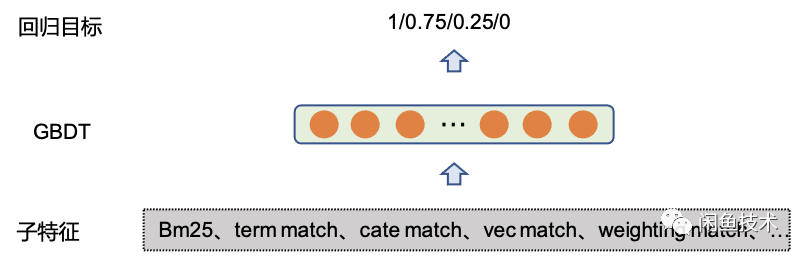 Finally, after regular parameter tuning, the offline AUC of the GBDT feature fusion model can reach 0.86, basically meeting expectations (the optimal single feature AUC is 0.76). This strategy is fully online, and based on the text semantic vector, without affecting transaction efficiency: random query sampling (top 8 million) DCG@10 increased by 6.51%, and query search satisfaction increased by 24%; head queries also saw corresponding improvements, and the overall search experience was effectively enhanced.
Finally, after regular parameter tuning, the offline AUC of the GBDT feature fusion model can reach 0.86, basically meeting expectations (the optimal single feature AUC is 0.76). This strategy is fully online, and based on the text semantic vector, without affecting transaction efficiency: random query sampling (top 8 million) DCG@10 increased by 6.51%, and query search satisfaction increased by 24%; head queries also saw corresponding improvements, and the overall search experience was effectively enhanced.
Technical Exchange Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name – School/Company – Research Direction
(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue System)
to apply to join Natural Language Processing/Pytorch, etc. technical exchange group
About Us
MLNLP(Machine Learning Algorithms and Natural Language Processing) community is a grassroots academic community jointly established by domestic and foreign natural language processing scholars. It has now developed into one of the largest natural language processing communities in China and abroad, gathering over 500,000 subscribers, and includes well-known brands such as Ten Thousand People Top Conference Exchange Group, AI Selection Exchange, AI Talent Exchange, and AI Academic Exchange, aimed at promoting progress among the academic and industrial sectors of machine learning and natural language processing enthusiasts.
The community can provide an open exchange platform for related practitioners in further education, employment, and research. Everyone is welcome to follow and join us.