Source: Deephub Imba
This article is about 1500 words long and takes about 5 minutes to read.
In this article, we want to demonstrate how to use the pre-trained weights of an encoder-only model to provide a good starting point for our fine-tuning.
BERT is a famous and powerful pre-trained encoder model. Let’s see how to use it as a decoder to form an encoder-decoder architecture.
The Transformer architecture consists of two main building blocks—an encoder and a decoder—which we stack together to form a seq2seq model. Training a Transformer-based model from scratch is usually challenging because it requires large datasets and high GPU memory. We can use many pre-trained models with different objectives.
First, encoder models (such as BERT, RoBERTa, FNet, etc.) learn to create fixed-size feature representations from the text they read. This representation can be used to train networks for tasks like classification, translation, summarization, etc. Decoder-based models with generative capabilities (like the GPT series) can predict the next token by adding a linear layer on top (also known as a “language model head”). Encoder-decoder models (like BART, Pegasus, MASS, …) can adjust the decoder’s output based on the encoder’s representation. This is accomplished through cross-attention connections from the encoder to the decoder.
In this article, we want to demonstrate how to use the pre-trained weights of an encoder-only model to provide a good starting point for our fine-tuning. We will use BERT as both the encoder and decoder to train a summarization model.
Huggingface’s new API allows us to mix and match different pre-trained models. This makes our work super simple! But before we dive into the code, let’s take a look at the concept. What should be done to make BERT (the encoder model) work in seq2seq?
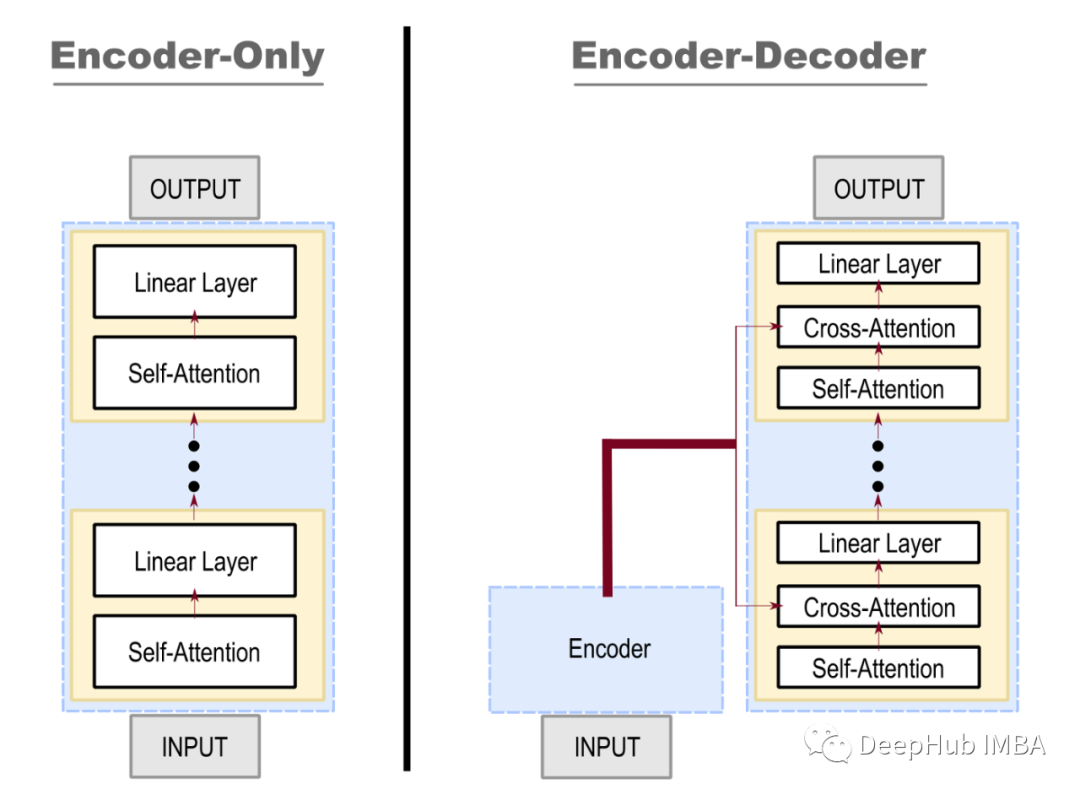
For simplicity, we removed other elements of the network in the diagram! For a simple comparison, each block (layer) of the encoder-only model (left) consists of a self-attention and a linear layer. Meanwhile, the encoder-decoder network (right) has a cross-attention connection at each layer. The cross-attention layer allows the model to adjust predictions based on the input.
It is impossible to use the BERT model directly as a decoder because the building blocks are different, but leveraging the weights of BERT makes it easy to add additional connections and build the decoder part. Once built, the model needs to be fine-tuned to train these connections and the weights of the language model head. (Note: The position of the language model head is between the output and the last linear layer—it is not included in the diagram above.)
We can use Huggingface’s EncoderDecoderModel object to mix and match different pre-trained models. It will handle the addition of necessary connections and weights by specifying the encoder/decoder models through the .from_encoder_decoder_pretrained() method. In the example below, we use BERT base as both the encoder and decoder.
from transformers import EncoderDecoderModel
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased",
"bert-base-uncased")
Since the BERT model is not designed for text generation, we need to make some additional configurations. The next step is to set up the tokenizer and specify the beginning and end tokens.
from transformers import BertTokenizerFast
# Set tokenizer
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
tokenizer.bos_token = tokenizer.cls_token
tokenizer.eos_token = tokenizer.sep_token
# Set model's config
bert2bert.config.decoder_start_token_id = tokenizer.bos_token_id
bert2bert.config.eos_token_id = tokenizer.eos_token_id
bert2bert.config.pad_token_id = tokenizer.pad_token_id
Now we can fine-tune the model using the Seq2Seq Trainer object from Huggingface with the Seq2SeqTrainingArguments() parameters. Many configurations can be changed and tried here to find the best parameter combination for the model. Note that the following values are not optimal choices and are only for testing! If GPU memory is limited, the fp16 value is very important. It will reduce memory usage by using half precision. Other useful variables to explore include learning_rate, batch_size, etc.
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
training_args = Seq2SeqTrainingArguments(
output_dir="./",
learning_rate=5e-5,
evaluation_strategy="steps",
per_device_train_batch_size=4,
per_device_eval_batch_size=8,
predict_with_generate=True,
overwrite_output_dir=True,
save_total_limit=3,
fp16=True,
)
trainer = Seq2SeqTrainer(
model=bert2bert,
tokenizer=tokenizer,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=val_data,
)
trainer.train()
The training results are as follows:
The performance of the BERT-to-BERT model fine-tuned on the CNN/DM dataset. I used the Beam Search decoding method. The results were calculated using the ROUGE scoring metric.
The BART model is the SOTA model in text summarization, and the performance of BERT seq2seq is also quite good! A difference of only 1% usually does not translate to a significant change in sentence quality. We also did not perform any hyperparameter tuning here, which could improve results.
The mixing and matching approach allows us to conduct more experiments. For example, we can connect BERT to GPT-2 to leverage BERT‘s capabilities to create strong text representations and GPT’s ability to generate high-quality sentences. It is a good practice to use different networks for custom datasets before choosing a SOTA model for all issues. The main difference using BERT (compared to BART) is the 512 token input sequence length limit (compared to 1024). Therefore, if the input sequences of the dataset are smaller, the BERT-to-BERT model would be a good choice. It trains smaller models more efficiently and requires fewer resources, such as data and GPU memory.
The code for this article can be found here:
https://github.com/NLPiation/tutorial_notebooks/blob/main/summarization/hf_BERT-BERT_training.ipynb