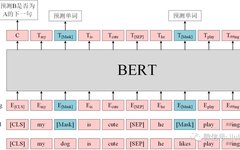
Improving Seq2Seq Text Summarization Model with BERT2BERT

Source: Deephub Imba This article is about 1500 words long and takes about 5 minutes to read. In this article, we want to demonstrate how to use the pre-trained weights of an encoder-only model to provide a good starting point for our fine-tuning. BERT is a famous and powerful pre-trained encoder model. Let’s see how … Read more