Mingmin from Aofeisi Quantum Bit | Public Account QbitAI
It must be said that to enable more people to use large models, the tech community is indeed coming up with various tricks!
Not open enough models? Some people are taking matters into their own hands to create free open-source versions.
For example, the recently popular DALL·E Mini and Meta’s open-source OPT-175B (Open Pretrained Transformer).
These are all achieved through replication, making originally closed large models become accessible to everyone.
Some people feel that the models are too large, and individual users find it difficult to bear the exorbitant costs.
Hence, methods like heterogeneous memory and parallel computing have been proposed to accelerate large model training while reducing costs.
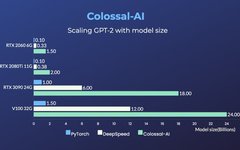
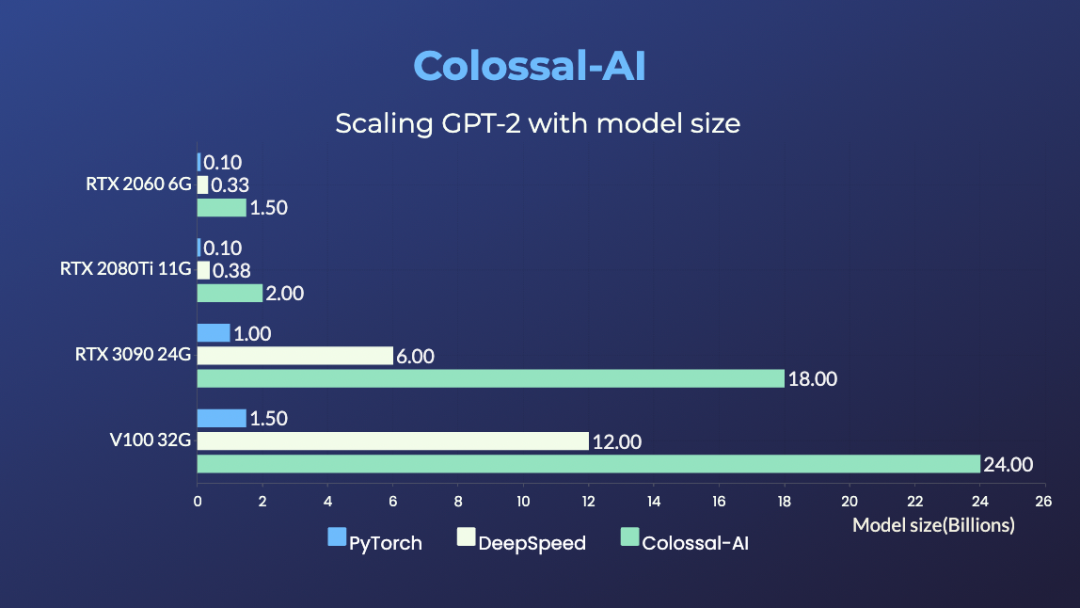
For example, the open-source project Colossal-AI recently achieved the ability to train a 18 billion parameter large model using just one NVIDIA 3090.
In the past few days, they have launched a new feature:
Seamlessly supporting Hugging Face community models, you only need to add a few lines of code to achieve low-cost training and fine-tuning of large models.

Hugging Face, being one of the most popular AI libraries today, offers implementations of over 50,000 AI models, making it the first choice for many AI enthusiasts training large models.
This move by Colossal-AI makes the training and fine-tuning of public models much more feasible.
Moreover, it also improves training performance.
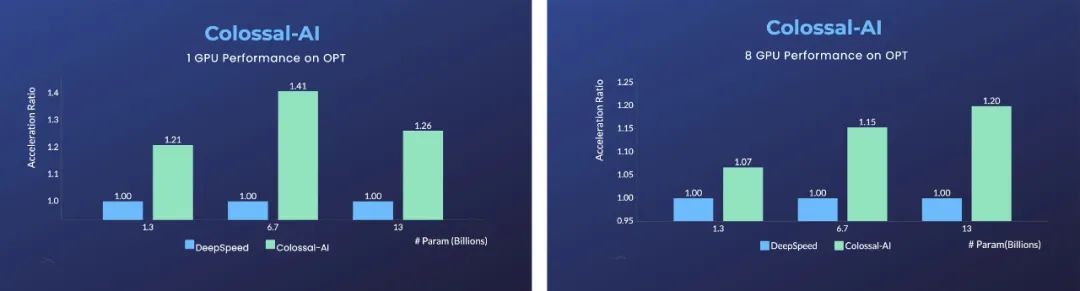
On a single GPU, compared to Microsoft’s DeepSpeed, using Colossal-AI’s automatic optimization strategy can achieve up to 40% acceleration.
Traditional deep learning frameworks like PyTorch can no longer run such large models on a single GPU.
For parallel training using 8 GPUs, you only need to add -nprocs 8 in the startup command.
This move addresses the cost, efficiency, and practical issues that individual AI players need to consider.
No Code Logic Modification Required
Actions speak louder than words.
Let’s take OPT as an example to see how to use the new features of Colossal-AI in detail.
OPT, short for Open Pretrained Transformer, was released by Meta AI and competes with GPT-3, with a maximum parameter count of up to 175 billion.
The main feature is that while GPT-3 has not released its model weights, OPT has open-sourced all its code and weights.
This allows every developer to build personalized downstream tasks based on it.
The following example demonstrates fine-tuning a causal language model (Causal Language Modelling) using the pre-trained weights provided by OPT.
It mainly consists of two steps:
-
Add configuration file
-
Run startup
The first step is to add a configuration file based on the task you want to perform.
For instance, on a single GPU, taking heterogeneous training as an example, you only need to add the relevant configuration items in the configuration file without changing the training logic in the code.
For example, tensor_placement_policy determines the strategy for heterogeneous training, with parameters being CUDA, CPU, and auto.
Each strategy has different advantages and is suited for different situations.
CUDA: Places all model parameters on the GPU, suitable for traditional scenarios where training can still occur without offloading.
CPU: Places all model parameters in CPU memory, retaining only the weights currently participating in computation in GPU memory, suitable for training super large models.
auto: Automatically decides the amount of parameters to retain in GPU memory based on real-time memory information, maximizing GPU memory utilization while reducing data transfer between CPU and GPU.
For ordinary users, using the auto strategy is the most convenient.
This allows Colossal-AI to automatically and dynamically select the best heterogeneous strategy in real-time, maximizing computational efficiency.
from colossalai.zero.shard_utils import TensorShardStrategy
zero = dict(model_config=dict(shard_strategy=TensorShardStrategy(), tensor_placement_policy="auto"), optimizer_config=dict(gpu_margin_mem_ratio=0.8))The second step is to insert a few lines of code to start the new features after preparing the configuration file.
First, use a line of code to start Colossal-AI with the configuration file.
Colossal-AI will automatically initialize the distributed environment, read the relevant configuration, and then automatically inject the functionalities defined in the configuration into components like the model and optimizer.
colossalai.launch_from_torch(config='./configs/colossalai_zero.py')Then, just like usual, define the dataset, model, optimizer, loss function, etc.
For instance, using native PyTorch code, when defining the model, you only need to initialize the model under ZeroInitContext.
Here, we are using the OPTForCausalLM model and pre-trained weights provided by Hugging Face, fine-tuning on the Wikitext dataset.
with ZeroInitContext(target_device=torch.cuda.current_device(), shard_strategy=shard_strategy, shard_param=True): model = OPTForCausalLM.from_pretrained( 'facebook/opt-1.3b' config=config )Next, simply call colossalai.initialize to unify the heterogeneous memory functionalities defined in the configuration file into the training engine, thus activating the corresponding functionalities.
engine, train_dataloader, eval_dataloader, lr_scheduler = colossalai.initialize(model=model, optimizer=optimizer, criterion=criterion, train_dataloader=train_dataloader, test_dataloader=eval_dataloader, lr_scheduler=lr_scheduler)It Still Relies on Heterogeneous GPU+CPU
The key to enabling users to achieve such “foolproof” operations lies in the AI system itself being smart enough.
The core component at play is Colossal-AI’s efficient heterogeneous memory management subsystem Gemini.
It acts like a manager within the system, dynamically allocating CPU and GPU memory usage after collecting the necessary information for computation.
The specific working principle is to pre-warm in the previous steps, collecting memory consumption information from the PyTorch dynamic computation graph.
After pre-warming is complete, before computing an operator, Gemini reserves the peak memory required for this operator on the computing device based on the collected memory usage records, while simultaneously moving some model tensors from GPU memory to CPU memory.
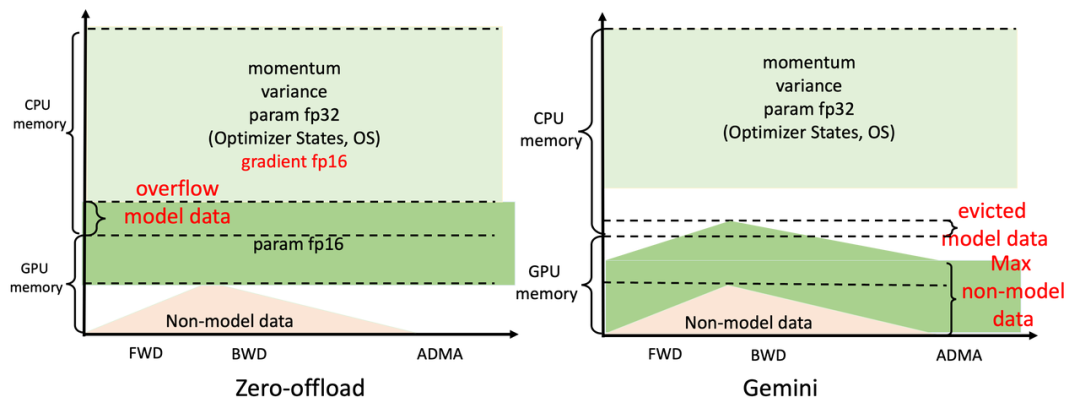
The built-in memory manager of Gemini marks each tensor with a status information, including HOLD, COMPUTE, FREE, etc.
Then, based on the dynamically queried memory usage situation, it continuously changes tensor states and adjusts tensor positions.
The direct benefit brought is that it can maximize model capacity and balance training speed under very limited hardware conditions.
It is worth noting that the mainstream method in the industry, ZeRO (Zero Redundancy Optimizer), although it also utilizes heterogeneous CPU+GPU memory methods, still causes system crashes and unnecessary communication due to static partitioning.
Moreover, using dynamic heterogeneous CPU+GPU memory methods also allows for memory expansion by adding memory sticks.
It is much more cost-effective than buying high-end graphics cards.

Currently, using the Colossal-AI method, an RTX 2060 6GB regular gaming laptop can train a 1.5 billion parameter model; an RTX 3090 24GB machine can directly tackle a 18 billion parameter large model; and a Tesla V100 32GB can handle 240 billion parameters.
In addition to maximizing memory utilization, Colossal-AI also employs distributed parallel methods to continuously enhance training speed.
It proposes to use complex parallel strategies like data parallelism, pipeline parallelism, and 2.5D tensor parallelism.
While the methods are complex, they are still very “foolproof” to operate, requiring only a simple declaration to achieve automatic implementation.
There is no need to manually handle complex underlying logic like other systems and frameworks.
parallel = dict( pipeline=2, tensor=dict(mode='2.5d', depth = 1, size=4))What Else Can Colossal-AI Do?
Since its open-source release, Colossal-AI has ranked first in the world multiple times on GitHub and Papers With Code hot lists, gaining some fame in the tech community.
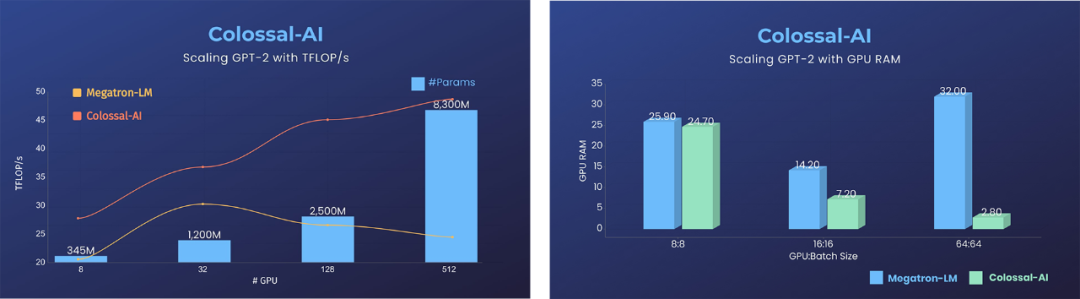
In addition to training large models on a single GPU as mentioned above, Colossal-AI can double performance and reduce resource usage to below one-tenth compared to existing systems like NVIDIA Megatron-LM when scaled to dozens or even hundreds of GPUs in large-scale parallel scenarios.
Roughly calculated, the savings on costs for pre-training ultra-large AI models like GPT-3 can reach hundreds of thousands of dollars.
It is reported that solutions related to Colossal-AI have been adopted by well-known manufacturers in industries such as autonomous driving, cloud computing, retail, pharmaceuticals, and chips.
At the same time, they also pay great attention to the construction of the open-source community, providing Chinese tutorials, opening user community forums, and continuously updating and iterating based on user feedback.
For instance, we found that a fan previously asked whether Colossal-AI could directly load some models from Hugging Face?
Well, this update has arrived.

So, for large model training, what difficulties do you think still need to be addressed?
Welcome to leave comments for discussion in the comment section~
Links
Project Address: https://github.com/hpcaitech/ColossalAI
Reference Links:[1]https://medium.com/@yangyou_berkeley/colossal-ai-seamlessly-accelerates-large-models-at-low-costs-with-hugging-face-4d1a887e500d[2]https://arxiv.org/abs/2202.05924v2[3]https://arxiv.org/abs/2205.11487[4]https://github.com/features/copilot[5]https://github.com/huggingface/transformers
— End —
“Artificial Intelligence” and “Smart Cars” WeChat Community Invites You to Join!
We welcome friends interested in artificial intelligence and smart cars to join us, exchange ideas with AI practitioners, and not miss the latest industry developments & technological progress.
PS: Please make sure to note your name, company, and position when adding friends~

Click here👇 to follow me, and remember to star it~
One-click three connections: “Share”, “Like”, and “View”
Technology frontier developments meet every day~