
Click on the above “MLNLP” to select the “Star” public account
Heavyweight content delivered at the first time

Reprinted from the public account: AI Technology Review
Introduction:Which is stronger, BERT, RoBERTa, DistilBERT, or XLNet?Choosing among different research fields and application scenarios has become a big challenge.Don’t panic, this article will help you clarify your thoughts.
BERT and Subsequent Models
Google’s transformer-based BERT series has caused a storm in the NLP field since its launch, with strong performance in several tasks, surpassing previously used state-of-the-art technologies.Recently, Google made revisions to BERT, and I will compare the main similarities and differences before and after the revision, so you can choose which one to use in your research or application.
BERT is a bidirectional transformer used for pre-training on large amounts of unlabeled text data to learn a language representation that can be fine-tuned for specific machine learning tasks.Although BERT outperforms previously used state-of-the-art technologies in several tasks, the improvement in performance is mainly attributed to the bidirectional transformer, masked language model training on tasks, and structural prediction capabilities, as well as the vast amounts of data and Google’s computational power.
Recently, several methods have been proposed to improve BERT’s prediction metrics or computational speed, but it has always been difficult to achieve both.XLNet and RoBERTa improve performance, while DistilBERT enhances inference speed.The table below compares them:
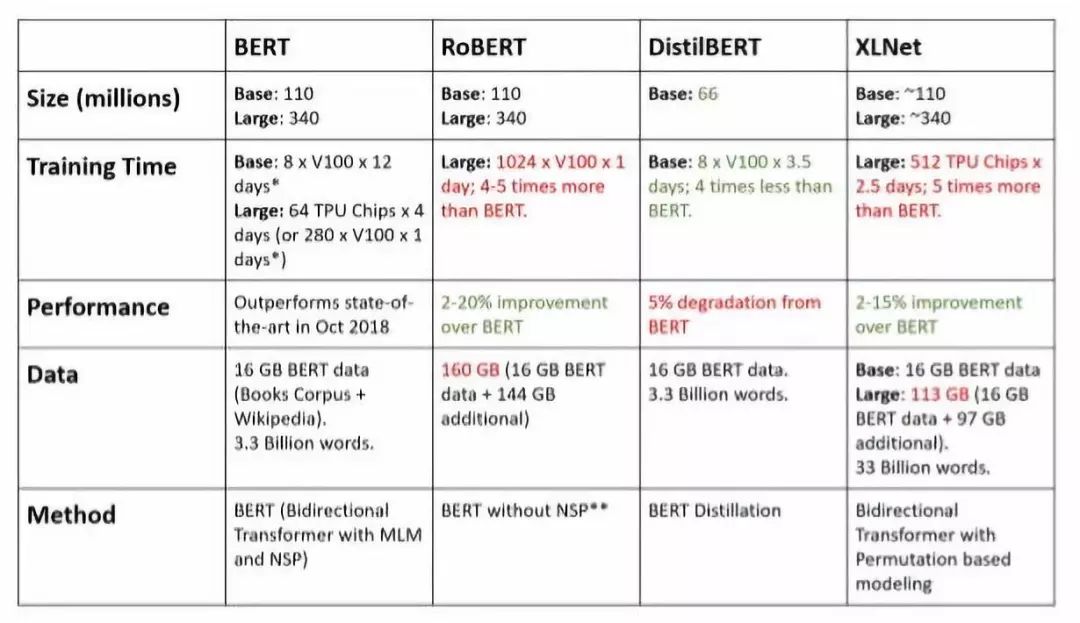
Figure 1:Comparison of BERT and some recent improvements
-
GPU compute time is estimated (using 4 TPU Pods for 4 days of raw training)
-
Using a large amount of small batch data, training speed and extended time based on the differences in masking procedures
-
Data source is the original paper
XLNet is a large bidirectional transformer that uses an improved training method, which has a larger dataset and stronger computational power, outperforming BERT in prediction metrics across 20 language tasks.
To improve the training method, XLNet introduces permutation language modeling, where all tokens are predicted in a random order.This contrasts with BERT’s masked language model, which only predicts the masked (15%) tokens.This also overturns traditional language models, where all tokens are predicted in order rather than randomly.This helps the model learn bidirectional relationships, thus better handling the relationships and connections between words.Additionally, using Transformer XL as the infrastructure, it can perform well even without unified order training.
XLNet was trained on over 130 GB of text data using 512 TPU chips for 2.5 days, and its training corpus is much larger than that of BERT.
RoBERTa, launched by Facebook, is an optimized version of BERT, retraining on the basis of BERT, improving the training method, and increasing the data by 1000% while enhancing computational capacity.
To optimize the training program, RoBERTa removed the next sentence prediction (NSP) task from BERT’s pre-training program and introduced dynamic masking to allow the masked tokens to change during training.During this process, it was also confirmed that large batch training scales are indeed more useful during the training process.
Importantly, RoBERTa was pre-trained on 160 GB of text, which includes 16 GB of text corpus and the English Wikipedia used by BERT.Other data includes the CommonCrawl News dataset (63 million articles, 76 GB), web text corpus (38 GB), and stories from ordinary crawlers (31 GB). Coupled with 1024 Tesla V100 GPUs running daily, RoBERTa has the foundation for pre-training.
Therefore, RoBERTa outperforms BERT and XLNet on the GLUE benchmark test results:
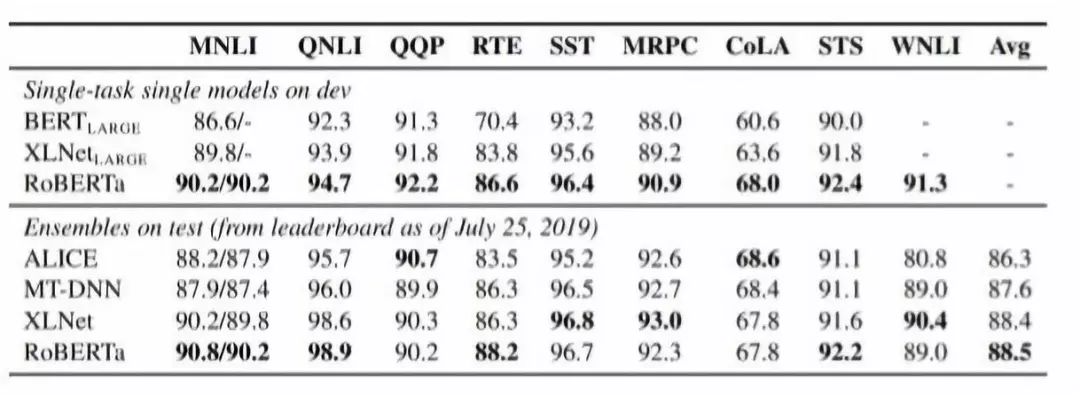
Figure 2:Performance comparison of RoBERTa.
On the other hand, to reduce the computation (training, prediction) time of BERT or related models, it is advisable to choose smaller networks to achieve similar performance.In fact, there are many ways to do this, including pruning, distillation, and quantization, however, all these will lead to lower prediction metrics.
DistilBERT learned a distilled (approximate) version of BERT, retaining 95% of performance while only using half the parameters. Specifically, it does not include the type and pooling layer embeddings, retaining only half the layers of Google’s BERT. DistilBERT uses a technique called distillation, which is similar to Google’s BERT (i.e., a large neural network composed of smaller neural networks).The principle is that once a large neural network is trained, a smaller network can be used to estimate its complete output distribution.This is somewhat similar to posterior approximation. One of the key optimization functions used for posterior approximation in Bayesian statistics is the Kullback-Leibler divergence, which is naturally used here as well.
Note:In Bayesian statistics, we approach the true posterior (from the data), while for distillation, we can only approximate the posterior learned in the larger network.
How to Use
If you really need faster inference speed and can accept a slight decline in prediction accuracy, then DistilBERT would be a suitable choice. However, if you are still looking for the best prediction performance, you should use Facebook’s RoBERTa.
Theoretically, training based on XLNet’s permutation should handle dependencies well and may show better performance in the long run.
However, Google’s BERT does provide a good baseline, and if you don’t have any of the above key requirements, you can use BERT to maintain normal system operation.
Conclusion
Most performance improvements (including BERT itself) are due to increased data volume, computational power, or training processes. Although they indeed have their own value, they often tend to trade-off between computation and prediction metrics.What is currently truly needed is to achieve basic improvements in performance while using less data and computational resources.
Original Author:SuleimanKhan
Original Link:https://towardsdatascience.com/bert-roberta-distilbert-xlnet-which-one-to-use-3d5ab82ba5f8

Recommended Reading:
Discussing the development of pre-trained language models based on recent papers
How to evaluate the fastText algorithm proposed by the author of Word2Vec? Does deep learning have no advantages in simple tasks like text classification?
From Word2Vec to BERT, discussing the past and present of word vectors (Part 1)
