
From | Zhihu
Address | https://zhuanlan.zhihu.com/p/85506365
Author | debuluoyi
Editor | Machine Learning Algorithms and Natural Language Processing Official Account
This article is for academic sharing only. If there is infringement, please contact us to delete it.
1. Overview
Before introducing deep interaction matching methods, this article continues from multi-semantic matching methods[1] to introduce the method of text matching based on the BERT model. It is introduced separately mainly because BERT makes text matching operations convenient and effective, making it suitable for industrial application scenarios. Regarding the BERT model, Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018)[2] provide a detailed introduction in their paper, and the official code can be found at the following GitHub URL: github.com/google-resea[3].
2. Model & Practice
2.1 Introduction to BERT Model
BERT is essentially a two-phase NLP model. The first phase is called: Pre-training, where the model is trained on a large-scale unsupervised dataset to obtain dynamic character-level semantic embeddings. It can simply be viewed as an enhanced version of character-level word2vec. In fact, due to another pre-training task of BERT, which is the Next Sentence Prediction, i.e., sentence-level problems formed by paired sentences, using BERT for text matching has a natural advantage.
The second phase is called: Fine-tuning, where the pre-trained language model is used to complete specific downstream NLP tasks. There are various downstream tasks in NLP, and BERT has achieved SOTA results in many of these tasks, one of which is the text matching task, where you can directly input the segmented sentence pairs to obtain matching results.
Of course, besides directly using BERT for sentence pair matching, theoretically, it is also possible to use BERT to obtain embeddings for each sentence and then use classic models like Siamese Network to calculate similarity. However, from a practical standpoint, this approach is not advisable as obtaining embeddings with BERT and then performing complex interactive computations will make the entire model very large, and the training time will also be very long, making it unsuitable for common industrial applications.
2.2 Practice of Text Matching Task
In fact, the input of the BERT model is already adapted for two segments of text. In common classification tasks, text_b=None is set, and only the first segment of text is input. For text matching, text_a, text_b are input normally.
(1) Data Processing
Input data format: text_a text_b label.The two sentences are separated by [SEP], and the vector of [CLS] is used as the input for classification. The label indicates whether the two sentences are similar, with 1 representing a positive case and 0 representing a negative case.
(2) Key Code Display
-
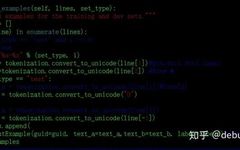
Example structure design for text pair input:
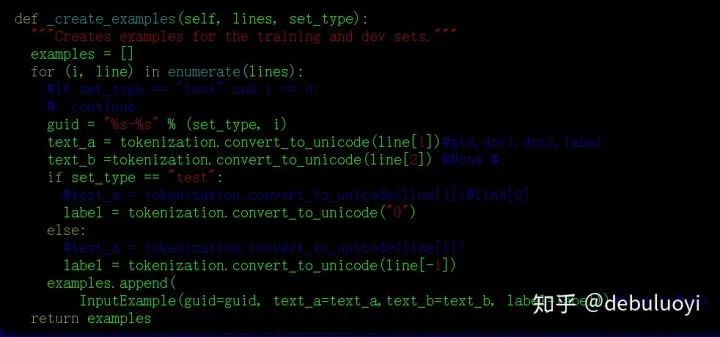
-
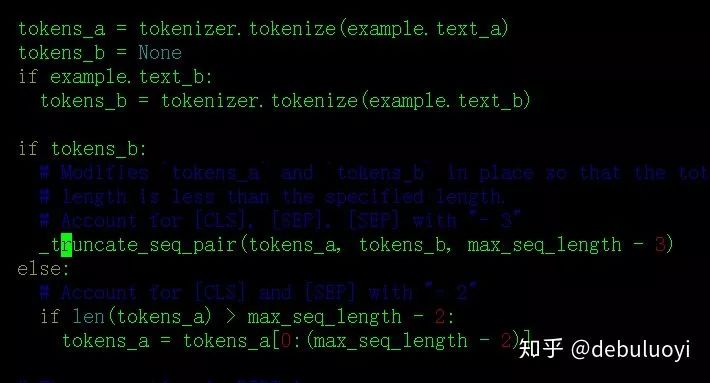
Text pair encoding processing
The input encoding length of text_a, text_b combined is your set max_length;
If len(text_a) + len(text_b) > max_length, then in a pair of texts, the longer one will be truncated.
-
Model Training
Add a processor name like text_matching, and set parameters in the sh file according to the style on GitHub: sh run_train.sh
(3) Practical Effect
Since one of the tasks in the BERT pre-training phase is Next Sentence Prediction, i.e., sentence-level problems formed by paired sentences, using BERT for text matching tasks can easily achieve excellent results, industrial-grade data can generally achieve effects of 80% or even more, requiring less training data than typical non-pre-trained matching models, while achieving better training results.
It is recommended for industrial use. If you need to address online performance issues, consider reducing the number of transformer layers in BERT, distilling it, using mixed precision, or employing quantization compression methods to compress it into a smaller model for deployment.
References
[1] Text Matching Methods Series – Multi-Semantic Matching Model: zhuanlan.zhihu.com/p/85;
debuluoyi: Text Matching Methods Series – Multi-Semantic Matching Modelzhuanlan.zhihu.com
[2] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.arXiv preprint arXiv:1810.04805.
[3] Official BERT model code and TensorFlow BERT model download address:
google-research/bertgithub.com
Important! A WeChat group for academic exchange in Natural Language Processing has been established.
You can scan the QR code below, and the assistant will invite you to join the group for discussion.
Note: Please modify the remark when adding to [School/Company + Name + Direction]
For example —— Harbin Institute of Technology + Zhang San + Dialogue System.
Business accounts, please avoid contacting. Thank you!

Recommended Reading:
PyTorch Cookbook (Common Code Snippets Collection)
Easy to Understand! Implementing Transformer with Excel and TF!
Multi-task Learning in Deep Learning (Keras Implementation)