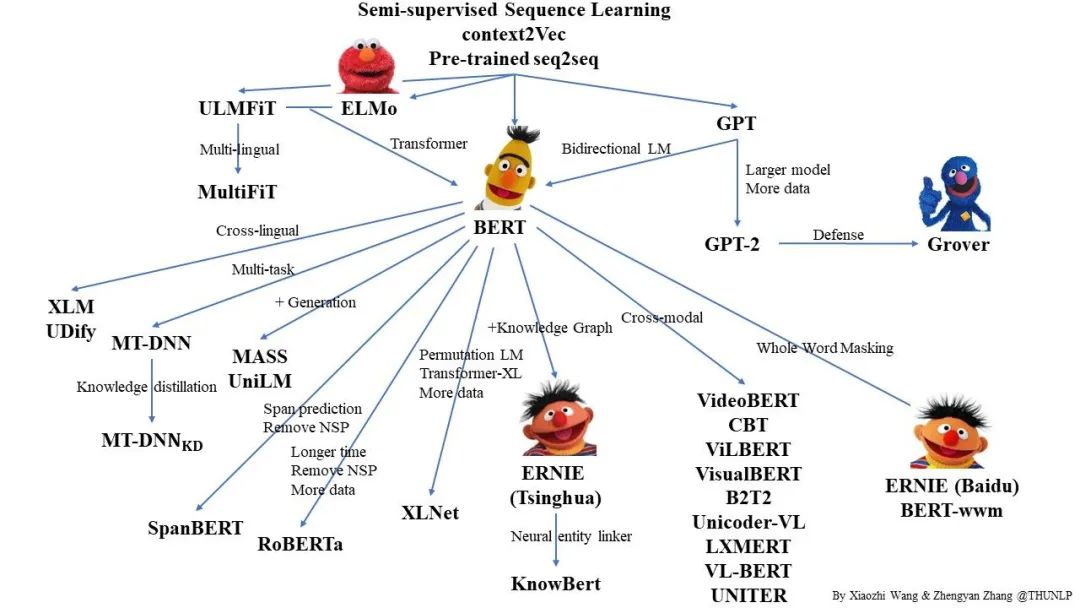
BERT has gained significant success and attention since its introduction in 2018. Based on this, various related models have been proposed in academia to improve BERT. This article attempts to summarize and organize these models.
MT-DNN
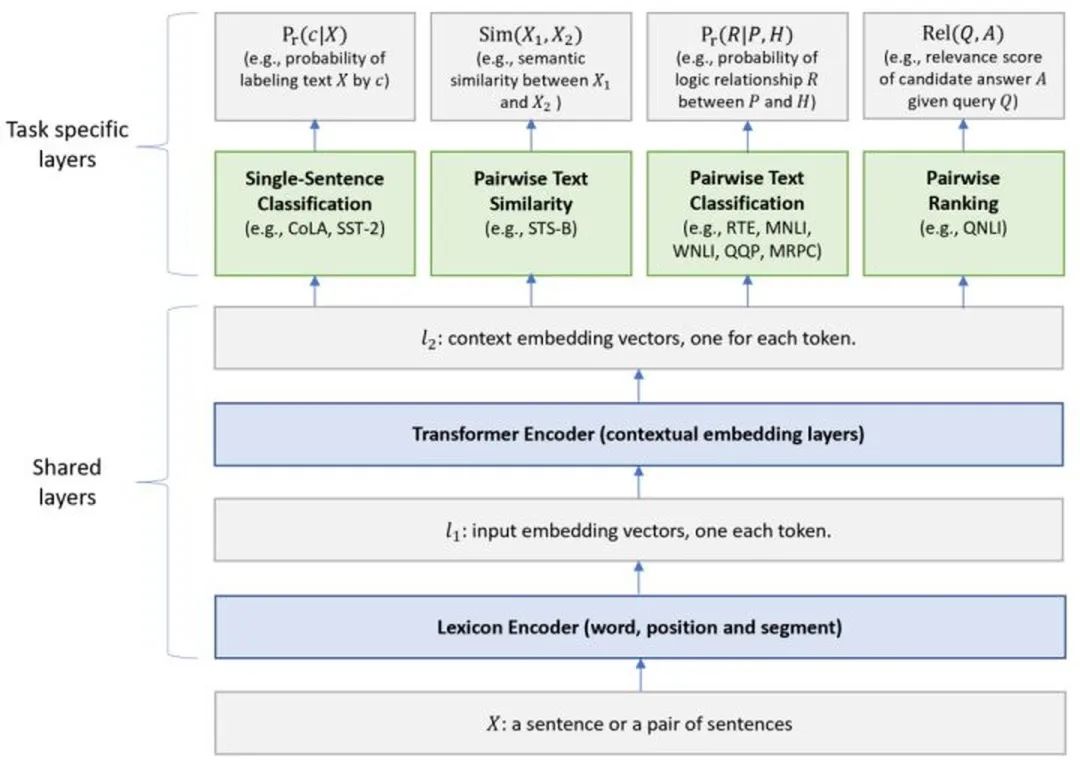
MT-DNN (Multi-Task DNN) was proposed by Microsoft in 2019 in the paper “Multi-Task Deep Neural Networks for Natural Language Understanding”.The model structure is as follows:The overall model is an MTL (Multi-Task Learning) framework, where the underlying Shared layers reuse the structure of BERT, shared by all tasks, while the top Task specific layers are unique to individual tasks. Overall, it is not much different from BERT, the only difference lies in the Pre-training phase, where MT-DNN incorporates multi-task training to learn better text representations (as shown in the figure).Advantages of MTL:
Tasks with fewer labeled data can utilize labeled data from other similar tasks.
Reduces overfitting for specific tasks, acting as a regularization mechanism.
MT-DNN introduces four different types of tasks and designs corresponding loss functions:Single-Sentence Classification: Uses the output corresponding to [CLS] at the layer, with the loss function being cross-entropy;Text Similarity: Uses the output corresponding to [CLS] at the layer, with the loss function being MSE (modeled as a regression problem);Pairwise Text Classification: The output is followed by a SAN (Stochastic Answer Network), with the loss function being cross-entropy;Relevance Ranking: Uses the output corresponding to [CLS] at the layer, with the loss function adopting LTR’s training paradigm.The Pre-training part of MT-DNN includes two stages: the first stage adopts BERT’s training method (MLM+NSP), learning the parameters of the Shared layers; the second stage adopts MTL to learn the parameters of the Shared layers + Task specific layers, where 9 GLUE tasks are used in this paper. The detailed training steps are as follows:In the paper, the authors used as the initialization for the Shared layers, and proved that even without the fine-tuning phase, MT-DNN performs better than .Overall, the improvement of MT-DNN over BERT comes from MTL and the special output module (the output module and loss function design are more complex).
XLNet
XLNet was proposed by CMU + Google in 2019 in the paper “XLNet: Generalized Autoregressive Pretraining for Language Understanding”.In the paper, the authors mentioned two pre-training methods: AR (autoregressive language modeling) and AE (denoising autoencoding). The former is represented by ELMo and the GPT series, while the latter is represented by BERT.Both methods have their disadvantages:
AR: Only utilizes information from unidirectional context (either forward or backward).
AE (specifically referring to BERT here): The [MASK] placeholder introduced in the pre-training phase does not exist in the fine-tuning phase; if a sequence has multiple [MASK] positions, BERT assumes they are independent of each other, which is not true.
To address the issues faced by BERT, XLNet made the following improvements:
The training objective for pre-training was adjusted to PLM (Permutation Language Modeling), implemented using a Two-Stream Self-Attention mechanism, sampling possible permutations.
The model structure adopted Transformer-XL to solve the issue of Transformers being unfriendly to long documents.
Utilized higher quality and larger scale corpora.
RoBERTa
RoBERTa was proposed by the University of Washington + Facebook in 2019 in the paper “RoBERTa: A Robustly Optimized BERT Pretraining Approach”.RoBERTa’s improvements mainly include:1. Longer training time: Larger scale training data (16GB -> 160GB), larger batch_size (256 -> 8K);2. Removal of the NSP task, with the input format modified to FULL-SENTENCES;3. Input granularity: Changed from character-level BPE to byte-level BPE;
4. Masking mechanism: Changed from static masking to dynamic masking:
Static masking: Randomly mask just once during the data preprocessing phase, with the masking method remaining unchanged for each data point in every epoch;
Dynamic masking: Randomly mask each data point during training, with the masking method differing in each epoch.
SpanBERT
SpanBERT was proposed by the University of Washington + Princeton University in 2019 in the paper “SpanBERT: Improving Pre-training by Representing and Predicting Spans”.The model structure is as follows:SpanBERT’s improvements mainly include:1. Span Masking: First, sample the length of the span based on a geometric distribution (if greater than 10, resample), then randomly select a starting point based on a uniform distribution, and finally mask the tokens within the span starting from the starting point; note that this process will be repeated until the number of masked tokens reaches a threshold, such as 15% of the input sequence;2. Span Boundary Objective (SBO): For each token within the span, in addition to the original MLM loss, add the SBO loss, i.e.,3. Single-Sequence Training: Removed the NSP task, replacing it with a single long sentence instead of the original two sentences.
ALBERT
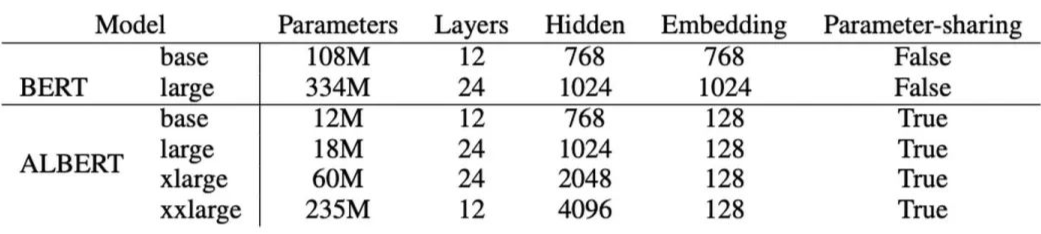
ALBERT was proposed by Google in 2019 in the paper “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations”.ALBERT’s starting point is that if the model parameters continue to grow, two types of problems will arise: GPU/TPU OOM; model performance degradation. Based on this, ALBERT considers reducing the model parameters.ALBERT’s improvements mainly include:1. Factorized embedding parameterization: In previous models, (E is vocabulary embedding size, H is hidden size), thus increasing H leads to an increase in E, resulting in a quadratic increase in parameters. ALBERT decouples E and H, and after embedding connects a matrix, allowing H to increase while keeping E unchanged. In this case, the number of parameters is reduced from to , and the effect becomes more pronounced when .2. Cross-layer parameter sharing: Parameters of each layer in the Transformer Encoder are shared, meaning each layer reuses the same set of parameters;3. Inter-sentence coherence loss: Replaced NSP with SOP (sentence-order prediction), i.e., extracting two consecutive sentences from the same document as positive samples and swapping their order as negative samples (NSP’s negative samples come from two different documents);4. Utilized larger scale training data and removed Dropout (as the authors found that the model still did not overfit).The number of parameters for ALBERT and BERT under different configurations is as follows:The performance and training time of ALBERT and BERT under different configurations are as follows:Note that the Speedup here refers to training time rather than inference time, as ALBERT’s optimizations mainly focus on reducing the number of parameters, which can speed up training, but the number of layers in the model does not change, so inference time is unaffected.
MASS
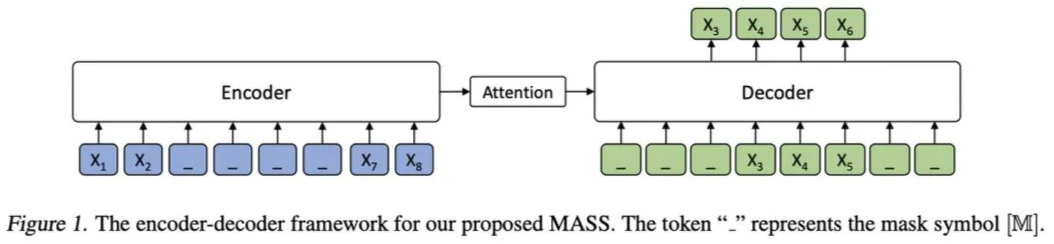
MASS was proposed by Microsoft in 2019 in the paper “MASS: Masked Sequence to Sequence Pre-training for Language Generation”.Models like BERT, based on pre-training and fine-tuning, have achieved great success in NLU (Natural Language Understanding) tasks. In contrast, NLG (Natural Language Generation) tasks such as neural machine translation (NMT), text summarization, and conversational response generation often face the problem of insufficient training data (paired data).Therefore, performing pre-training on a large amount of unpaired data and then fine-tuning on a small amount of paired data is also beneficial for NLU tasks. However, directly adopting a pre-training structure similar to BERT (using only encoder or decoder) is not advisable, as NLG tasks are typically based on an encoder-decoder framework. Based on this, the paper proposes a pre-training method suitable for NLG tasks—MASS.Unlike pre-training only the encoder or decoder, MASS can jointly pre-train both, with the structure as follows:Overall based on Transformer, the tokens masked in the Encoder are continuous, and the Decoder masks the unmasked tokens in the Encoder to predict the masked tokens.The paper mentions that by controlling the length k of the masked tokens in the Encoder, BERT and GPT can be viewed as special cases of MASS:Pre-training:
Due to NMT involving cross-language, data from four languages was used, and a language embedding was added to each token in the input of the Encoder and Decoder.
In the Encoder, the number of masked tokens is 50% of the sequence length, randomly selecting a starting point, with the masking method similar to BERT (80% replaced by [M], 10% replaced by other random tokens, and 10% unchanged).
In the Decoder, the masked tokens are removed, while the unmasked tokens retain their positional encoding unchanged.
Fine-tuning:
Similar to conventional Seq2Seq tasks.
UNILM
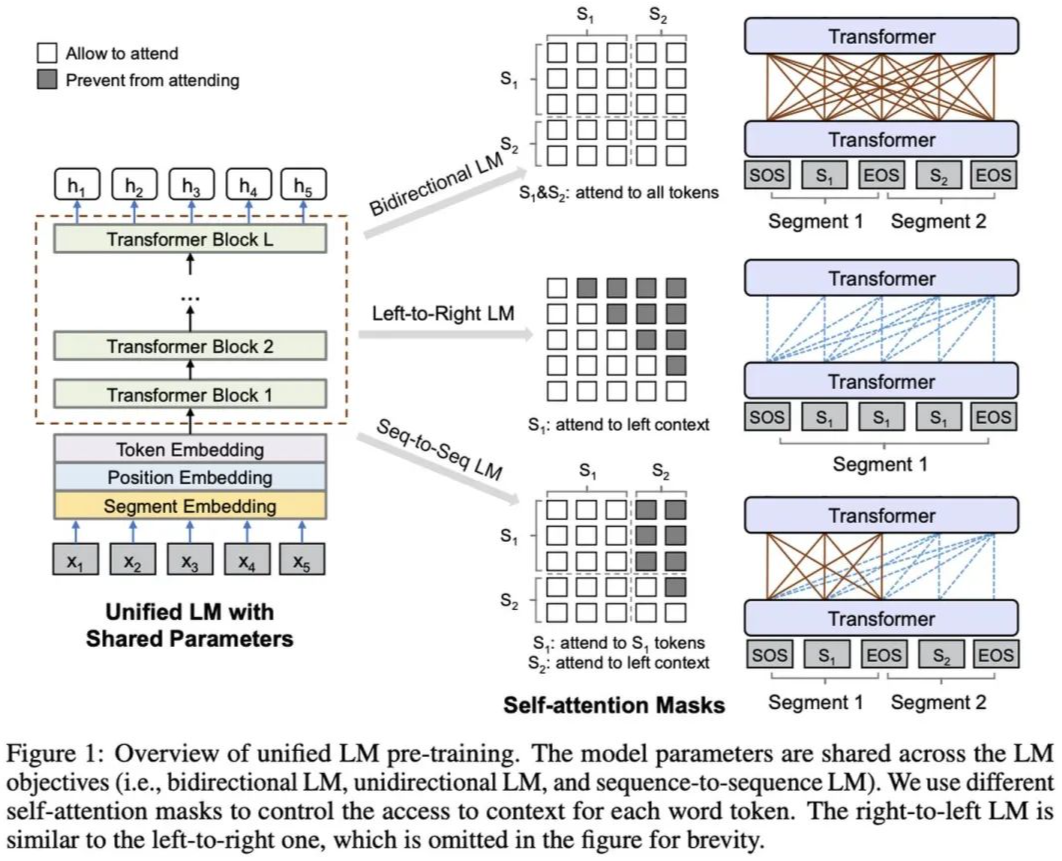
UNILM was proposed by Microsoft in 2019 in the paper “Unified Language Model Pre-training for Natural Language Understanding and Generation”.UNILM is a pre-training framework that can be applied to both NLU and NLG tasks, based on parameter sharing Transformer, jointly pre-training three types of unsupervised language modeling objectives: Unidirectional LM (left-to-right & right-to-left), Bidirectional LM, and Sequence-to-Sequence LM. After pre-training, UNILM can be fine-tuned (with task-specific layers added if necessary) to adapt to different types of downstream tasks.The model structure is as follows:Pre-training:
For different types of LM objectives, different segment embeddings are used for distinction.
For all types of LM objectives, the pre-training task is the cloze task, with the distinction being that different LMs can utilize different contexts: Unidirectional LM uses one-sided tokens (left or right); Bidirectional LM uses both-sided tokens; Sequence-to-Sequence LM uses all tokens in the source sequence and the left-sided tokens in the target sequence. Different contexts are achieved through corresponding mask matrices.
For Bidirectional LM, the NSP task is added.
For Sequence-to-Sequence LM, during the pre-training phase, both the source and target sequences can be masked.
In a batch, 1/3 of the time uses Bidirectional LM, 1/3 of the time uses Sequence-to-Sequence LM, 1/6 of the time uses left-to-right Unidirectional LM, and 1/6 of the time uses right-to-left Unidirectional LM.
80% of the time masks one token, and 20% of the time masks a bigram or trigram.
Fine-tuning:
For NLU tasks, same as BERT.
For NLG tasks, if it is a Seq2Seq task, only the tokens in the target sequence are masked.
Advantages of UNILM:
The unified pre-training process allows a single Transformer to use shared parameters and architecture for different types of language models, reducing the need to separately train and manage multiple language models.
Parameter sharing makes the learned text representations more general, as they are jointly optimized for different language modeling objectives (with different ways of utilizing context), alleviating overfitting on any single language model task.
Besides its application in NLU tasks, UNILM as a Sequence-to-Sequence LM also makes it naturally applicable to NLG tasks, such as abstractive summarization and question answering.
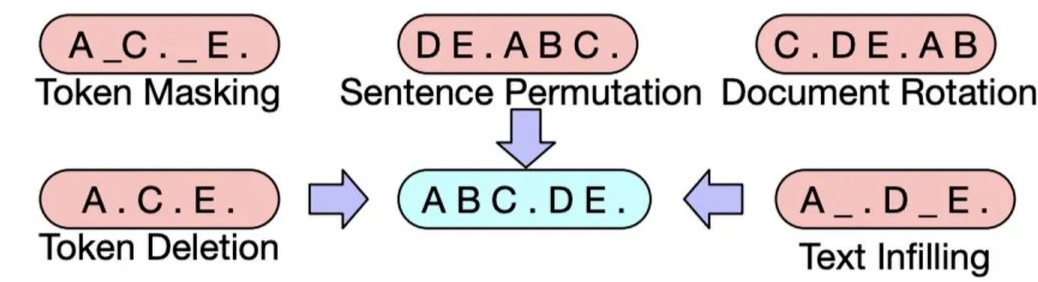
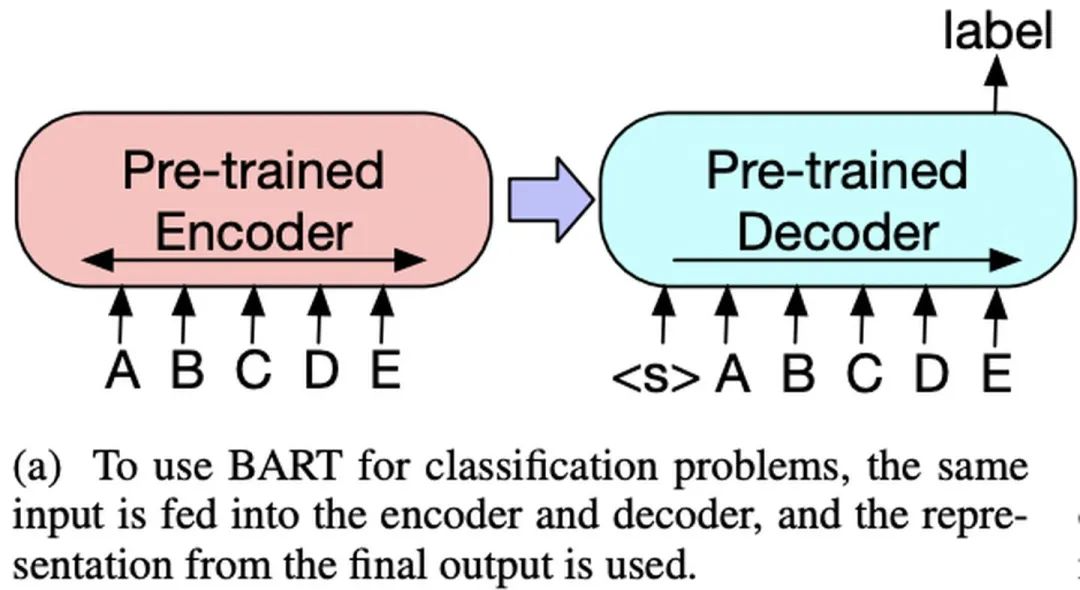
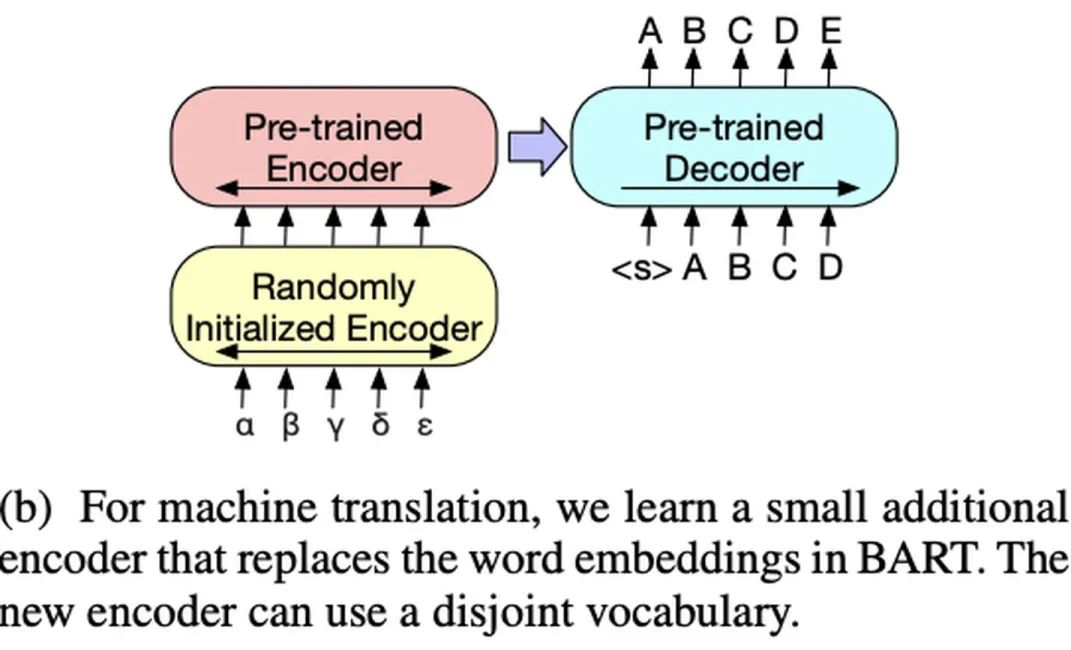
BART
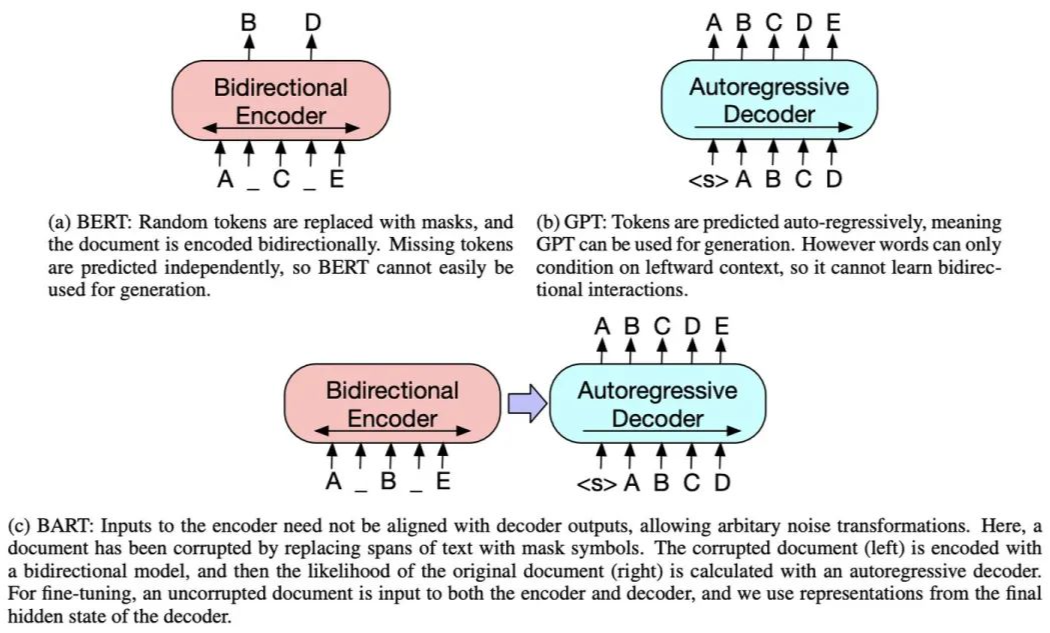
BART was proposed by Facebook in 2019 in the paper “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension”.BART adopts the Seq2Seq framework of Transformer, similar to MASS, except that its pre-training task is: inputting corrupted text on the Encoder side and restoring the original text on the Decoder side.The model structure is as follows:The ways to corrupt the text are as follows (can be used in combination):Fine-tuning:
Sequence Classification Tasks:
Token Classification Tasks: Input the complete document into the Encoder and Decoder, using the top hidden state of the Decoder as the representation for each token for classification.
Sequence Generation Tasks: Same as conventional Seq2Seq tasks.
Machine Translation: Added a new Encoder structure (randomly initialized), replacing the embedding layer of the pre-trained Encoder.
Download 1: Four Essentials
Reply "Four Essentials" in the background of the Machine Learning Algorithms and Natural Language Processing public account to obtain learning resources for TensorFlow, Pytorch, machine learning, and deep learning!
Download 2: Repository Address Sharing
Reply "Code" in the background of the Machine Learning Algorithms and Natural Language Processing public account to get 195 NAACL + 295 ACL 2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Big news! The Machine Learning Algorithms and Natural Language Processing Exchange Group has officially been established! There are a lot of resources in the group, and everyone is welcome to join the group to learn!
Additional welfare resources! Deep learning and neural networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning notes, official Chinese version of pandas documentation, effective java (Chinese version), and other 20 welfare resources.
How to obtain: After entering the group, click on the group announcement to obtain the download link.
Note: Please modify the remarks when adding as [School/Company + Name + Direction].
For example —— Harbin Institute of Technology + Zhang San + Dialogue System.
The account owner, please bypass if you are a micro merchant. Thank you!
Recommended Reading:
Implementation of NCE-Loss in Tensorflow and word2vec
Overview of Multimodal Deep Learning: Summary of Network Structure Design and Modality Fusion Methods
Awesome Adversarial Machine Learning Resource List



 layer, with the loss function being cross-entropy;
layer, with the loss function being cross-entropy; layer, with the loss function being MSE (modeled as a regression problem);
layer, with the loss function being MSE (modeled as a regression problem); layer, with the loss function adopting LTR’s training paradigm.
layer, with the loss function adopting LTR’s training paradigm.
 as the initialization for the Shared layers, and proved that even without the fine-tuning phase, MT-DNN performs better than
as the initialization for the Shared layers, and proved that even without the fine-tuning phase, MT-DNN performs better than  .
.



 (if greater than 10, resample), then randomly select a starting point based on a uniform distribution, and finally mask the tokens within the span starting from the starting point; note that this process will be repeated until the number of masked tokens reaches a threshold, such as 15% of the input sequence;
(if greater than 10, resample), then randomly select a starting point based on a uniform distribution, and finally mask the tokens within the span starting from the starting point; note that this process will be repeated until the number of masked tokens reaches a threshold, such as 15% of the input sequence;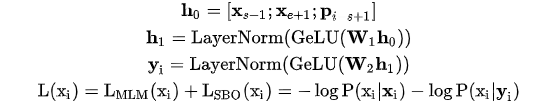

 (E is vocabulary embedding size, H is hidden size), thus increasing H leads to an increase in E, resulting in a quadratic increase in parameters. ALBERT decouples E and H, and after embedding connects a
(E is vocabulary embedding size, H is hidden size), thus increasing H leads to an increase in E, resulting in a quadratic increase in parameters. ALBERT decouples E and H, and after embedding connects a  matrix, allowing H to increase while keeping E unchanged. In this case, the number of parameters is reduced from
matrix, allowing H to increase while keeping E unchanged. In this case, the number of parameters is reduced from  to
to  , and the effect becomes more pronounced when
, and the effect becomes more pronounced when  .
.