TurboAttention: Efficient Attention Mechanism Optimization Reducing LLM Costs by 70%
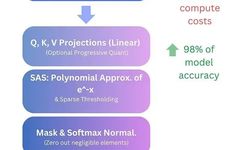
Source: Deephub Imba This article is approximately 6500 words long and is recommended for a 10-minute read. This article will delve into how TurboAttention achieves efficiency improvements from a technical perspective and analyze its architectural innovations. As large language models (LLMs) continue to evolve in the AI application domain, their computational costs are also showing … Read more