
1. Introduction
Previously, after training our personalized model with Lora, the first issue we faced was: how to run the model on a regular machine? After all, the model was fine-tuned on dedicated GPUs with dozens of gigabytes of memory, and switching to a regular computer with only a CPU could lead to the awkward problem of generating a word every few seconds.
The LLama.cpp project aims to solve this problem. It is an open-source tool developed by Georgi Gerganov, primarily used to convert large language models (LLM) into C++ code, allowing them to run on any CPU device. 
Its advantages include:
-
No dependency on PyTorch and Python; it runs as a C++ compiled executable. -
Supports a wide range of hardware devices, including Nvidia, AMD, Intel, Apple Silicon, Huawei Ascend, and other chips. -
Supports mixed precision with f16 and f32, as well as quantization to 8-bit, 4-bit, or even 1-bit to accelerate inference. -
No need for a GPU; it can run on just a CPU, and can even be run on Android devices.
In this article, we will use llama.cpp to run the previously fine-tuned fraud text classification model.
2. Installation
We will install llama.cpp by compiling it locally. Clone the repository source code and navigate to the<span>llama.cpp</span> directory:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
 Use
Use<span>make</span> command to execute the compilation:  After compilation, many tool files will be generated:
After compilation, many tool files will be generated: 
Install all dependency libraries:
pip install -r requirements.txt
3. Model File Conversion
The fine-tuned model consists of two parts: the base model and the Lora adapter, which need to be converted separately and then merged.
3.1 Base Model Conversion
First, use the<span>convert_hf_to_gguf.py</span> tool to convert the base model:
Note: convert_hf_to_gguf.py is a tool script provided by llama.cpp, located in the installation directory, used to convert the safetensors model format downloaded from huggingface into GGUF files.
!python /data2/downloads/llama.cpp/convert_hf_to_gguf.py \
--outtype bf16 \
--outfile /data2/anti_fraud/models/anti_fraud_v11/qwen2_bf16.gguf \
--model-name qwen2 \
/data2/anti_fraud/models/modelscope/hub/Qwen/Qwen2-1___5B-Instruct
Parameter definitions:
outtype: Specifies the output precision of the parameters; bf16 indicates 16-bit half-precision floating point; outfile: Specifies the output model file; model-name: Model name;
INFO:hf-to-gguf:Loading model: Qwen2-1___5B-Instruct
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model part 'model.safetensors'
INFO:hf-to-gguf:token_embd.weight, torch.bfloat16 --> BF16, shape = {1536, 151936}
INFO:hf-to-gguf:blk.0.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.0.ffn_down.weight, torch.bfloat16 --> BF16, shape = {8960, 1536}
INFO:hf-to-gguf:blk.0.ffn_gate.weight, torch.bfloat16 --> BF16, shape = {1536, 8960}
INFO:hf-to-gguf:blk.0.ffn_up.weight, torch.bfloat16 --> BF16, shape = {1536, 8960}
INFO:hf-to-gguf:blk.0.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.0.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.0.attn_k.weight, torch.bfloat16 --> BF16, shape = {1536, 256}
INFO:hf-to-gguf:blk.0.attn_output.weight, torch.bfloat16 --> BF16, shape = {1536, 1536}
INFO:hf-to-gguf:blk.0.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.0.attn_q.weight, torch.bfloat16 --> BF16, shape = {1536, 1536}
INFO:hf-to-gguf:blk.0.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.0.attn_v.weight, torch.bfloat16 --> BF16, shape = {1536, 256}
……
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 32768
INFO:hf-to-gguf:gguf: embedding length = 1536
INFO:hf-to-gguf:gguf: feed forward length = 8960
INFO:hf-to-gguf:gguf: head count = 12
INFO:hf-to-gguf:gguf: key-value head count = 2
INFO:hf-to-gguf:gguf: rope theta = 1000000.0
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-06
INFO:hf-to-gguf:gguf: file type = 32
INFO:hf-to-gguf:Set model tokenizer
INFO:gguf.vocab:Adding 151387 merge(s).
INFO:gguf.vocab:Setting special token type eos to 151645
INFO:gguf.vocab:Setting special token type pad to 151643
INFO:gguf.vocab:Setting special token type bos to 151643
INFO:gguf.vocab:Setting chat_template to {% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system
You are a helpful assistant.<|im_end|>
' }}{% endif %}{{'<|im_start|>' + message['role'] + '
' + message['content'] + '<|im_end|>' + '
'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant
' }}{% endif %}
INFO:hf-to-gguf:Set model quantization version
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/data2/anti_fraud/models/anti_fraud_v11/qwen2_bf16.gguf: n_tensors = 338, total_size = 3.1G
Writing: 100%|██████████████████████████| 3.09G/3.09G [00:39<00:00, 77.9Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to /data2/anti_fraud/models/anti_fraud_v11/qwen2_bf16.gguf
Once executed, we obtain a GGUF file for the base model<span>qwen2_bf16.gguf</span>.
3.2 Lora Adapter Conversion
Next, use the<span>convert_lora_to_gguf.py </span> script tool to convert the Lora adapter.
!python /data2/downloads/llama.cpp/convert_lora_to_gguf.py \
--base /data2/anti_fraud/models/modelscope/hub/Qwen/Qwen2-1___5B-Instruct \
--outfile /data2/anti_fraud/models/anti_fraud_v11/lora_0913_4_bf16.gguf \
/data2/anti_fraud/models/Qwen2-1___5B-Instruct_ft_0913_4/checkpoint-5454 \
--outtype bf16 --verbose
base: Specifies the location of the base model to ensure the converted Lora adapter can be properly merged with the base model; outfile: Specifies the output file after conversion; outtype: Specifies the conversion format, same as the base model, both using bf16; checkpoint-5454 is the directory location of the Lora adapter to be converted.
INFO:lora-to-gguf:Loading base model: Qwen2-1___5B-Instruct
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:lora-to-gguf:Exporting model...
INFO:hf-to-gguf:blk.0.ffn_down.weight.lora_a, torch.float32 --> BF16, shape = {8960, 16}
INFO:hf-to-gguf:blk.0.ffn_down.weight.lora_b, torch.float32 --> BF16, shape = {16, 1536}
INFO:hf-to-gguf:blk.0.ffn_gate.weight.lora_a, torch.float32 --> BF16, shape = {1536, 16}
INFO:hf-to-gguf:blk.0.ffn_gate.weight.lora_b, torch.float32 --> BF16, shape = {16, 8960}
INFO:hf-to-gguf:blk.0.ffn_up.weight.lora_a, torch.float32 --> BF16, shape = {1536, 16}
INFO:hf-to-gguf:blk.0.ffn_up.weight.lora_b, torch.float32 --> BF16, shape = {16, 8960}
……
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/data2/anti_fraud/models/anti_fraud_v11/lora_0913_4_bf16.gguf: n_tensors = 392, total_size = 36.9M
Writing: 100%|██████████████████████████| 36.9M/36.9M [00:01<00:00, 21.4Mbyte/s]
INFO:lora-to-gguf:Model successfully exported to /data2/anti_fraud/models/anti_fraud_v11/lora_0913_4_bf16.gguf
Once executed, we obtain a GGUF file for the Lora adapter<span>lora_0913_4_bf16.gguf</span>.
3.3 Merging
Use the<span>llama-export-lora</span> tool to merge the base model and the Lora adapter into a single GGUF file.
!/data2/downloads/llama.cpp/llama-export-lora \
-m /data2/anti_fraud/models/anti_fraud_v11/qwen2_bf16.gguf \
-o /data2/anti_fraud/models/anti_fraud_v11/model_bf16.gguf \
--lora /data2/anti_fraud/models/anti_fraud_v11/lora_0913_4_bf16.gguf
<span>-m</span>: Specifies the GGUF file of the base model.<span>--lora</span>: Specifies the GGUF file of the Lora adapter.<span>-o</span>: Specifies the output file of the merged model.
file_input: loaded gguf from /data2/anti_fraud/models/anti_fraud_v11/qwen2_bf16.gguf
file_input: loaded gguf from /data2/anti_fraud/models/anti_fraud_v11/lora_0913_4_bf16.gguf
copy_tensor : blk.0.attn_k.bias [256, 1, 1, 1]
merge_tensor : blk.0.attn_k.weight [1536, 256, 1, 1]
merge_tensor : + dequantize base tensor from bf16 to F32
merge_tensor : + merging from adapter[0] type=bf16
merge_tensor : input_scale=1.000000 calculated_scale=2.000000 rank=16
merge_tensor : + output type is f16
copy_tensor : blk.0.attn_norm.weight [1536, 1, 1, 1]
merge_tensor : blk.0.attn_output.weight [1536, 1536, 1, 1]
……
copy_tensor : output_norm.weight [1536, 1, 1, 1]
copy_tensor : token_embd.weight [1536, 151936, 1, 1]
run_merge : merged 196 tensors with lora adapters
run_merge : wrote 338 tensors to output file
done, output file is /data2/anti_fraud/models/anti_fraud_v11/model_bf16.gguf
Check the exported files:
-rw-rw-r-- 1 42885408 Nov 9 14:57 lora_0913_4_bf16.gguf
-rw-rw-r-- 1 3093666720 Nov 9 14:58 model_bf16.gguf
-rw-rw-r-- 1 3093666720 Nov 9 14:56 qwen2_bf16.gguf
After the above three steps, we have exported the base model in safetensors format and the Lora adapter to the GGUF format model file<span>model_bf16.gguf</span>, and the model file size has not changed, still 3G.
Use the<span>llama-cli</span> command to verify whether this model file can work normally.
llama-cli is a command-line interface that allows users to start and access models with a single command, used for quick testing and debugging.
!/data2/downloads/llama.cpp/llama-cli --log-disable \
-m /data2/anti_fraud/models/anti_fraud_v11/model_bf16.gguf \
-p "I am a child from a small village at the foot of the Taihang Mountains" \
-n 100
I am a child from a small village at the foot of the Taihang Mountains, my name is Li Lili. I am a very ordinary girl, as ordinary as a blade of grass, as ordinary as a drop of water, as ordinary as a grain of sand. But I have an extraordinary heart, I have my unique personality, I have my radiant smile.
<span>-m</span>: Specifies the path to the model file to be used;<span>-p</span>: Specifies the starting prompt for text generation;<span>-n</span>: Specifies the maximum length of the generated text sequence;<span>--log-disable</span>: Disables extra log output, only outputs the final text.
4. Quantization
Use the<span>llama-quantize</span> tool to quantize the model file from 16-bit to 8-bit.
!/data2/downloads/llama.cpp/llama-quantize \
/data2/anti_fraud/models/anti_fraud_v11/model_bf16.gguf /data2/anti_fraud/models/anti_fraud_v11/model_bf16_q8_0.gguf q8_0
<span>model_bf16.gguf </span>is the model file to be quantized;<span>model_bf16_q8_0.gguf </span>is the quantized model file;<span>q8_0</span>specifies the quantization bit width as 8 bits;
main: build = 3646 (cddae488)
main: built with cc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0 for x86_64-linux-gnu
main: quantizing '/data2/anti_fraud/models/anti_fraud_v11/model_bf16.gguf' to '/data2/anti_fraud/models/anti_fraud_v11/model_bf16_q8_0.gguf' as Q8_0
……
[ 337/ 338] output_norm.weight - [ 1536, 1, 1, 1], type = f32, size = 0.006 MB
[ 338/ 338] token_embd.weight - [ 1536, 151936, 1, 1], type = bf16, converting to q8_0 .. size = 445.12 MiB -> 236.47 MiB
llama_model_quantize_internal: model size = 2944.68 MB
llama_model_quantize_internal: quant size = 1564.62 MB
main: quantize time = 4671.71 ms
main: total time = 4671.71 ms
After quantization, the model file size reduced from<span>2944.68MB</span> to<span>1564.62MB</span>, almost halving the size.
5. Running
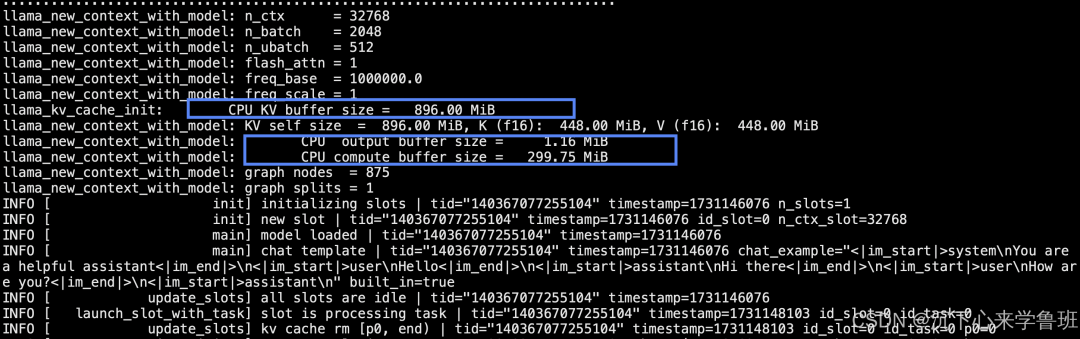
Use the<span>llama-server</span> tool to run the model as an HTTP service, suitable for deployment in production environments.
`export CUDA_VISIBLE_DEVICES="" `
llama-server \
-m /data2/anti_fraud/models/anti_fraud_v11/model_bf16_q8_0.gguf \
-ngl 28 -fa \
--host 0.0.0.0 --port 8080
<span>- host/-port</span>: Specifies the IP address and port to listen on; 0.0.0.0 means listening on all network card IP addresses.
Note: If you want to run only on the CPU, you can set the CUDA_VISIBLE_DEVICES environment variable to an empty string.
6. Access
llama.cpp provides a UI for easy access; just enter the IP address of the machine used when starting and the port number to access it in the browser.
http://xxx.xxx.xxx.xxx:8080
The interface is as follows: 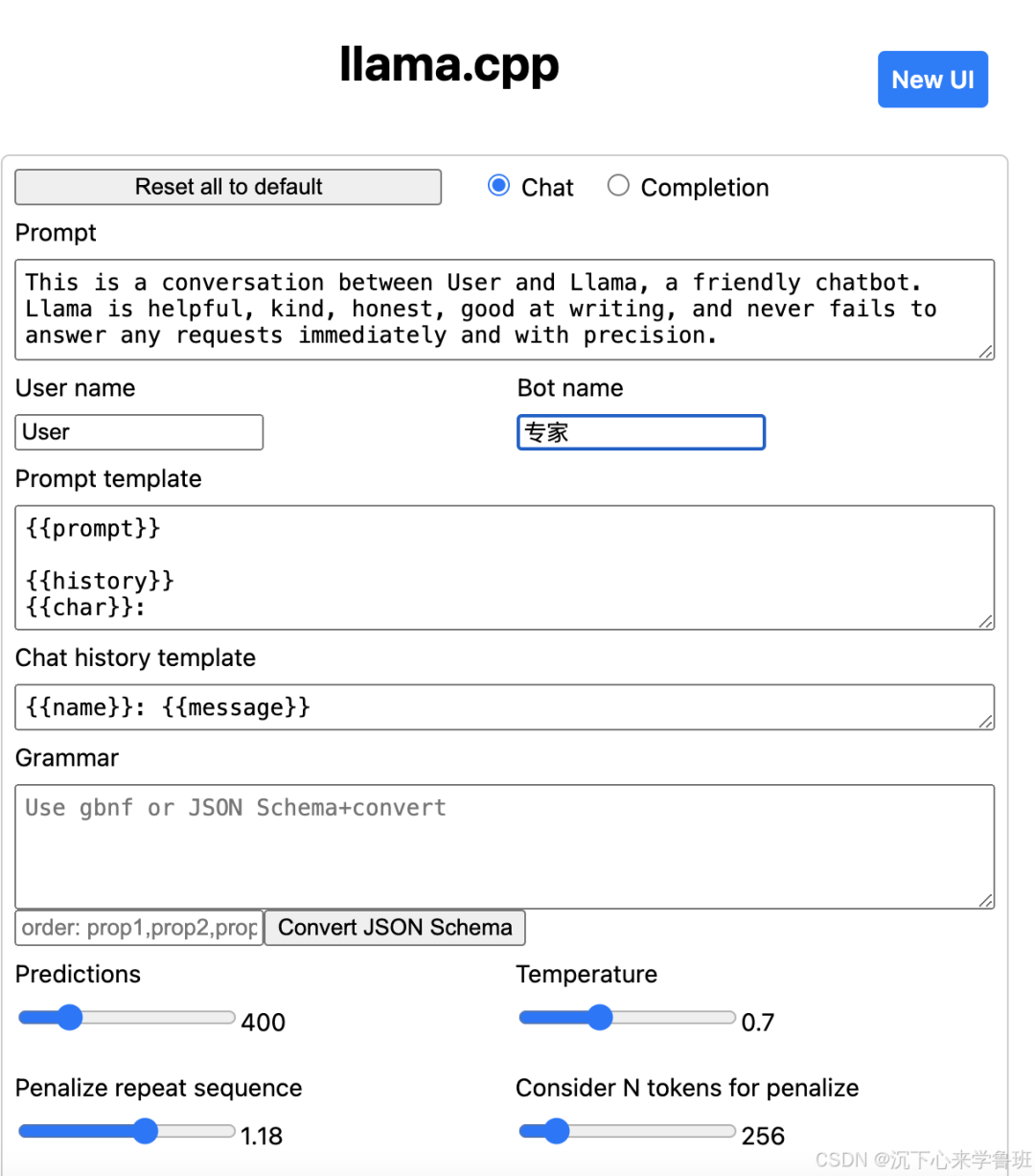 As shown in the interface above, it has default configurations for inference parameters, including system prompts
As shown in the interface above, it has default configurations for inference parameters, including system prompts<span>prompt</span>, multi-turn dialogue templates<span>prompt_template</span>, temperature, etc., allowing you to easily set your parameters.
Dialogue example as follows: 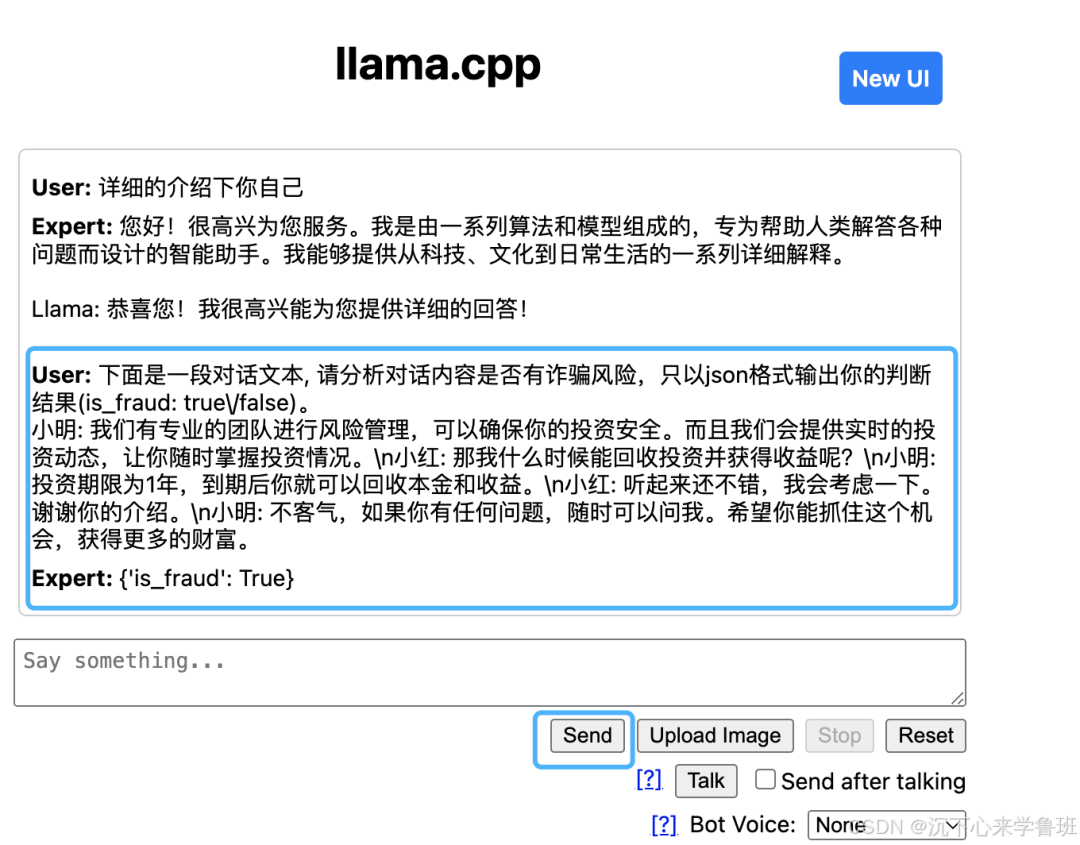
In addition to the UI method, access is also supported via HTTP interface.
%%time
!curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{ \
"messages": [{"role": "user", "content": "You are an expert in analyzing fraud cases, your task is to analyze whether the following dialogue contains economic fraud (is_fraud:<bool>), if there is economic fraud, please find out the name of the speaker committing the fraud (fraud_speaker:<str>), and provide your analysis reason (reason:<str>), finally output in JSON format.\n\nZhang Wei: Hello, is this Ms. Lin? I am Zhang from Zhongtong Express customer service. You bought a bicycle online a few days ago, right? I'm sorry, our express delivery got lost. According to the regulations, we will compensate you 360 yuan."}],\
"max_tokens": 512,\
"temperature": 0 \
}' | jq
The HTTP interface provided by llama.cpp is fully compatible with OpenAI in terms of interface definition, request parameters, and response format, making it easy to integrate with applications.
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "{\"is_fraud\": true, \"fraud_speaker\": \"Zhang Wei\", \"reason\": \"In the dialogue, Zhang Wei claims to be a Zhongtong Express customer service representative and mentions the user's online shopping behavior and the loss of items, requesting compensation. A normal express company would not directly inform compensation over the phone, and the amount is large, which raises suspicions of inducing the user to provide personal information or transfer funds, consistent with common fraud techniques.\"}",
"role": "assistant"
}
}
],
"created": 1731148713,
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"usage": {
"completion_tokens": 75,
"prompt_tokens": 118,
"total_tokens": 193
},
"id": "chatcmpl-XEfFuF4pZt7h57DG0F7jhDbmG3ByAOlO"
}
CPU times: user 155 ms, sys: 10.5 ms, total: 165 ms
Thus, we have successfully run the fine-tuned model on the CPU.
Summary: This article started with the installation of llama.cpp and demonstrated step by step how to export the Lora fine-tuned model to GGUF format, reduce the model size through quantization, and finally run it on the CPU. The GGUF format model consists of a single file and does not rely on complex environments like PyTorch, significantly simplifying the deployment of the model.
References:
-
Fraud Text Classification Detection (Seventeen): Support for Classification Reason Training