MLNLP community is a well-known machine learning and natural language processing community, covering both domestic and international NLP master’s and doctoral students, university teachers, and corporate researchers.The Vision of the Community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.Reproduced from | oldpan blogAuthor | Xiao PanpanThis article explains the reasons why large models such as LLMs need quantization, including reducing model size and improving inference performance, and introduces the basic concepts of quantization and two main modes: asymmetric quantization and symmetric quantization. The article demonstrates how to quantize model weights from FP32 to INT8 and perform dequantization through mathematical derivation and PyTorch code examples to reduce model memory usage and accelerate inference while maintaining model accuracy.This article is translated and compiled from:
A simple introduction to why large models need quantization and the basic operations of quantization.
First, understand what quantization is and why it is needed.
Next, delve into how to perform quantization and understand it through simple mathematical derivation.
Finally, write some PyTorch code to quantize and dequantize LLM weight parameters.
Let’s unpack all one by one together.
What is Quantization and Why is it Needed?
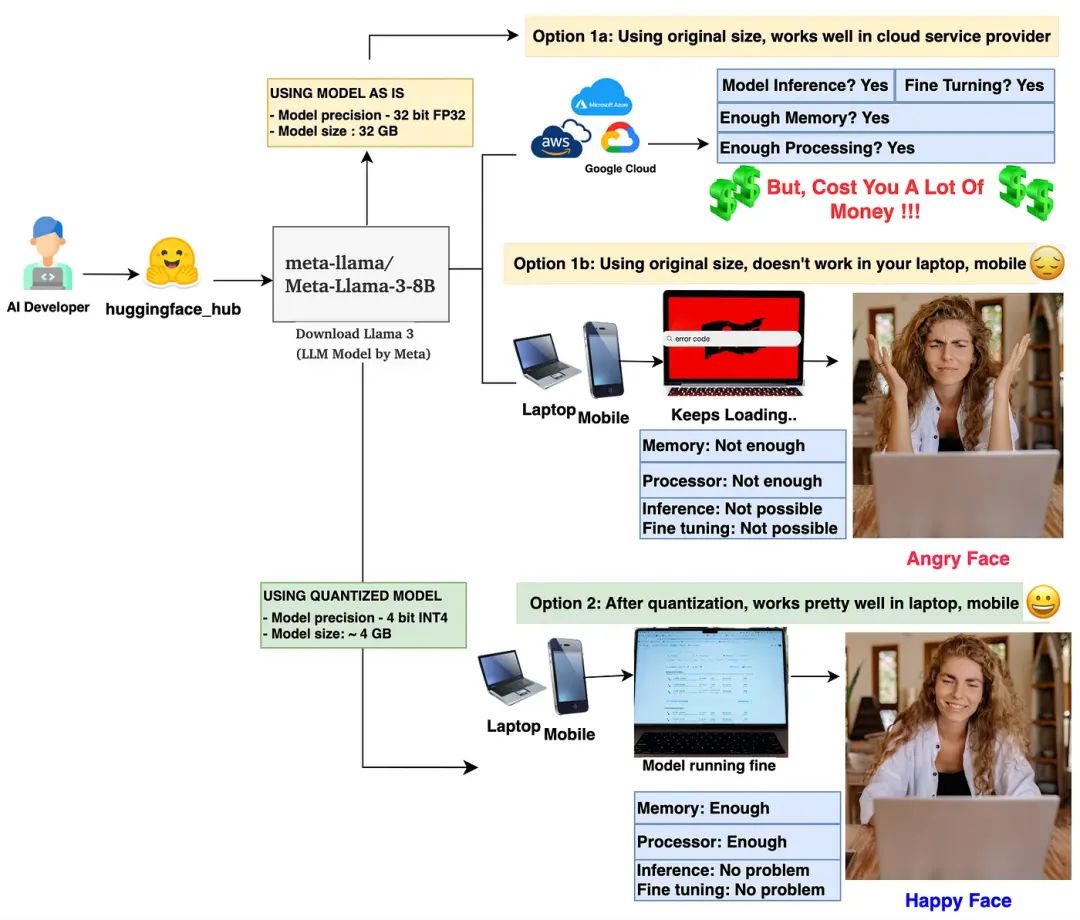
Quantization is a method of compressing larger models (such as LLMs or any deep learning model) into smaller sizes. Quantization mainly involves quantizing the model’s weight parameters and activation values. Let’s verify this statement through a simple model size calculation.Left: Base model size calculation (unit: GB), Right: Quantized model size calculation (unit: GB)In the above image, the base model Llama 3 8B has a size of 32 GB. After INT8 quantization, the size reduces to 8GB (a reduction of 75%). With INT4 quantization, the size further reduces to 4GB (about a 90% reduction). This significantly reduces the model size.
By this calculation, a large model with 7B FP16 deployment weights 14G, INT8 is 8G, and INT4 is halved to 4G.
Quantization serves two main purposes:
Reduce memory requirements.
Enhance inference performance.
This not only helps deploy larger models on limited hardware resources but also speeds up the model’s inference, with acceptable accuracy loss, making it a worthwhile approach.
How Does Quantization Work? Simple Mathematical Derivation
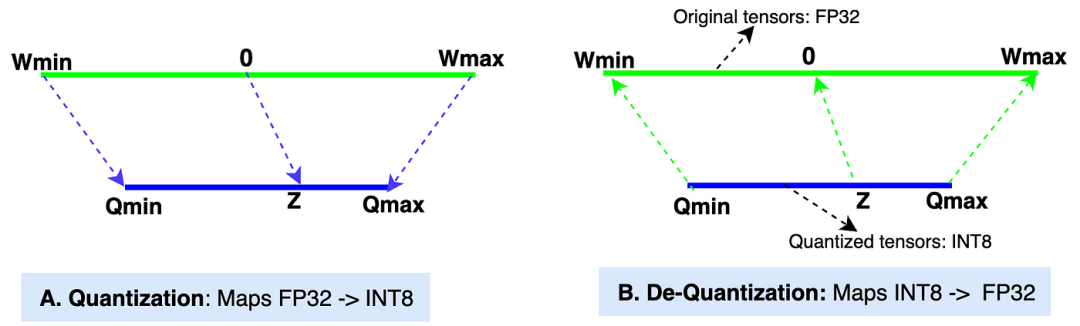
Technically, quantization maps the model’s weight values from higher precision (such as FP32) to lower precision (such as FP16, BF16, INT8). While there are many quantization methods available, in this article, we will learn one widely used method called linear quantization. Linear quantization has two modes: A. Asymmetric Quantization and B. Symmetric Quantization. We will learn these two methods one by one.A. Asymmetric Linear Quantization: The asymmetric quantization method maps values from the original tensor range (Wmin, Wmax) to the quantized tensor range (Qmin, Qmax).
Wmin, Wmax: Minimum and maximum values of the original tensor (data type: FP32, 32-bit float). In most modern LLMs, the default data type for weight tensors is FP32.
Qmin, Qmax: Minimum and maximum values of the quantized tensor (data type: INT8, 8-bit integer). We can also choose other data types like INT4, INT8, FP16, and BF16 for quantization. In our example, we will use INT8.
Scale value (S): During quantization, the scale value reduces the original tensor values to obtain the quantized tensor. During dequantization, it magnifies the quantized tensor values to obtain the dequantized values. The scale value’s data type is the same as the original tensor, which is FP32.
Zero point (Z): The zero point is a non-zero value in the quantized tensor range that directly maps to the value 0 in the original tensor range. The zero point’s data type is INT8 because it is within the quantized tensor range.
Quantization: The “A” section in the figure shows the quantization process, i.e., mapping from [Wmin, Wmax] to [Qmin, Qmax].
Dequantization: The “B” section in the figure shows the dequantization process, i.e., mapping from [Qmin, Qmax] to [Wmin, Wmax].
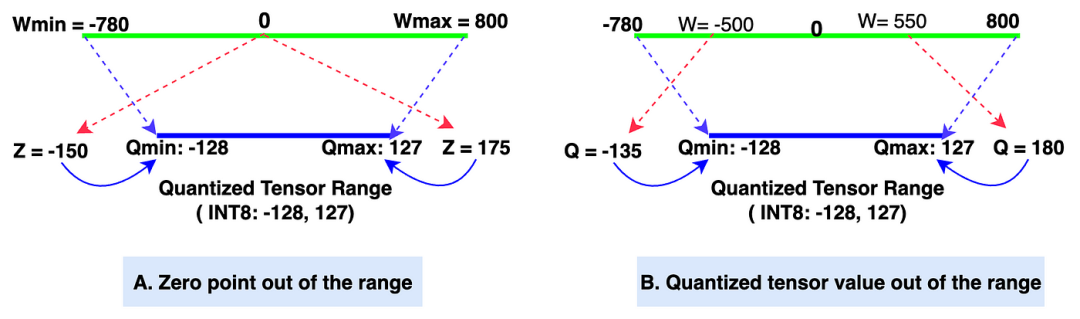
So, how do we derive the quantized tensor values from the original tensor values? It’s actually quite simple. If you remember high school math, you can easily understand the derivation process below. Let’s go step by step (it is recommended to refer to the charts above for clearer understanding during the derivation of the formulas).Detail 1: What if the Z value is out of range? Solution: Use simple if-else logic to adjust the Z value to Qmin if it is less than Qmin; if Z is greater than Qmax, adjust it to Qmax. This method is detailed in section A of the chart.Detail 2: What if the Q value is out of range? Solution: In PyTorch, there is a function called clamp that can adjust values to a specific range (in our example, from -128 to 127). Therefore, the clamp function will adjust the Q value to Qmin if it is below Qmin, and adjust the Q value to Qmax if it is above Qmax.|Zero point and Quantized tensor out-of-range
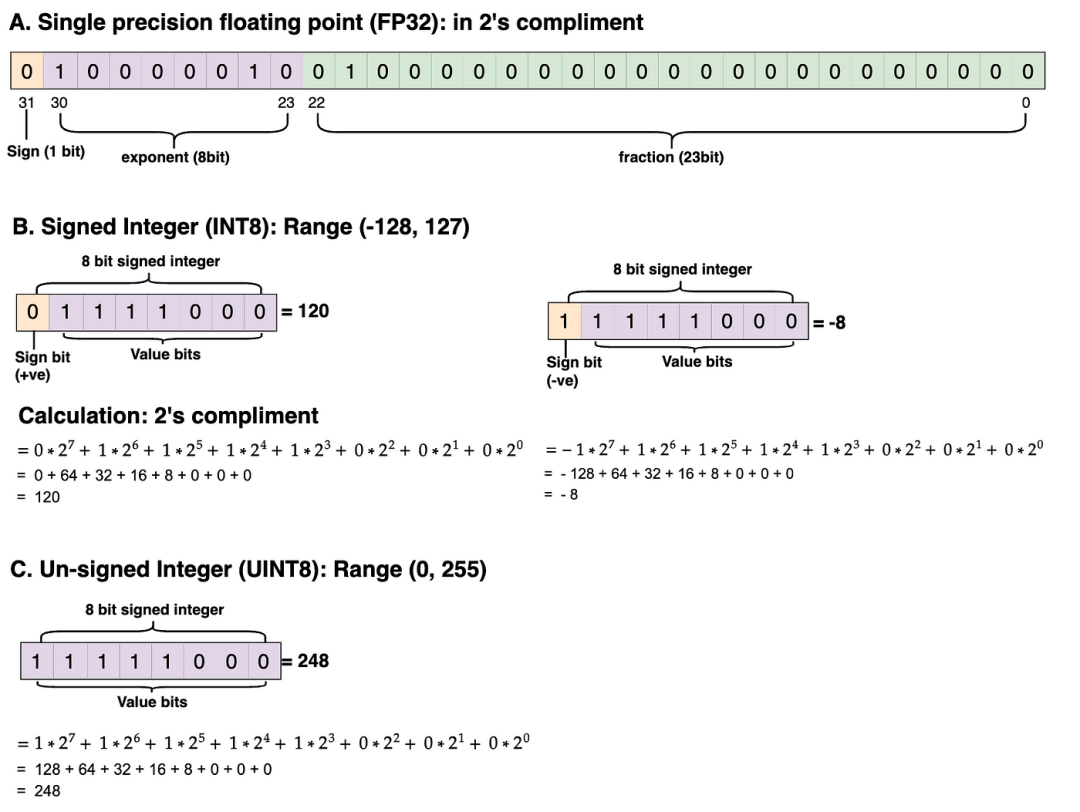
The range of quantized tensor values is -128 to 127 (INT8, signed integer data type). If the data type of the quantized tensor value is UINT8 (unsigned integer), the range is from 0 to 255.
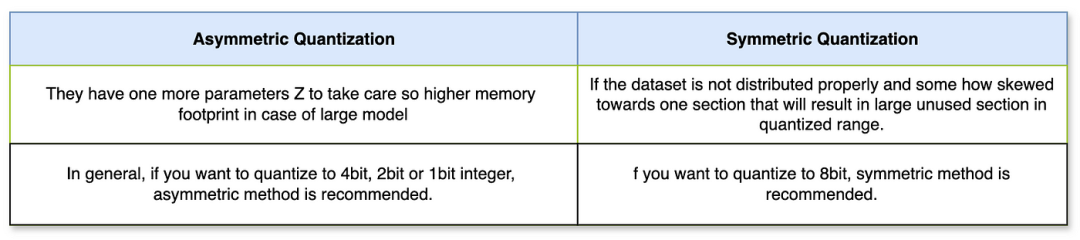
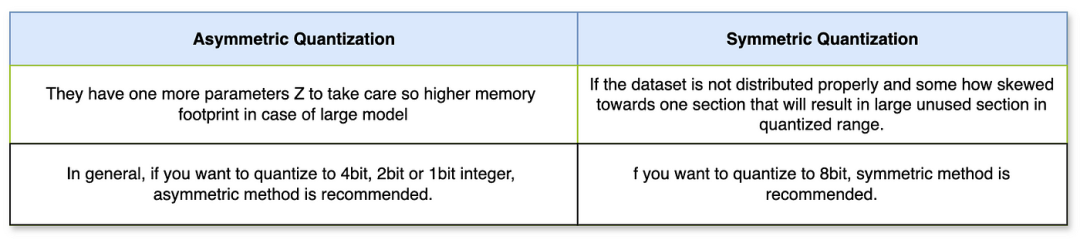
B. Symmetric Linear Quantization: In the symmetric method, the zero point in the original tensor range maps to the zero point in the quantized tensor range. Therefore, this is called symmetric quantization. Since zero is mapped to zero on both sides of the range, there is no zero point (Z) in symmetric quantization. The overall mapping occurs between the ranges of the original tensor (-Wmax, Wmax) and the quantized tensor (-Qmax, Qmax). The following diagram shows the symmetric mapping in both quantization and dequantization cases.Symmetric Linear QuantizationSince we have already defined all parameters in the asymmetric section, they also apply here. Let’s move on to the mathematical derivation of symmetric quantization.Differences Between Asymmetric and Symmetric Quantization:Now that you understand the what, why, and how of linear quantization, this leads us to the final part of this article, which is the code section.
Quantization and Dequantization of LLM Weight Parameters
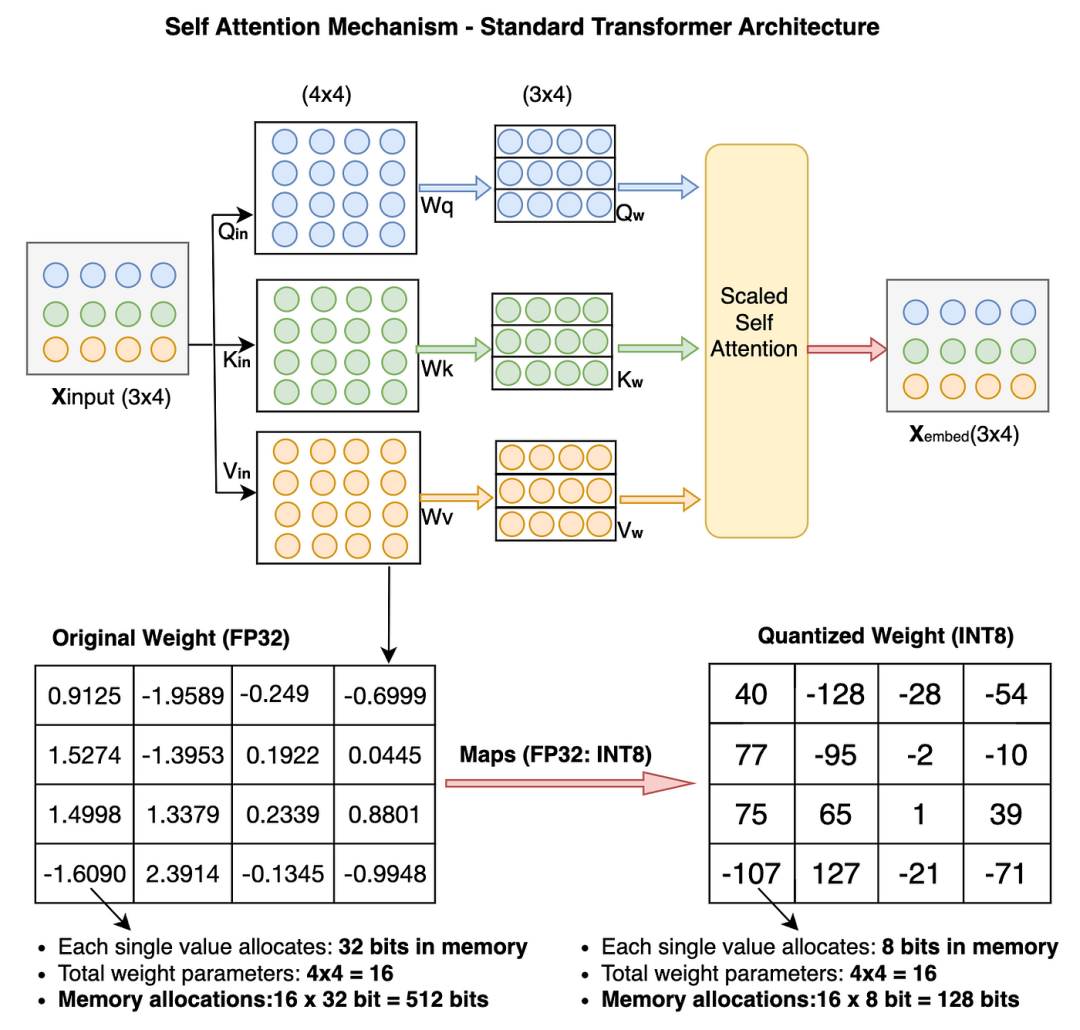
Quantization applies to the model’s weights, parameters, and activation values.To simplify, we will only quantize the weight parameters in the PyTorch example. Let’s quickly look at the changes in the weight parameter values in the quantized Transformer model.Quantization of weight parameters in transformer architectureWe quantized 16 original weight parameters from FP32 to INT8, reducing memory usage from 512 bits to 128 bits (a reduction of 25%). For large models, the reduction is even more significant.Below, you can see the distribution of data types (such as FP32, signed INT8, and unsigned UINT8) in actual memory. I have performed actual calculations in 2’s complement. Feel free to practice the calculations yourself and verify the results.Example of FP32, INT8, UINT8 data type distribution and calculationAsymmetric quantization code: Let’s write the code step by step.First, we assign random values to the original weight tensor (size: 4×4, data type: FP32).
# !pip install torch; Install the torch library if you haven't already.
# Import the torch library
import torch
original_weight = torch.randn((4,4))
print(original_weight)
Original FP32 weight tensorDefine two functions, one for quantization and the other for dequantization.
def asymmetric_quantization(original_weight):
# Define the data type you want to quantize to. In our example, it is INT8.
quantized_data_type = torch.int8
# Get Wmax and Wmin values from the original FP32 weights.
Wmax = original_weight.max().item()
Wmin = original_weight.min().item()
# Get Qmax and Qmin values from the quantized data type.
Qmax = torch.iinfo(quantized_data_type).max
Qmin = torch.iinfo(quantized_data_type).min
# Calculate the scale value using the scaling formula. Data type - FP32.
# If you want to understand the derivation of the formula, please refer to the mathematical section of this article.
S = (Wmax - Wmin)/(Qmax - Qmin)
# Calculate the zero point value using the zero point formula. Data type - INT8.
# If you want to understand the derivation of the formula, please refer to the mathematical section of this article.
Z = Qmin - (Wmin/S)
# Check if the Z value is out of range.
if Z < Qmin:
Z = Qmin
elif Z > Qmax:
Z = Qmax
else:
# The data type of the zero point should be the same as the quantized value, which is INT8.
Z = int(round(Z))
# We have original_weight, scale, and zero_point now, we can use the formula derived in the mathematical section to calculate the quantized weights.
quantized_weight = (original_weight/S) + Z
# We will also round it and use the torch clamp function to ensure the quantized weights are within the range and remain between Qmin and Qmax.
quantized_weight = torch.clamp(torch.round(quantized_weight), Qmin, Qmax)
# Finally, convert the data type to INT8.
quantized_weight = quantized_weight.to(quantized_data_type)
# Return the final quantized weights.
return quantized_weight, S, Z
def asymmetric_dequantization(quantized_weight, scale, zero_point):
# Use the dequantization formula derived in the mathematical section.
# Also, make sure to convert the quantized weights to float type because the subtraction between two INT8 values (quantized_weight and zero_point) would yield unexpected results.
dequantized_weight = scale * (quantized_weight.to(torch.float32) - zero_point)
return dequantized_weight
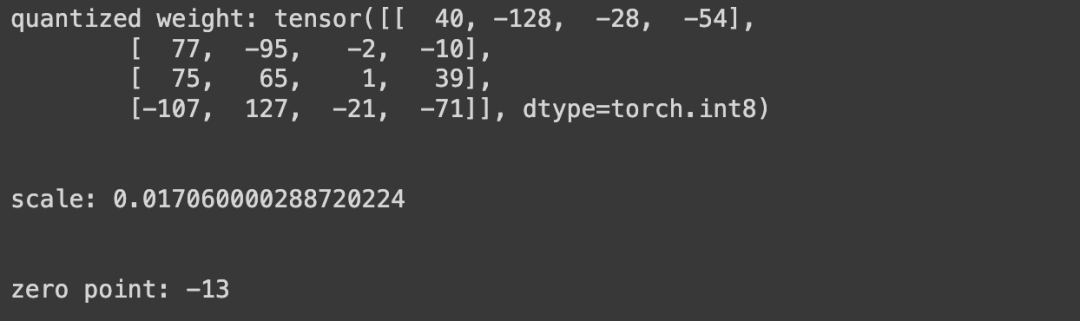
We will calculate the quantized weights, scale, and zero point by calling the asymmetric_quantization function. You can see the output results in the screenshot below, noting that the data type of the quantized weights is int8, the scale is FP32, and the zero point is INT8.
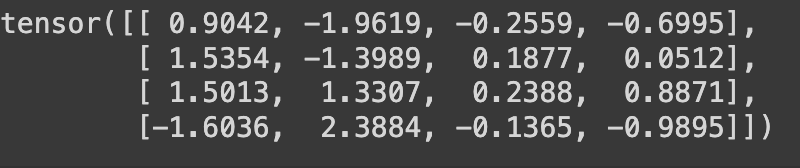
Quantized weight, scale, and zero point valueNow that we have all the values for quantized weights, scale, and zero point, let’s obtain the dequantized weight values by calling the asymmetric_dequantization function. Note that the dequantized weight values are FP32.
Dequantized weight valueLet’s calculate the quantization error to find the accuracy of the final dequantized weight values compared to the original weight tensor.
The quantization error is very small.Symmetric quantization is similar to asymmetric quantization, the only change needed is to ensure that the zero_input value is always 0 in the symmetric method. This is because in symmetric quantization, the zero_input value always maps to the 0 value in the original weight tensor. The above quantization code example:
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply to join the Natural Language Processing/PyTorch technical group.
About Us
MLNLP community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from both domestic and international backgrounds. It has developed into a well-known community for machine learning and natural language processing, aiming to promote progress among the academic and industrial sectors of machine learning and natural language processing.The community provides an open platform for communication for professionals in further education, employment, and research. Everyone is welcome to follow and join us.