1. Each large model framework has specific format requirements for its fine-tuning data.
For example, LlamaFactory supports it, and you can refer to the documentation:
https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
2. Convert Ruozhiba data into LlamaFactory data format.
import json
# Conversion function
def convert_format(original_data):
converted_data = []
for item in original_data:
converted_item = {
"instruction": item["query"],
"input": "",
"output": item["response"]
}
converted_data.append(converted_item)
return converted_data
# Read original data from file
with open("data/w10442005/ruozhiba_qa/ruozhiba_qaswift.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Convert data
converted_data = convert_format(data)
# Write converted data to file
with open("ruozhi.json", "w", encoding="utf-8") as f:
json.dump(converted_data, f, indent=2, ensure_ascii=False)3. LlamaFactory model quantization environment configuration.
Install the auto-gptq quantization tool, version 0.7.1, with the corresponding CUDA version being either 11.8 or 12.1; higher versions will cause errors.
What is inference? Simply put, it is calling the model I have trained.
What is quantization? During inference, AI models face a choice between performance and accuracy. You can choose to sacrifice accuracy to improve performance (because GPU performance is limited), but the reverse is not possible (after the model is trained).
Quantization reduces the storage precision of parameters (the default weight for AI is F32; quantization can change it to F16, QINT8, QINT4, QINT2). Sacrificing very little accuracy from F32 to F16 can significantly enhance performance.
Methods for accelerating model inference: pruning, distillation, quantization; the first two mainly depend on experience (unreliable) and are not commonly used anymore.
4. Quantization operations of LlamaFactory.
(1) Quantization during training is called Qlora, which is Lora fine-tuning with added quantization.
(2) Quantization during model deployment (exporting). Quantization needs to be done after exporting.
(3) Quantization calibration: the quantization process needs to prevent the increase of errors.

(4) Perform the worst accuracy quantization.
Quantize our merged model to INT2. You need to install auto-gptq and restart the LlamaFactory web UI.
pip install auto-gptq
pip install optimum
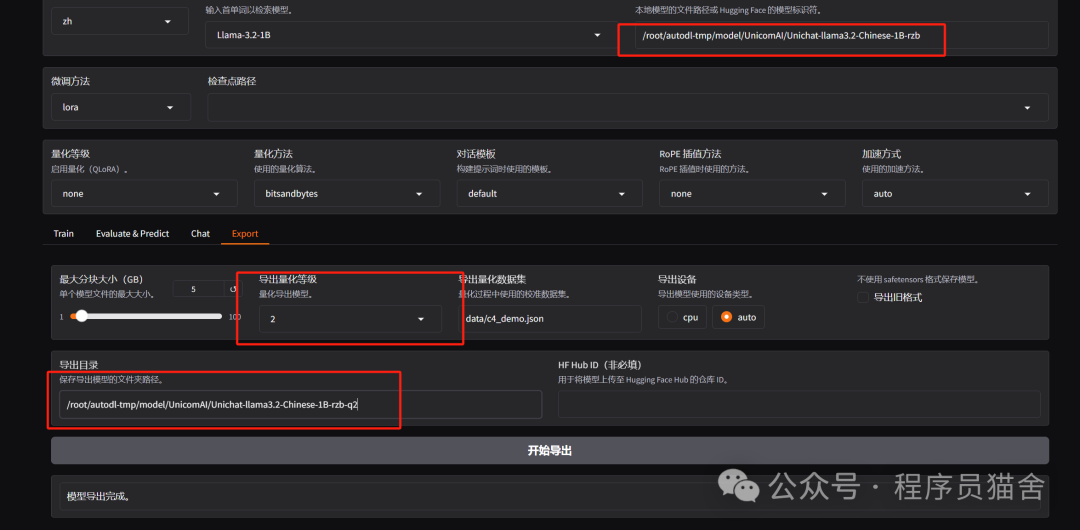
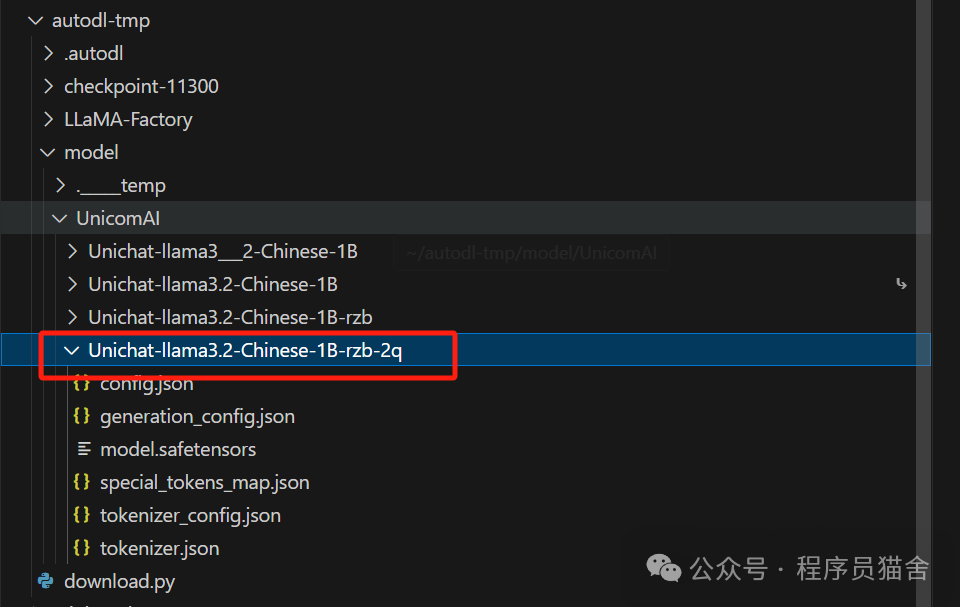
Generate the model data after quantization:
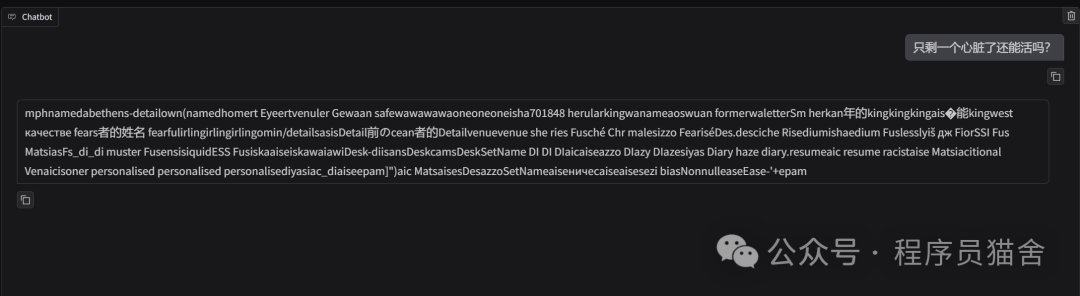
Using the quantized model for inference will reveal that an overly quantized model performs very poorly.
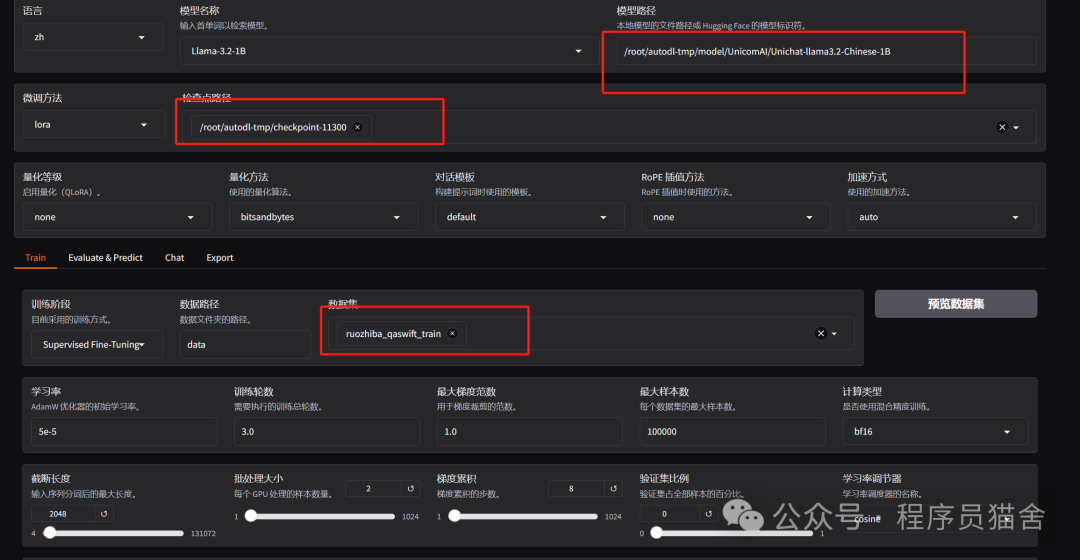
5. How to continue training the model based on previous data.
(1) Select the base model, choose the checkpoint path (previously trained weights), and then load the training data to retrain.
(2) You can also merge the base model and the previously trained weights, then load the data to continue training.
(3) You need to delete the saves folder.