
Jishi Introduction
SpinQuant combines learnable rotation matrices to achieve optimal network accuracy, quantizing weights, activations, and KV cache to a 4-bit width. On the LLaMA-2 7B model, SpinQuant reduces the accuracy gap in Zero-Shot inference tasks to only 2.9 points compared to the full-precision model, outperforming LLM-QAT by 19.1 points and exceeding SmoothQuant by 25 points. >>Join the Jishi CV Technology Group to stay at the forefront of computer vision
TL;DR
4-bit LLM quantization using learnable rotation matrices.
Post-Training Quantization techniques can be applied to weights, activations, and KV caches, significantly reducing the memory, latency, and energy consumption of large language models. However, when outliers are present, there can be substantial quantization errors.
A method to remove outliers is to apply a rotation matrix to the activation and weight parameter matrices. This operation aids quantization.
This work identifies a set of usable rotation matrix parameters that keep the output of the full-precision transformer architecture unchanged while improving quantization accuracy. Additionally, the authors found that some rotation matrices perform better than others in terms of quantization, with a difference of 13 points in Zero-Shot inference performance across downstream tasks.
Building on this discovery, this paper proposes a new method called SpinQuant. SpinQuant integrates learnable rotation matrices for optimal network accuracy, quantizing weights, activations, and KV caches to a 4-bit width. On the LLaMA-2 7B model, SpinQuant reduces the accuracy gap in Zero-Shot inference tasks to only 2.9 points compared to the full-precision model, surpassing LLM-QAT by 19.1 points and exceeding SmoothQuant by 25 points. Furthermore, SpinQuant outperforms the contemporaneous QuaRot, which uses random rotations to remove outliers. For the challenging LLaMA-3 8B model, SpinQuant reduces the gap with the full-precision model by 45.1% compared to QuaRot.
Table of Contents
1 SpinQuant: LLM Quantization with Learnable Rotation Matrices (from Meta) 1 SpinQuant Paper Interpretation 1.1 Background of SpinQuant 1.2 Outlier Issues in Quantizing Large Models 1.3 Parameterization of Rotation Matrices 1.4 Cayley Optimization of Rotation Matrices 1.5 Experimental Setup 1.6 Main Experimental Results 1.7 Comparison of Learned Rotation Matrices and Random Hadamard Matrices 1.8 Comparison with QuaRot 1.9 Analysis of the Functionality of Rotation Matrices 1.10 Speed Tests
1 SpinQuant: LLM Quantization with Learnable Rotation Matrices
Paper Title: SpinQuant: LLM Quantization with Learned Rotations
Paper URL:
http://arxiv.org/pdf/2405.16406
Code Link:
http://github.com/facebookresearch/SpinQuant
1.1 Background of SpinQuant
Large language models (LLMs) have demonstrated impressive performance across many disciplines. State-of-the-art open-source models (such as LLaMA, Mistral, etc.) and some specialized LLMs (like GPT, Gemini, etc.) are widely used for general chat assistants, medical diagnosis, computer game content generation, coding copilots, and more.
To meet such high demand, inference costs have become a practical issue. Many effective techniques, such as Post-Training Quantization, reduce weights (or activations) to low precision, thereby reducing memory usage and significantly improving latency. This is important not only for server-side inference but also for the deployment of small LLMs on edge devices.
When applying quantization, outliers pose a challenge as they stretch the quantization range, resulting in very few effective bits to handle the numerical values of most models. Previous works have attempted to mitigate this issue, such as SmoothQuant[1], AWQ[2] which balances the quantization difficulty between weights and activations, or Atom[3] which uses mixed precision to handle outliers.
SpinQuant focuses on a new angle: multiplying weight matrices by rotation matrices to reduce outliers and improve quantizability. Inspired by SliceGPT[4], SpinQuant constructs rotation matrices from identity mappings and integrates them into nearby weights without affecting the overall network output. By applying these random rotation matrices, a distribution of weights and activations without outliers can be generated, facilitating quantization.
In addition to using the aforementioned random rotations, this paper finds that the performance of quantized networks can vary significantly under different rotation matrices. For instance, the average accuracy of Zero-Shot downstream inference tasks can vary by as much as 13 points based on the choice of rotation matrix. Therefore, this paper proposes SpinQuant, which integrates and optimizes rotation matrices to minimize the loss introduced by the quantized model. The authors fix the weight parameters and use Cayley SGD[5], a mature technique for optimizing orthogonal matrices. This optimization does not alter the output of the full-precision network but refines the intermediate activations and weights to make them more quantization-friendly.
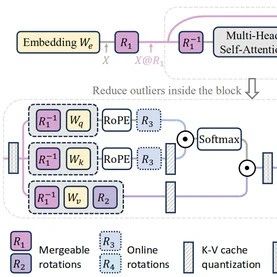
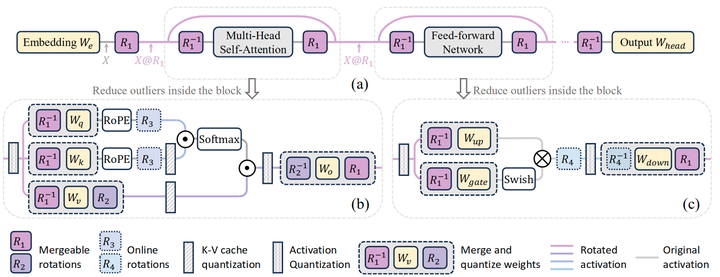
In SpinQuant, the authors introduce two rotation strategies tailored for different complexity levels: SpinQuant (no had) and SpinQuant (had). Here, ‘had’ refers to Hadamard rotation matrices. In SpinQuant (no had), as shown in Figure 1 (b), the authors implement Shortcut Rotation Matrices and Rotation Matrices, which can be directly absorbed into their respective weight matrices. During inference, the original weights are simply replaced with the rotated quantized weights, eliminating the need to modify the forward process. Conversely, in SpinQuant (had), specifically for scenarios requiring low-bit quantization of KV cache or activations (e.g., 4-bit), online Hadamard rotation matrices are further combined to address outliers in MLP and KV cache activations.
1.2 Outlier Issues in Quantizing Large Models
Quantization reduces the precision of weights and activations in neural networks to save memory and reduce latency. The quantization process can be expressed as:
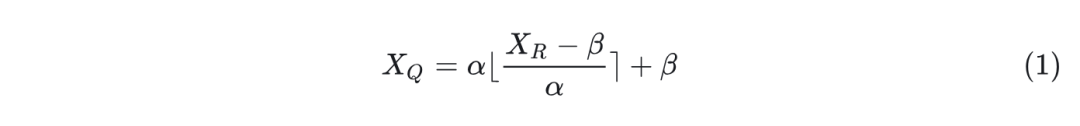
In symmetric quantization, . In asymmetric quantization, . Here, is the quantized tensor, is the real-valued FP16 tensor, and is the number of bits. For LLMs, the presence of outliers stretches the range of weights and activations, increasing the reconstruction error of normal values, as shown in Figures 2 and 3.
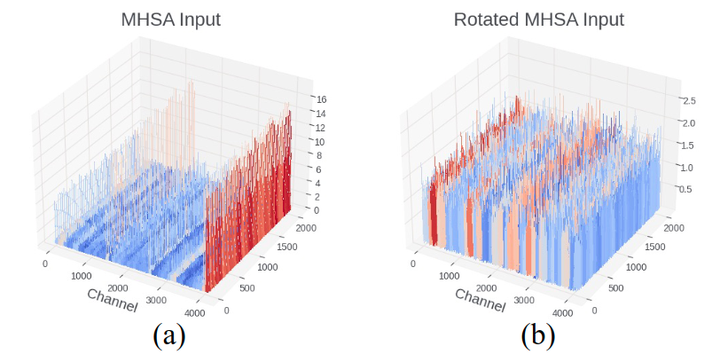
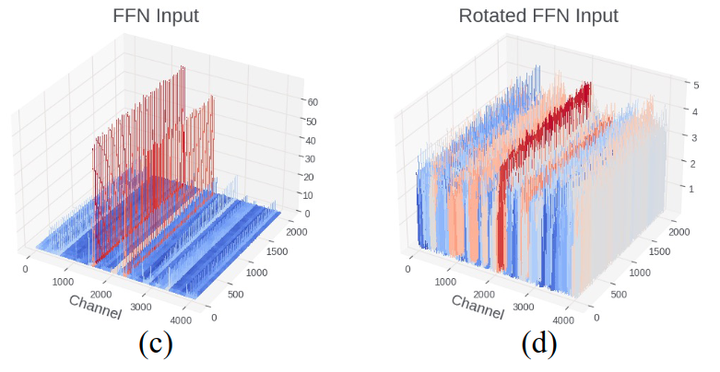
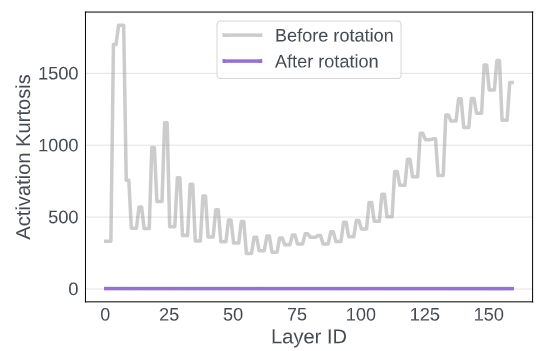
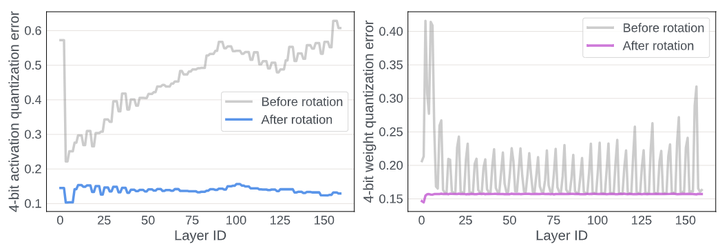
Figure 4 illustrates the kurtosis measurement of activations before and after Rotation, quantifying the “tails” of the probability distribution of real-valued random variables. A larger indicates more outliers, while indicates a distribution similar to Gaussian. In Figure 4, the activation distribution in the transformer contains many outliers, with exceeding 200. However, after multiplying these activations by random rotation matrices, the of all layers becomes approximately 3, indicating a more Gaussian-shaped distribution that is easier to quantize. Figure 5 confirms this, showing that the quantization error of activations significantly decreases after Rotation.
Random rotations can produce high variance
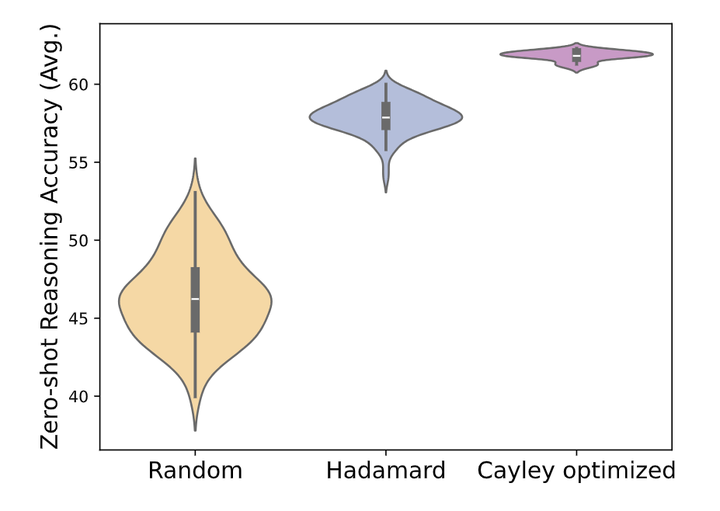
Interestingly, while random rotations can yield better quantization, not all random rotations produce the same quantization results. To demonstrate this, the authors conducted 100 random trials, testing the average accuracy of LLaMA-2 7B under Zero-Shot quantized to 4-bit weights and 4-bit activations. As shown in Figure 6, there is significant variance in performance, with the best random rotation matrix outperforming the worst by 13 points. Random Hadamard matrices outperform random rotation matrices, consistent with findings in[6] that Hadamard matrices produce stricter bounds on weight maxima. However, even random Hadamard rotation matrices exhibit non-negligible variance in final performance, up to 6 points.
Given the significant differences arising from various rotation schemes, a natural question arises: is it possible to optimize rotations for the best quantization results? This paper proposes a feasible framework and rotation learning aimed at quantization to answer this question, achieving high accuracy across 7 models and 4 low-bit quantization settings.
1.3 Parameterization of Rotation Matrices
SpinQuant is a framework that integrates and optimizes rotation matrices to improve the accuracy loss from quantization. The authors first define the parameterization of rotations for popular LLM architectures, which includes two mergeable rotation matrices that produce rotation-invariant full-precision networks, as well as two online Hadamard rotation matrices to further reduce extreme activation and outlier quantization in KV caches. They then demonstrate how to optimize these rotation matrices on the Stiefel manifold with a target loss.
Activations in Rotation Residuals
As shown in Figure 1 (a), the authors rotate the activations in the residual path by multiplying the embedded output with the random rotation matrix. This rotation eliminates outliers and simplifies the quantization of input activations. To maintain numerical invariance, the authors multiply before the attention and FFN. Thus, when quantization is absent, the output of the full-precision network remains unchanged regardless of whether rotation is applied. In pre-Norm LLMs like LLaMA, it is possible to convert the transformer network into a rotation-invariant network by merging the scale parameter into the weight matrix after RMSNorm. Rotation matrices can be integrated into their corresponding weight matrices, as shown in Figures 1 (b) and (c). After absorption, no new parameters are introduced into the network. Now, can freely modify without affecting the precision of the floating-point network.
Activations in Rotation Attention
As shown in Figure 1 (b), in attention, the authors propose to multiply the value projection matrix by head-wise and the output projection matrix by . The shape of is , allowing independent selection across different layers. Numerical invariance is illustrated in Figure 7, where these two rotation matrices can be canceled in the full-precision network since there are no operators between and . At the same time, it can improve the quantization of input activations to the out projection of values without introducing any new parameters into the network.

The authors represent the quantization method using only and as SpinQuant (no had). Compared to previous quantization methods, this approach can easily achieve significant accuracy improvements, reducing the gap between W4A8 quantized LLMs and their full-precision models by 0.1 – 2.5 points in Zero-Shot commonsense reasoning average accuracy.
Additional Non-Absorbable Rotation Matrices
To further enhance the suppression of outliers in low-bit (e.g., 4-bit) activation quantization, the authors incorporate Hadamard matrix multiplication within the FFN block (as shown in Figure 1 (c)), reducing outliers entering the Down Projection layer. Hadamard rotations can be computed using fast Hadamard transforms and introduce very low overhead for inference latency. Similarly, when low-bit KV cache quantization is required, the Hadamard matrix ( ) in Figure 1 (b) can be inserted. The quantization method using is represented as SpinQuant (had).
1.4 Cayley Optimization of Rotation Matrices
It has been determined that adding the four rotation matrices in Figure 1 can improve quantization performance while maintaining numerical invariance in the full-precision network. Since these are online rotation operations, meaning they cannot be absorbed into the weight matrices, the authors retain them as Hadamard matrices. This is because online Hadamard transformations can be efficiently implemented without significant overhead. The authors then define the optimization objective as identifying the optimal rotation matrix that minimizes the final loss of the quantized network:
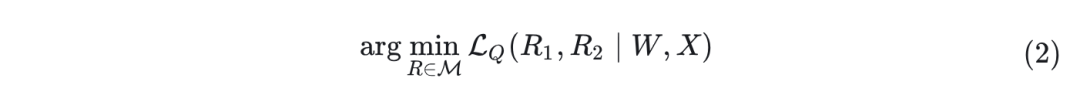
Here, represents the Stiefel manifold, which is the set of all orthogonal matrices. denotes the task loss on the calibration set, such as cross-entropy. It is a function of given fixed pre-trained weights and input tensors, as well as the quantization function in the network. To optimize the rotation matrices on the Stiefel manifold, the authors employ the Cayley SGD method, an efficient optimization algorithm on the Stiefel manifold. More specifically, in each iteration, the update of the rotation matrix is as follows:
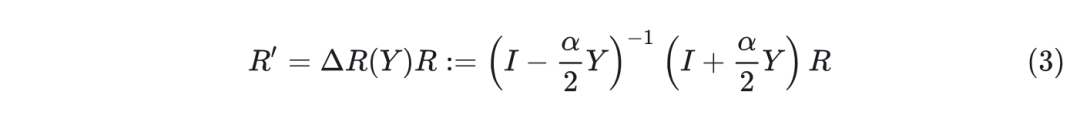
Where is the Cayley transform of the skew-symmetric matrix (i.e., ). It is computed from a projection of the gradient of the loss function:

The results indicate that if is orthogonal, is always orthogonal, then is guaranteed to be orthogonal ( . Equation 3 requires a matrix inverse, and the new rotation matrix can be computed through efficient fixed-point iterations. Overall, this method takes only times the computation time of the naive SGD algorithm per iteration while preserving the property of orthogonality.
The authors apply Cayley SGD method to solve for in Equation 2, while keeping the weight parameters in the network frozen. Only occupies about of the weights and is constrained to be orthogonal. Therefore, the floating-point network remains unchanged, and the rotations only affect quantization performance.
By using Cayley optimization to update the rotation matrix over 100 iterations on the 800-sample WikiText2 calibration set, the authors obtain a rotation matrix that outperforms the best random matrices and random Hadamard matrices in 100 random seeds, as shown in Figure 6. The rotations optimized through Cayley exhibit minimal variance when initialized from different random seeds. The rotation matrices are initialized using random Hadamard matrices.
1.5 Experimental Setup
The authors conducted experiments on LLaMA-2 (7B/13B/70B), LLaMA-3 (1B/3B/8B), and Mistral 7B models, evaluating the proposed SpinQuant across 8 Zero-Shot commonsense reasoning tasks. These tasks include BoolQ, PIQA, SIQA, HellaSwag, Winogrande, ARC-easy, ARC-challenge, and OBQA. Additionally, perplexity scores on the WikiText2 test set are reported.
The authors use Cayley SGD to optimize the rotation matrix , both initialized as random Hadamard matrices, while keeping all network weights unchanged. is the residual rotation, shaped as ( ). is the rotation head-wise for each attention, shaped as ( ). The learning rate starts at 1.5 and linearly decays to 0. The authors use 800 samples from WikiText-2 to iteratively optimize for 100 iterations. LLaMA-3 1B/3B/8B requires approximately 13/18/30 minutes, while LLaMA-2 7B/13B requires minutes. LLaMA-2 requires hours, and for Mistral, it requires 16 minutes.
In the main results, the authors optimize the rotation matrices for activation quantization while keeping the weights at 16-bit. After learning the rotation matrices, GPTQ is applied to the rotated weights. The calibration set follows GPTQ’s approach, using 128 samples from WikiText-2 with a sequence length of 2048 as the quantization calibration set.
1.6 Main Experimental Results
In Figure 8, the authors provide guidelines on which rotation schemes to choose in practice using 7 models and 4 commonly used bit-width settings. Note that SpinQuant (no had) uses only the learned rotation matrices, and after learning the rotation matrices, they can be merged into the corresponding model weights during inference. Using SpinQuant (no had) only requires replacing the original model weights with the rotated model weights, without modifying the forward propagation or any other Kernel support. SpinQuant (had) includes learned rotation matrices and online Hadamard rotation matrices that can be computed using fast Hadamard Kernels, introducing only about additional latency.
As shown in Figure 8, in the case of 4-bit weights and 8-bit activations, using SpinQuant (no had) can easily achieve good performance. For example, SpinQuant (no had) improved the Mistral 7B quantized at 4-8-8 by 10.5 points. In LLaMA-3-8B, compared to GPTQ under 4-8-16 settings, SpinQuant (no had) achieved an improvement of over 4.1 points, with only a 1.0 point accuracy gap from the full-precision network. In scenarios where these activations do not require severe quantization, SpinQuant (no had) is already a viable solution, with additional online Hadamard rotations yielding marginal benefits.
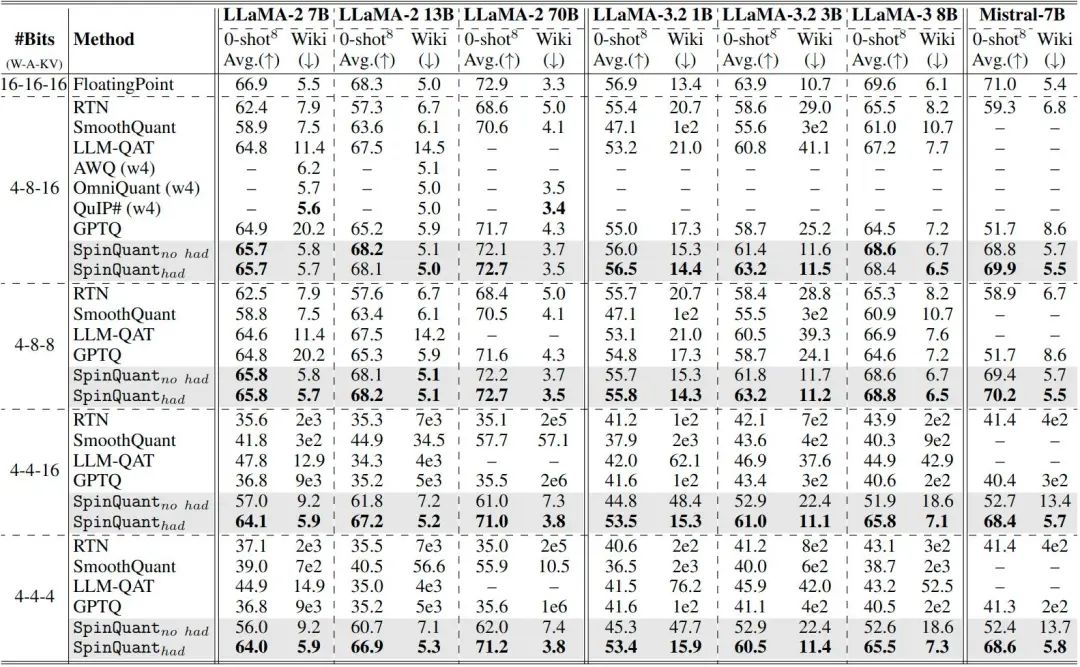
In contrast, when activations are quantized to 4-bit, accuracy significantly declines, with most previous methods failing to produce meaningful results. SpinQuant (no had) reduces the gap by as much as 20 points. On the LLaMA-2 model with 4-4-4 quantization, SpinQuant (no had) significantly outperformed LLM-QAT on the 7B model and surpassed SmoothQuant by 20.2 points on the 13B model, reducing the gap with the corresponding full-precision models from 22.0/27.8 points to 10.9/7.6 points. Nevertheless, the gap between the full-precision models remains non-negligible.
In this case, SpinQuant (had) can further increase accuracy by over 5 points and reduce the gap with the corresponding FP networks to 2-4 points. In 4-4-4 quantized LLaMA-2 7B/13B/70B models, SpinQuant (had) leaves only 2.9/1.4/1.7 points accuracy gap with the corresponding full-precision networks, significantly outperforming previous SOTA methods by 19.1/16.4/15.3 points.
Furthermore, compared to state-of-the-art weight-only quantization methods like OmniQuant, AWQ, and QuIP#, SpinQuant achieves similar perplexity on the Wiki dataset with 4-bit weights and 8-bit activations without using vector quantization techniques. These results indicate that SpinQuant is suitable for various scenarios and achieves state-of-the-art performance.
1.7 Comparison of Learned Rotation Matrices and Random Hadamard Matrices
In Figure 9, the authors compare random Hadamard rotations with SpinQuant optimized rotations. Using learned rotations consistently improves accuracy across various models and bit-width configurations, regardless of the settings. Notably, in Mistral7B quantization, SpinQuant (had) ensures improvements of over 15.7 points compared to using random Hadamard rotations. Given the low time cost of optimizing rotation matrices (only 30 minutes for smaller models, up to 3.5 hours for 70B models), the authors advocate for using optimized rotations for precise quantization of LLMs.

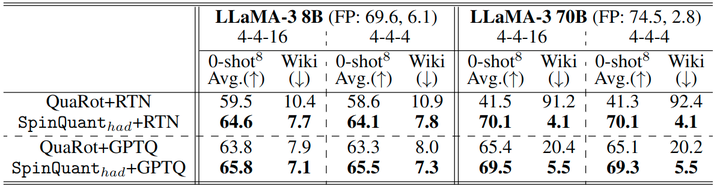
1.8 Comparison with QuaRot
QuaRot[8] exhibits significant accuracy differences in quantized networks: when quantizing the 70B model with W4A4 and W4A4KV4, it experiences accuracy drops of 28.1 and 33.2 points. This degradation stems from the inherent noise of using random rotation matrices, introducing high variance and insufficient robustness. In contrast, SpinQuant (had) consistently maintains high accuracy across various configurations, achieving improvements of 2.0 to 28.6 points over QuaRot, as shown in Figure 10, while utilizing fewer online Hadamard matrices (2 per block in SpinQuant (had) vs. 4 per block in QuaRot).
Moreover, the effective reduction of block-wise outliers in SpinQuant enables SpinQuant (no had) to deliver optimal performance in the W4A8 setting. SpinQuant (no had) can be implemented simply by replacing model weights with the rotated weights, making it simpler and more efficient than QuaRot, which requires modifications to the model architecture and special kernel support.
1.9 Analysis of the Functionality of Rotation Matrices
The fundamental principles behind rotating weights and activations can be illustrated through a simple example. Consider an activation represented as a 2D vector, where one entry consistently receives a higher activation magnitude than another, as shown in Figure 11 (a). Quantizing these components typically leads to a dominant quantization range, adversely affecting the precision of .
From an information entropy perspective, expanding each axis to fully utilize the available quantization range maximizes the representational capacity of each axis. Thus, matrix rotation emerges as an intuitive solution. In a 2D scenario, rotating the axes by 45° equalizes the value representation range across the axes, as shown in Figure 11 (b). Assuming the network is a black box, unaware of the exact activation distribution, uniformly rotating all axes (e.g., 45° in 2D) can optimize the distribution uniformity on each axis, partially explaining why Hadamard Rotation often outperforms random Rotation matrices.
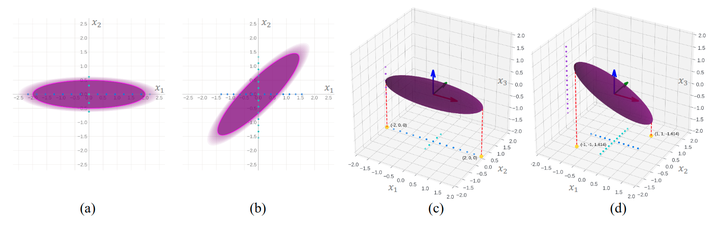
Furthermore, if the activation distribution is known, treating the network as a white box during quantization allows for the discovery of rotations that are more optimized than Hadamard. For example, in the 3D scenario described in Figures 11 (c-d), where the magnitude of is 4 times larger than and , rotating along can redistribute the maximum from [2, 0.5, 0.5] to . However, there may exist more optimal rotation strategies, and learning rotations can help identify the most effective rotation for a given distribution.
This opens up interesting research avenues, such as determining the closed-form solution for the optimal rotation matrix given known outlier axes and magnitudes of the activation distribution. Additionally, whether this theoretically computed rotation matrix can yield optimal quantization performance is worth exploring in future research.
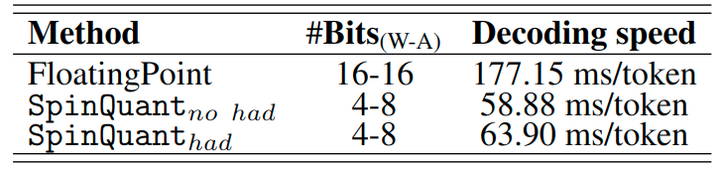
1.10 Speed Tests
The authors measured the end-to-end training speed of the LLaMA-3 8B model using W16A16 and W4A8 configurations on a MacBook M1 Pro CPU (OS version 14.5). The results in Figure 12 indicate that 4-bit quantization produces approximately a 3× speedup compared to 16-bit models. Comparing SpinQuant (had) with SpinQuant (no had), online Hadamard introduces an 8% latency overhead. Thus, the simplicity of SpinQuant (no had) is a trade-off against the high accuracy of SpinQuant (had) under low-bit settings.
References
-
^SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models -
^AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration -
^Atom: Low-bit Quantization for Efficient and Accurate LLM Serving -
^SliceGPT: Compress Large Language Models by Deleting Rows and Columns -
^Efficient Riemannian Optimization on the Stiefel Manifold via the Cayley Transform -
^QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks -
^Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks -
^Quarot: Outlier-free 4-bit inference in rotated llms

Reply “Jishi Live” in the public account backend to access 100+ Jishi technical live broadcast replays + PPT
Jishi Insights

# Jishi Platform Signed Author#

Tech Beast
Zhihu: Tech Beast
Master’s student in the Department of Automation, Tsinghua University, Class of 2019
Research Area: AI Edge Computing (Efficient AI with Tiny Resources): Focusing on model compression, search, quantization, acceleration, additive networks, and their combination with other tasks to better serve edge devices.
Selected Works
