Written by / TensorFlow Model Optimization Team

We are pleased to announce the release of the Quantization Aware Training (QAT) API, which is part of the TensorFlow Model Optimization Toolkit. With QAT, you can leverage the advantages of quantization in performance and size while maintaining accuracy close to the original. This work is part of our development roadmap, aimed at supporting the development of smaller and faster machine learning (ML) models. For more background knowledge, please refer to previous articles on Post-training Quantization, Float16 Quantization, and sparsity (Pruning).
-
TensorFlow Model Optimization Toolkithttp://tensorflow.google.cn/model_optimization
-
Development Roadmaphttps://tensorflow.google.cn/model_optimization/guide/roadmap
Quantization Can Lead to Loss
Quantization is a method to reduce the parameters and computation of ML models at the cost of a certain degree of precision loss. This process can improve the execution performance and efficiency of the model. For example, the model size produced by TensorFlow Lite 8-bit integer quantization can shrink up to one-fourth, computation speed can increase by 1.5 to 4 times, and CPU power consumption is lower. Additionally, quantization allows models to run on dedicated neural network accelerators (like Edge TPU in Coral), but the supported data types are usually limited.
-
TensorFlow Litehttps://tensorflow.google.cn/lite/performance/quantization_spec
However, the process of converting from high precision to low precision can indeed lead to loss. As shown in the figure below, quantization compresses a small number of floating-point values into a fixed number of information storage buckets.
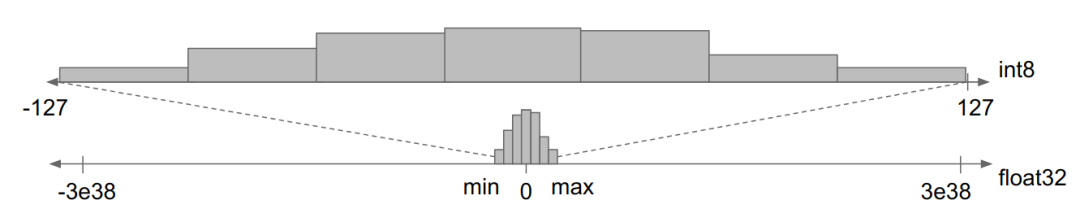
Mapping a small range of float32 values to int8 is a lossy conversion, as int8 has only 255 information channels
This process leads to information loss. The model’s parameters (or weights) can now only take a small number of values, while small differences between values are lost. For example, all values in the range [2.0, 2.3] can now only be represented in one storage bucket. This is similar to rounding errors when representing decimals with integers.
There are other causes of loss. For instance, when using these lossy values in multiple multiply-accumulate calculations, the loss will accumulate. Moreover, during the next computation, the int8 values, which need to be accumulated as int32 integers, will be converted back to int8, introducing more computational errors.
Quantization Aware Training
The core idea of QAT is that low-precision inference time computation can be simulated during the forward pass of the training process. This research achievement is credited to the original innovation of Skirmantas Kligys, a member of the Google Mobile Vision team. It treats quantization error as noise during the training process and accounts for it in the overall loss, while the optimization algorithm attempts to minimize it. As a result, the model can learn parameters that are more robust to quantization.
-
Research Achievementhttps://arxiv.org/abs/1712.05877
If training is not applicable, please refer to Post-training Quantization, which is also part of TensorFlow Lite model conversion. QAT is also very useful if researchers and hardware designers want to experiment with various quantization strategies (beyond those supported by TensorFlow Lite) and/or simulate the impact of quantization on accuracy across different hardware backends.
-
Post-training Quantizationhttps://tensorflow.google.cn/lite/performance/post_training_quantization
-
TensorFlow Lite https://tensorflow.google.cn/lite/performance/quantization_spec
Models Trained with QAT Achieve Accuracy Comparable to Float
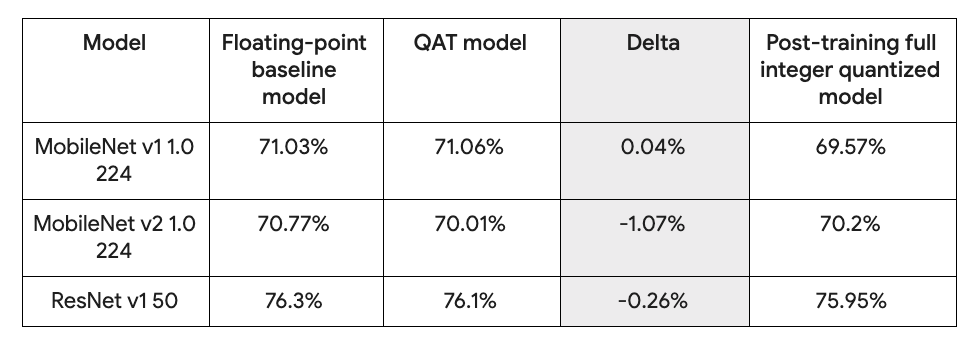
The table above shows the QAT accuracy achieved through the default configuration of TensorFlow Lite, compared with the floating-point benchmark and post-training quantization model.
Simulating Low-Precision Computation
The training computation graph itself runs in floating-point (e.g., float32), but low-precision fixed-point computation (e.g., int8 in the case of TensorFlow Lite) must be simulated. To do this, we insert special operations (tensorflow::ops::FakeQuantWithMinMaxVars) into the computation graph to convert floating-point tensors to low precision and then convert the low-precision values back to floating-point. This ensures that the loss caused by quantization is introduced into the computation and guarantees that subsequent computations simulate low-precision calculations. To achieve this purpose, we ensure that the loss caused by quantization is introduced into the tensors, and since each value in the floating-point tensor is now mapped 1:1 to a low-precision value, all subsequent computations using similar mapped tensors will not introduce more loss and will accurately simulate low-precision computation.
-
tensorflow::ops::FakeQuantWithMinMaxVarshttps://tensorflow.google.cn/api_docs/cc/class/tensorflow/ops/fake-quant-with-min-max-vars
Executing Quantization Simulation Operations
We need to perform quantization simulation operations in the training computation graph to conform to the computation method of the quantized computation graph. This means we need to strictly follow the quantization specifications provided by TensorFlow Lite to ensure that the API can execute within TensorFlow Lite.
-
Quantization Specificationshttps://tensorflow.google.cn/lite/performance/quantization_spec
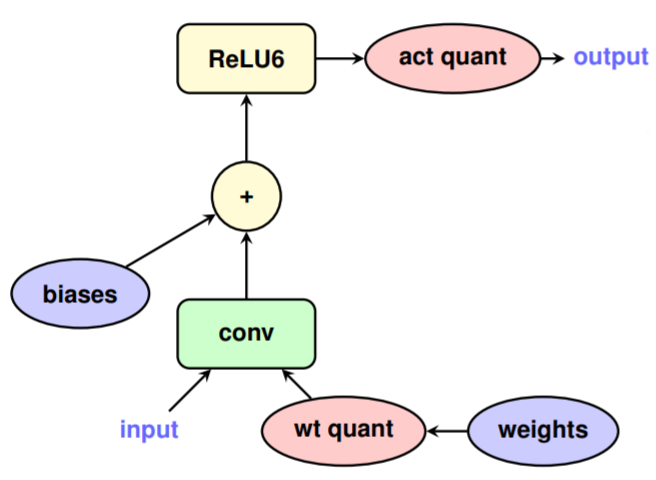
“wt quant” and “act quant” operators introduce loss during the forward pass of the model to simulate the actual quantization loss during inference. Note that there are no quantization operations between Conv and ReLU6. This is because ReLU has been integrated into TensorFlow Lite
The API built on Keras layers and model abstraction hides the above complex operations, allowing you to quantize the entire model with just a few lines of code.
Recording Computation Statistics
In addition to simulating lower precision computations, this API is also responsible for recording the statistics necessary for quantized training models. For example, you can train a model with this API and convert it into a TensorFlow Lite quantized model that only uses integers.
Use This API with Just a Few Lines of Code
The QAT API provides a simple and highly flexible way to quantize TensorFlow Keras models. With this, you can easily train the entire or part of a model using “Quantization Aware Training” and then export it for deployment via TensorFlow Lite.
Quantizing the Entire Keras Model
import tensorflow_model_optimization as tfmot
model = tf.keras.Sequential([
...
])
# Quantize the entire model.
quantized_model = tfmot.quantization.keras.quantize_model(model)
# Continue with training as usual.
quantized_model.compile(...)
quantized_model.fit(...)
Quantizing Part of the Keras Model
import tensorflow_model_optimization as tfmot
quantize_annotate_layer = tfmot.quantization.keras.quantize_annotate_layer
model = tf.keras.Sequential([
...
# Only annotated layers will be quantized.
quantize_annotate_layer(Conv2D()),
quantize_annotate_layer(ReLU()),
Dense(),
...
])
# Quantize the model.
quantized_model = tfmot.quantization.keras.quantize_apply(model)
By default, we configure the API to work with the quantization execution support provided by TensorFlow Lite. For detailed Colab with end-to-end training examples, please check here.
-
Herehttps://tensorflow.google.cn/model_optimization/guide/quantization/training_example
This API is highly flexible and can handle more complex use cases. For example, you can use this API to have precise control over quantization within layers, create custom quantization algorithms, and handle any custom layers you write.
For more in-depth information on how to use this API, please try this Colab. These sections in the Colab provide some examples showing how users can experiment with different quantization algorithms using this API. You can also watch the introduction from the recent TensorFlow Developer Summit.
-
This Colabhttps://tensorflow.google.cn/model_optimization/guide/quantization/training_comprehensive_guide
-
Sectionshttps://tensorflow.google.cn/model_optimization/guide/quantization/training_comprehensive_guide#experiment_with_quantization
We are excited to see that the QAT API further helps TensorFlow users achieve breakthroughs, enabling more efficient execution in products supported by TensorFlow Lite, while also providing opportunities for researching new quantization algorithms and further developing hardware platforms with different precision rates.
For more details, please watch the video below from the TensorFlow Developer Summit, which introduces and elaborates on the Model Optimization Toolkit and QAT.
Acknowledgments
Thanks to Pulkit Bhuwalka, Alan Chiao, Suharsh Sivakumar, Raziel Alvarez, Feng Liu, Lawrence Chan, Skirmantas Kligys, Yunlu Li, Khanh Le Viet, Billy Lambert, Mark Daoust, Tim Davis, Sarah Sirajuddin, and François Chollet.
For more information, please click “Read the Original” to visit the official website.
— Recommended Reading —