
Huggingface has added a visualization feature for GGUF files, allowing users to directly view the model’s metadata and tensor information from the model page. All these features are performed on the client side.
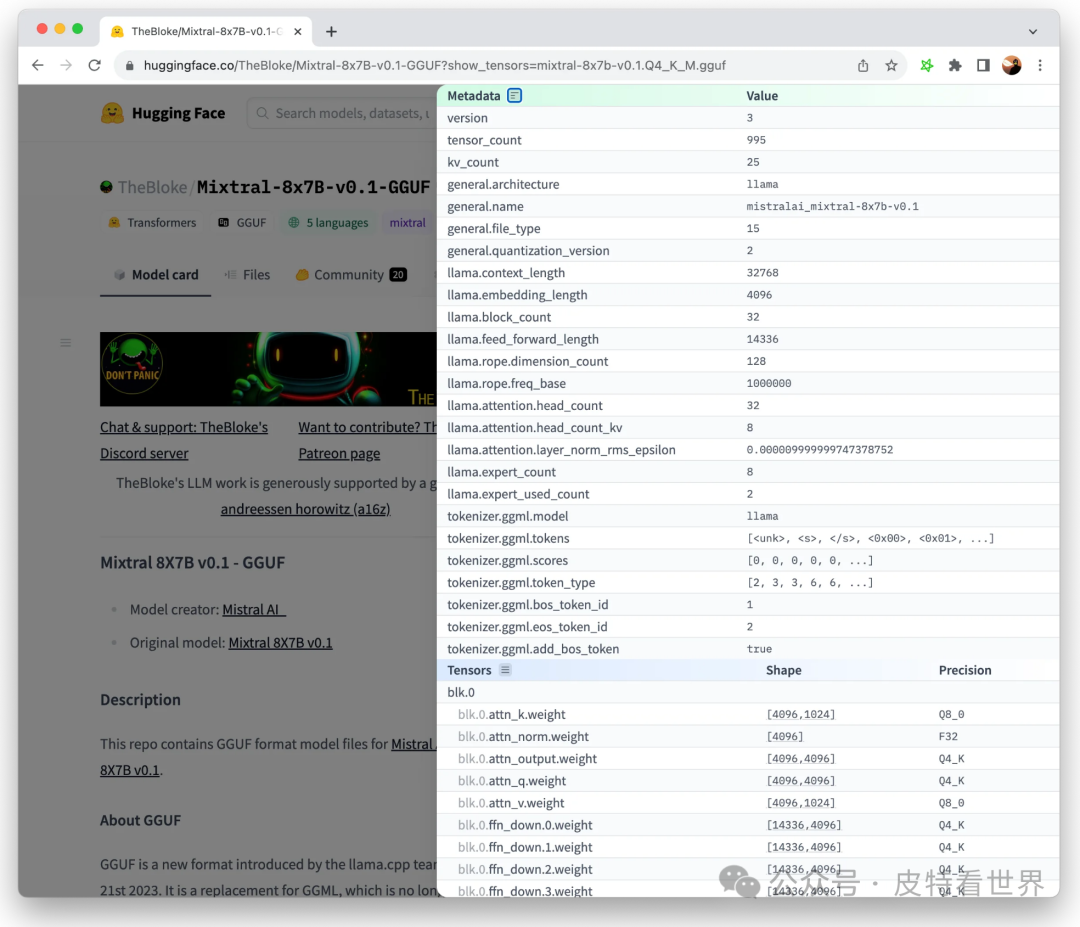
GGUF (GPT-Generated Unified Format) is a binary large model file format that allows for fast loading and saving of GGML models. It was developed by @ggerganov, the author of llama.cpp. The latest version is V3, evolved from GGML, GGMF, and GGJT. GGUF is extensible, allowing new metadata to be added to models without breaking compatibility.

GGUF supports model quantization, which can quantize model weights to lower bit integers, reducing model size and memory consumption while improving computational efficiency, balancing performance and accuracy. On HuggingFace, there are numerous applications of GGUF, where filenames starting with “Q” indicate the quantization bit count, followed by specific variants named according to different quantization schemes, affecting the model’s size, performance, and accuracy.
You can quickly find large GGUF models on Huggingface via the following link, which is sorted by model popularity by default, allowing you to find the most popular large models on the first page.
https://huggingface.co/models?library=gguf
After finding the appropriate model, click on the “Files and versions” tab to see all the quantized model files, each with a preview button that allows you to view all the information about the model.
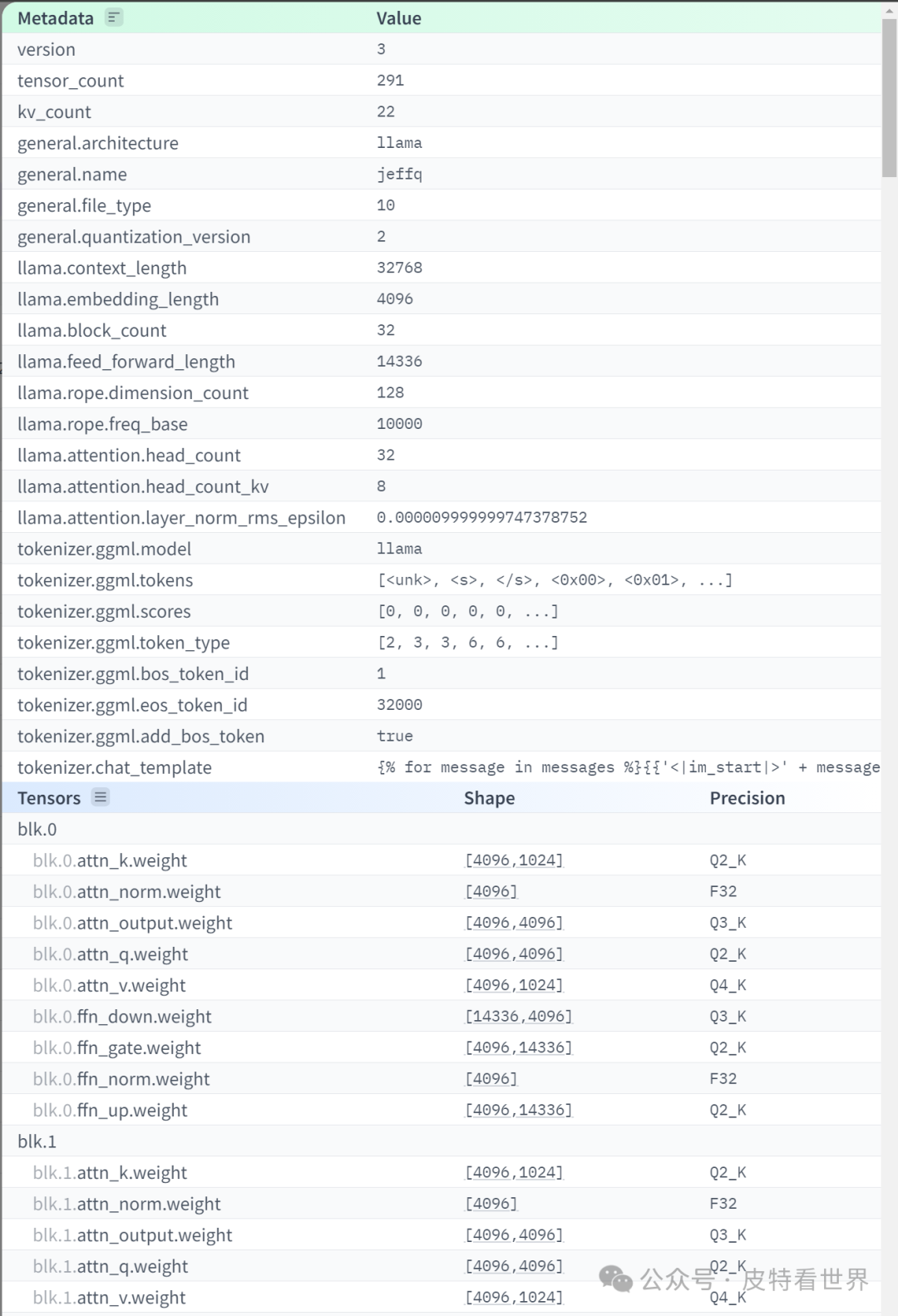
GGUF is currently the most widely used model storage format, supported by front-end tools like ollama, LMStudio, Text Generation WebUI, etc. In the future, GGUF may become the standard storage format for large models.