Overview of Transformer Compression
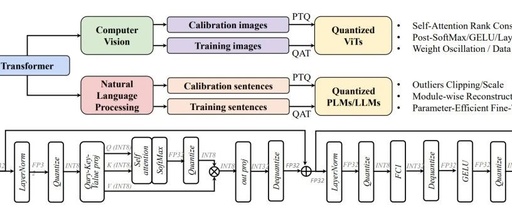
Large models based on the Transformer architecture are playing an increasingly important role in artificial intelligence, especially in the fields of natural language processing (NLP) and computer vision (CV). Model compression methods reduce their memory and computational costs, which is a necessary step for implementing Transformer models on practical devices. Given the unique architecture of … Read more