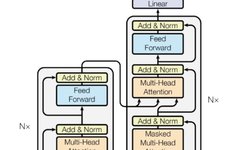
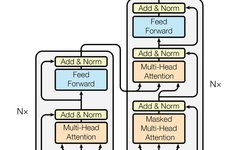
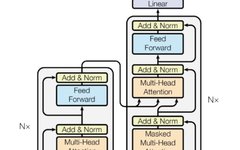
Multi-Head RAG: Multi-Head Attention Activation Layer for Document Retrieval
Source: DeepHub IMBA This article is about 2500 words long and suggests a reading time of 9 minutes. This paper proposes a new scheme that utilizes the multi-head attention layer of the decoder model instead of the traditional feed-forward layer activation. The existing RAG solutions may suffer because the embeddings of the most relevant documents … Read more