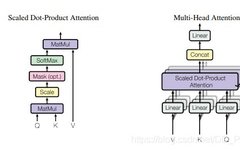
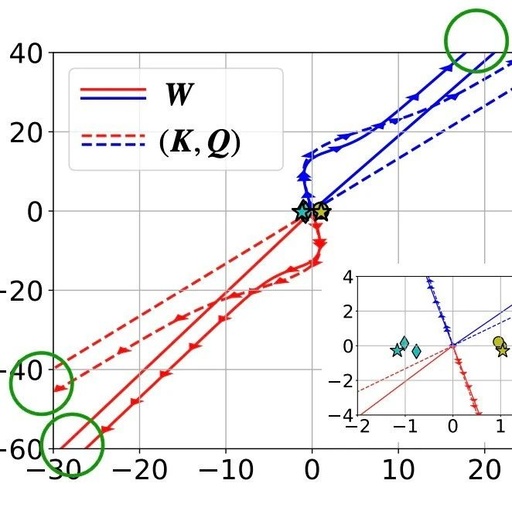
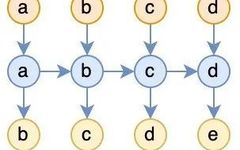
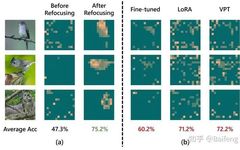
LSTM + Attention Breaks SOTA with 47.7% Accuracy Improvement
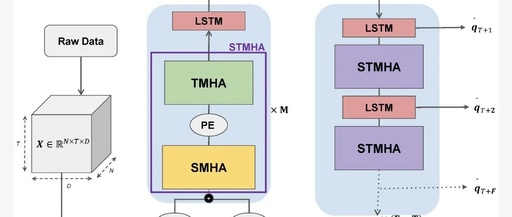
LSTM + Attention Mechanism is very useful for improving the prediction accuracy of models when processing long sequence data, making it a powerful tool! For example, the MALS-Net model combines these two elements, achieving a significant accuracy improvement of 47.7% in predictions. The main advantage lies in LSTM’s ability to learn long-term dependencies, making it … Read more