Follow the WeChat public account “ML_NLP“

Author: Jiang Runyu, Harbin Institute of Technology SCIR
Introduction
In recent years, the most impressive achievement in the field of NLP is undoubtedly the pre-trained models represented by Google’s BERT. They continuously break records (both in task metrics and computational requirements), surpassing the average human level on many tasks, and exhibit very good transferability and a certain degree of interpretability.
For instance, when we need to explain in a paper why an algorithm or modification works, a heatmap based on attention clearly demonstrates what our code has achieved.
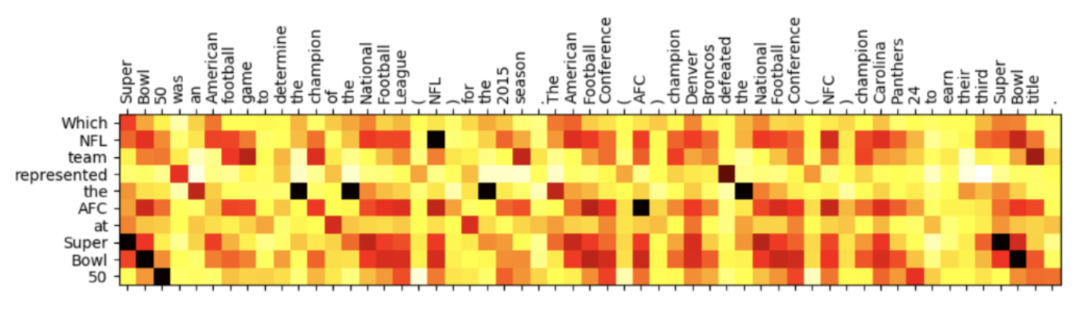 Figure 1: A common attention heatmap in papers
Figure 1: A common attention heatmap in papersCurrently, mainstream pre-trained models are modified based on the Transformer model proposed by Google in 2017, which serves as their feature extractor. It can be said that the Transformer has completely changed the field of deep learning, especially in NLP, since its inception.
This article mainly introduces the Transformer and some of its optimized variants in recent years.
Transformer
To introduce the Transformer in one sentence: “The first model to completely abandon RNN recurrence and CNN convolution, relying solely on attention for feature extraction.” This is exactly what the title of the paper states: “Attention Is All You Need”.
The application of the attention mechanism in NLP can be traced back to 2014 when the Bengio team introduced attention into the NMT (Neural Machine Translation) task. However, at that time, attention was merely an auxiliary structure, while the core architecture of the model was still RNN. By the time of the Transformer, attention mechanisms were fully integrated as the model’s foundational structure, discarding the previous CNN and RNN networks.
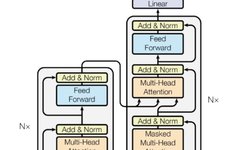
The basic structure of the Transformer is shown in the diagram below, where the left half is the Encoder part and the right half is the Decoder part. The Transformer consists of 6 layers of this structure.
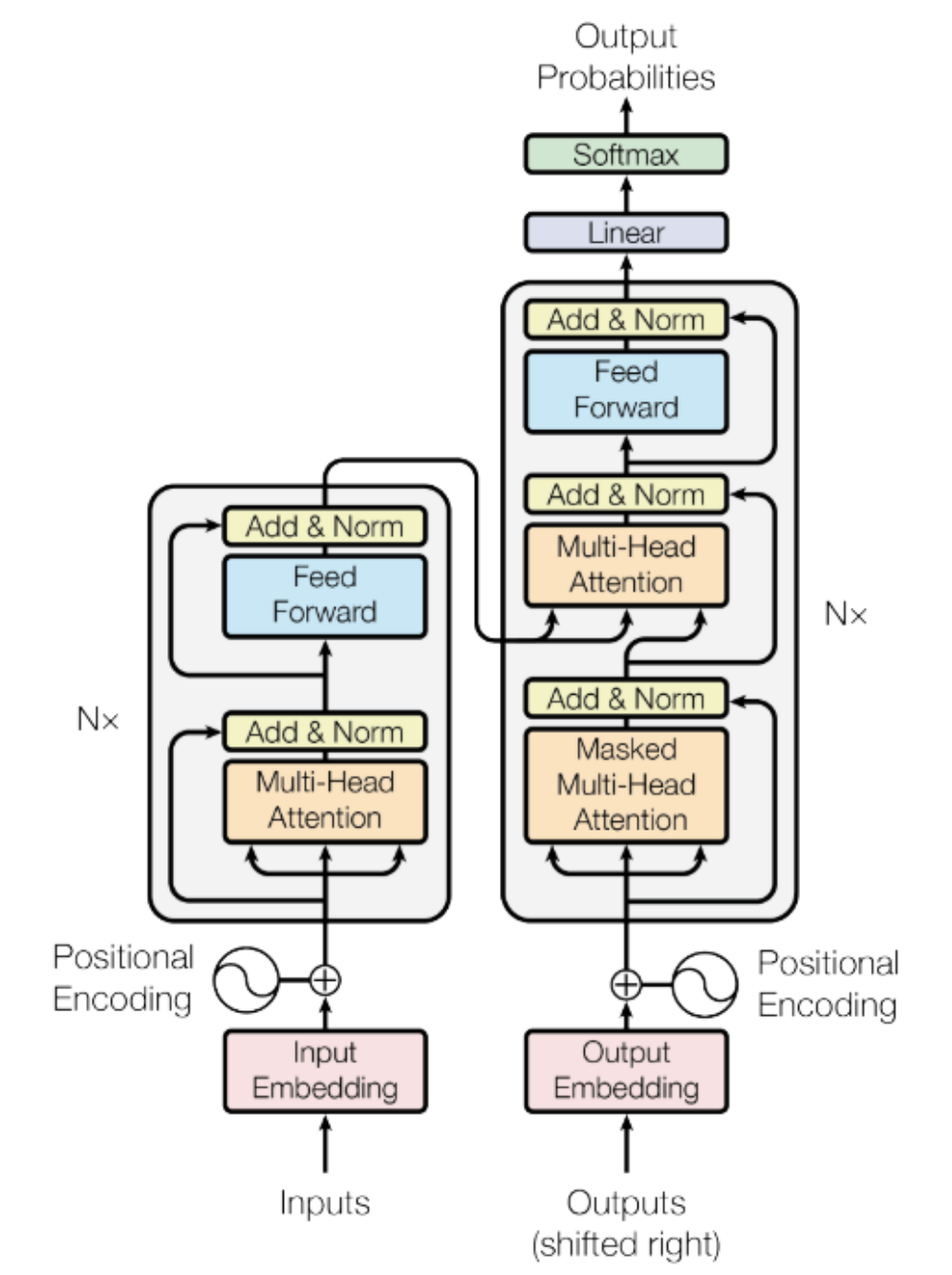 Figure 2: Detailed structure of the Transformer
Figure 2: Detailed structure of the Transformer
Taking the translation model as an example, here is the overall structure of the Transformer:
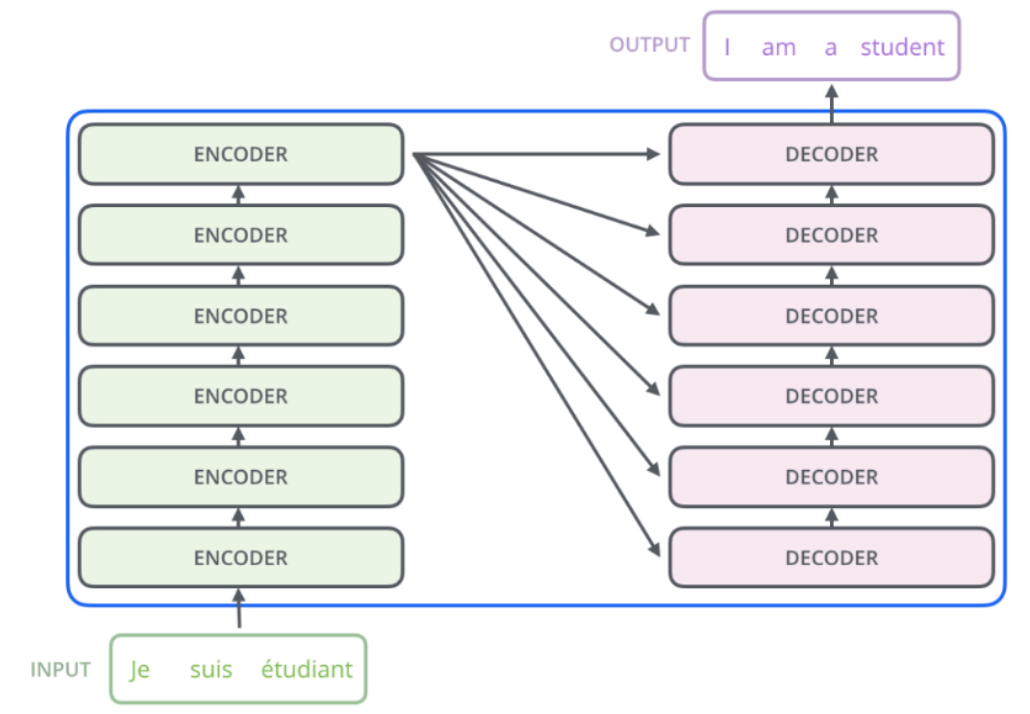 Figure 3: Overall structure of the Transformer
Figure 3: Overall structure of the Transformer
Above is a general introduction to the Transformer; below we will explain its various innovations.
Attention
The Transformer uses attention three times in total. The Decoder part has a special layer called Masked Attention. During decoding, the model should only know the preceding context of the current center word, so the content of the following words is masked to maintain the autoregressive property.
Scaled Dot-Product Attention
Self-Attention essentially enhances the representation of the current word by introducing contextual information, embedding more information into it. This is similar to when the Bengio team introduced attention into NMT in 2014.
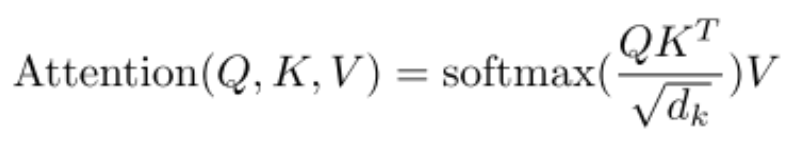 In the Transformer, this part is implemented through Attention(Q, K, V). Here, Q is the query, K is the key, and V is the value. The dot product of Q and K reflects the influence of contextual words on the center word, which is then normalized through softmax.
In the Transformer, this part is implemented through Attention(Q, K, V). Here, Q is the query, K is the key, and V is the value. The dot product of Q and K reflects the influence of contextual words on the center word, which is then normalized through softmax.
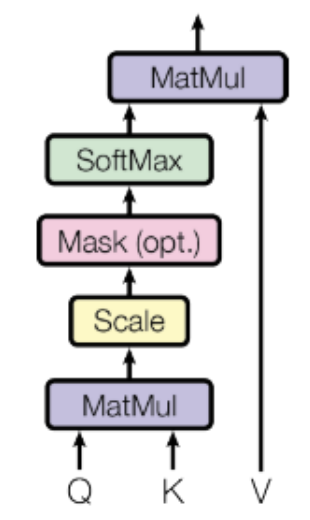 Figure 4: Attention computation path
Figure 4: Attention computation pathMulti-Head Attention
Multi-Head Attention is essentially a complete innovation.
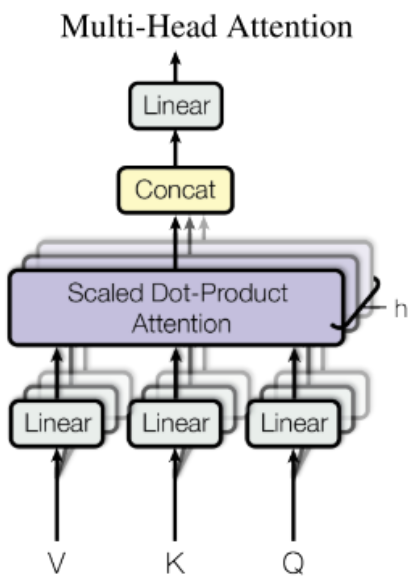
Figure 5: Multi-Head Attention computation path
It projects the original 512-dimensional Q, K, V through 8 different linear projections, resulting in 8 groups of low-dimensional Qi, Ki, Vi, each with a dimension of 64. The formula is as follows:

This approach reduces the size of each attention head, so the computational load does not significantly increase.
Regarding why to use multi-head attention instead of single-head attention, the authors of “Attention Is All You Need” argue that averaging attention weights reduces effective resolution, meaning it cannot fully capture information from different representation subspaces. Using multi-head attention is somewhat analogous to using multiple convolution kernels within the same convolutional layer in CNNs. It enhances the model’s ability to capture different characteristics of text across different subspaces, avoiding the suppression of such characteristics by average pooling.
However, there is currently no good explanation for whether multi-head attention is useful and why it is useful.
A significant amount of research shows that specific layers of BERT, which is based on the Transformer, have their unique functions, with lower layers focusing more on syntax and higher layers more on semantics. Since the attention focus is the same within the same layer of the Transformer, the different heads in that layer should also have the same focus. This contradicts the authors’ explanation.
In fact, in the paper “A Multiscale Visualization of Attention in the Transformer Model”, the authors analyzed some attention heads in the first few layers of BERT, as shown in the figure below, revealing that within the same layer, there are always one or two heads that focus on different points compared to the others, while the remaining heads tend to converge [considering that the attention heads in the same layer are independently trained, this is quite fascinating].
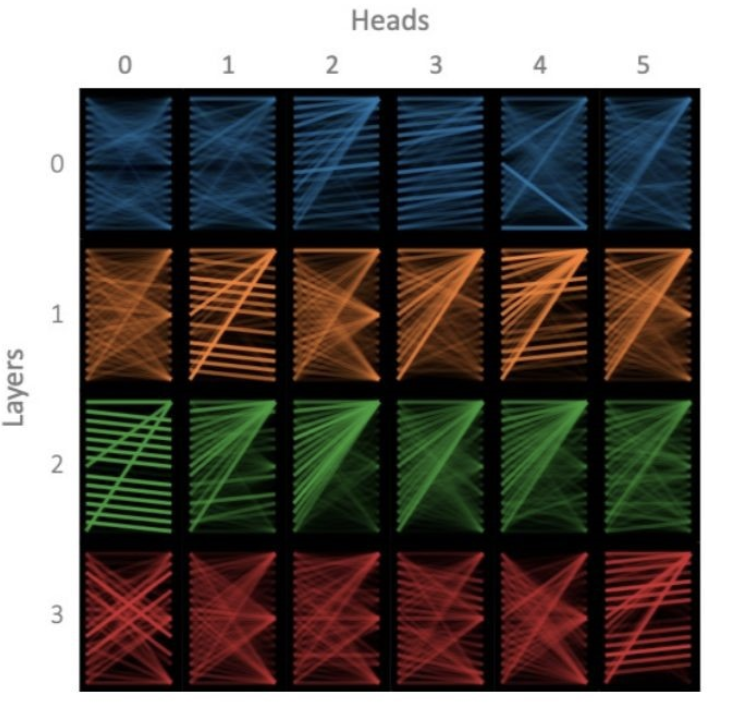
Figure 6: The focus of heads 0-5 in the 0-3 layers of BERT on the same input.
In the paper “What Does BERT Look At? An Analysis of BERT’s Attention”, the authors analyzed the differences between different heads within the same layer and whether this difference varies with layer depth. The results are shown in the figure below, suggesting that the differences between heads decrease as the layer number increases, meaning that the higher the layer, the more similar the heads become. Unfortunately, the reasons for this phenomenon are not well explained.
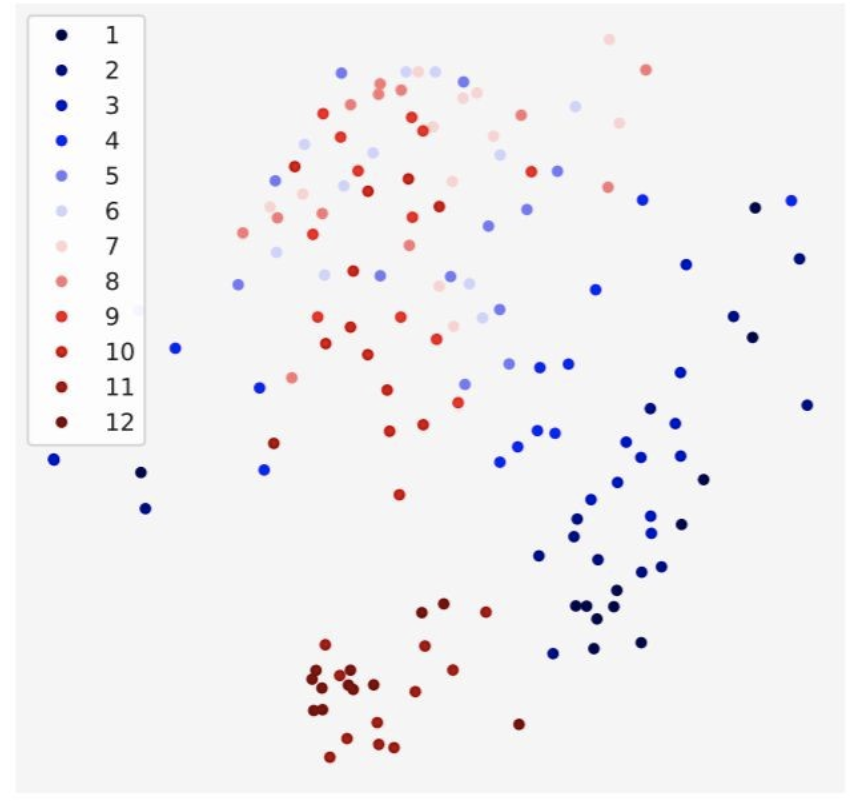
Figure 7: The differences between heads in each layer of BERT projected onto a two-dimensional plane
In my personal view, the role of the multi-head attention mechanism may be as follows: the redundancy of the attention mechanism is very high (even independent attention heads are likely to focus on the same points), so those relatively outlier attention heads can further optimize the model. However, the occurrence of these outlier heads is not very frequent, so it is necessary to increase the number of heads to ensure that these outlier heads appear more often.
Positional Encoding
Since the attention mechanism does not inform the model about the positional relationships between words (which is different from RNNs and CNNs), additional positional information encoding is required.
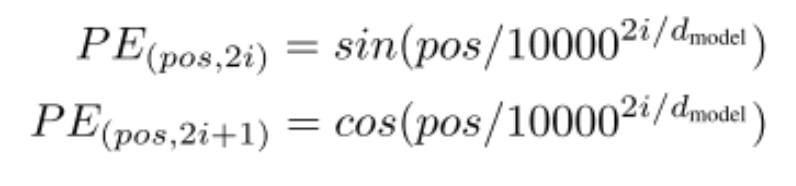
The author also mentioned that learned embeddings could be used, but experiments show that there is no difference in performance between the two methods; however, the formulaic method is simpler and can handle sequences longer than those during training.
Disadvantages
From the current perspective, the Transformer also has some shortcomings:
Non-Turing complete: the proof is omitted. In simple terms, the Transformer cannot handle all problems. For example, when we need to output a direct copy of the input, the Transformer does not learn this operation well.
Not suitable for handling ultra-long sequences: When processing articles, the length of the sequence can easily exceed 512. If we keep increasing the model’s dimensions, the computational resource requirements during training will grow exponentially, making it difficult to bear. Therefore, it is generally chosen to truncate the text directly, without considering the natural segmentation of the text (such as punctuation), resulting in a decline in the quality of long-distance dependency modeling.
The computational resource allocation is the same for all words: during the Encoder process, all input tokens have the same computational load. However, in a sentence, some words are relatively more important, while others are not very meaningful. Assigning the same computational resources to these words is clearly a waste.
Although the original version of the Transformer is not mature, its fixed layer count lacks flexibility, and its excessive computational resource demands limit its practical application prospects. However, its excellent feature extraction capability has attracted the attention of many scholars. Many have proposed different variants of the Transformer to improve or circumvent its shortcomings. Among them, Universal Transformer, Transformer-XL, and Reformer are typical representatives.
Universal Transformer
From a structural perspective, the Universal Transformer does not differ much from the Transformer, so I will not elaborate on it here; I will mainly discuss its biggest innovation.
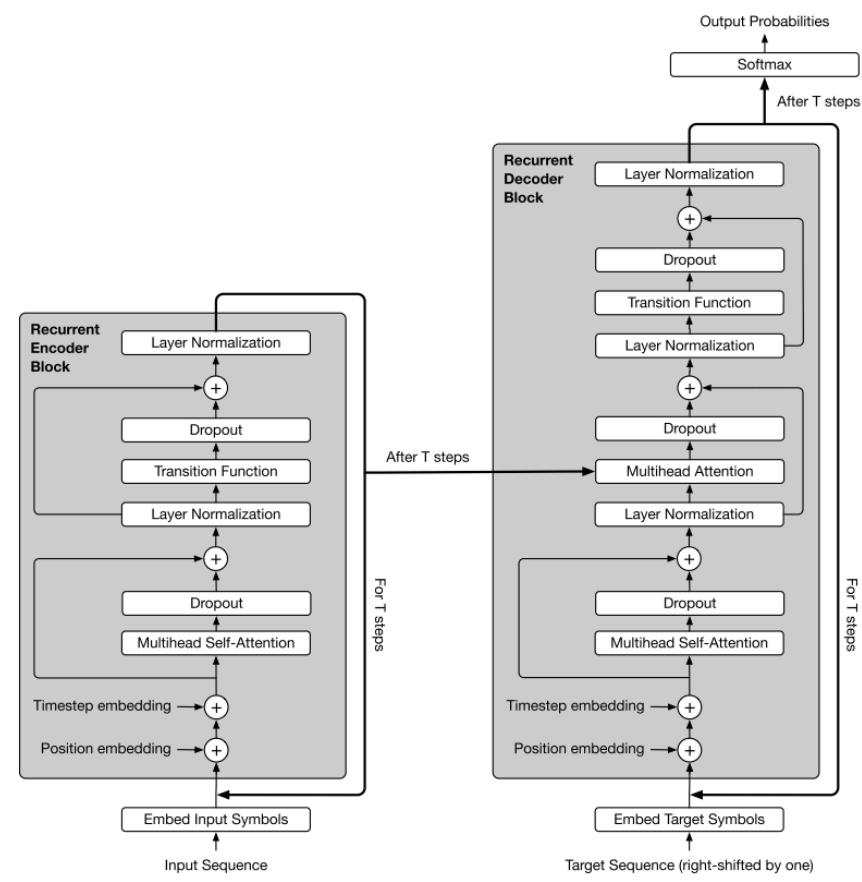 Figure 8: Universal Transformer model architecture
Figure 8: Universal Transformer model architecture
In the Transformer, the input undergoes attention and then enters a fully connected layer for computation, while the Universal Transformer model enters a transition function with shared weights for iterative computation.
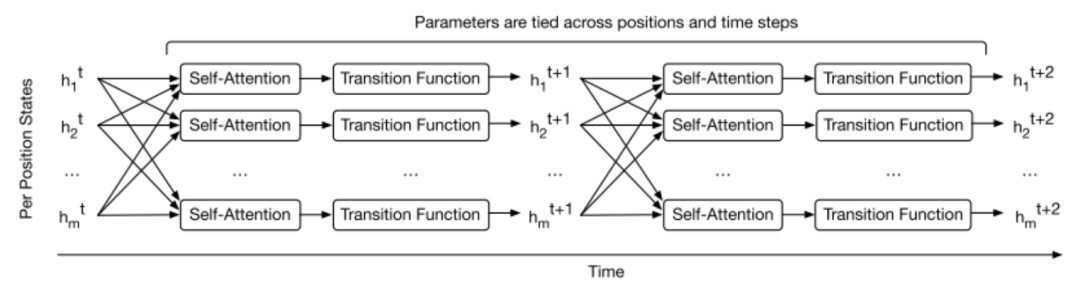
Figure 9: The Universal Transformer reintroduces the recurrent mechanism
Here, the vertical view represents the sequence order of the text, while the horizontal view represents the time steps. The computation formula for each step is as follows:
The transition function can be a fully connected layer like before, or it can be another function layer.
Previously, the position encoding of the Transformer did not require encoding the layer number because it was fixed. The Universal Transformer model, with an added time dimension, requires a round of coordinate encoding for each iteration, with the formula:
ACT can adjust the number of computation steps. The Universal Transformer with the ACT mechanism is referred to as the Adaptive Universal Transformer. The figure below illustrates that after introducing the ACT mechanism, the model performs more iterations on more important tokens in the text, while reducing computational resources for relatively unimportant words.
Figure 10: The Universal Transformer allocates more resources to important tokens
The Universal Transformer improves upon the Transformer by addressing its non-Turing completeness and the issue of equal resource allocation.
Transformer-XL
Theoretically, the attention mechanism allows the Transformer model to capture dependencies between tokens at any distance, but due to computational limitations (the next model introduced addresses this issue), the Transformer usually segments the text into segments of length less than or equal to (default is 512), with each segment being independent and not interfering with each other.
This means that the dependencies between segments, or the dependencies between tokens that exceed a distance of 512, cannot be modeled at all. Additionally, this leads to a context fragmentation problem, as the segmentation is not based on semantic boundaries but on length, potentially splitting a complete sentence into two. When predicting such split sentences, it may lack essential semantic information.
The Transformer-XL proposes Segment-level Recurrence to address this issue.
In one sentence, Segment-level Recurrence means that when processing the current segment, all hidden vectors from the previous segment are cached and utilized, and all hidden vectors from the previous segment participate only in forward computation without backpropagation.
Figure 11: In Transformer-XL, nodes can “see” the content of previous segments
Let’s delve into the computation process: assume each segment has a length of L and the entire model contains N layers of Transformer-XL, then each group of segments contains N groups of hidden variable arrays of length L. The hidden variable vector of the nth layer of the tth segment can be represented as, where d is the length of the hidden variable vector, and the hidden variable vector of the nth layer of the t+1th segment can be calculated using the following formula, where SG stands for stop-gradient, meaning no backpropagation of the hidden variables from the previous segment.
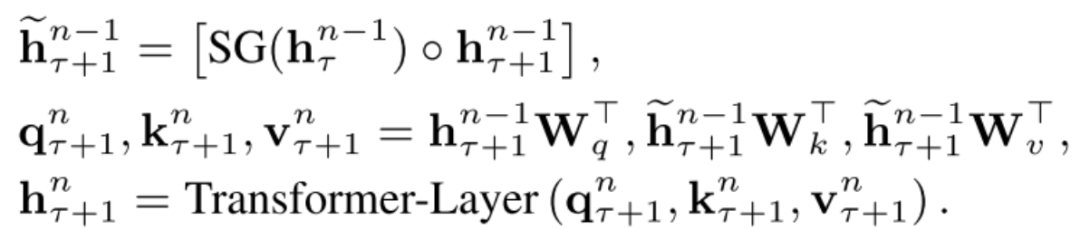
From the diagram, we can see that in the current segment, the computation of each hidden vector at the nth layer relies on the hidden vectors from the previous layer, including the current position and the previous L tokens. This means that each position’s hidden vector, apart from its own position, has dependencies on the tokens of the previous layer for the previous (L-1) positions, and as we move down each layer, the length of these dependencies increases (L-1). Therefore, the longest dependency length is N(L-1), where N is the number of layers in the model. When computing long texts, we can cache the results of the previous segment’s hidden vectors to avoid redundant calculations, significantly improving computational efficiency.
Since the previous position encoding is insufficient to distinguish tokens at the same position between different segments, the author proposes using Relative Positional Encoding to replace the previous position encoding. Specifically, relative position encoding is used instead of absolute position encoding. This approach is easy to understand conceptually because, when processing sequences, the absolute position of a token is not important; what we need is only the relative position of two tokens when calculating attention. Since this part mainly serves as a patch, we will not elaborate further.
In summary, Transformer-XL addresses the issue of long-distance dependencies to some extent without significantly increasing computational resource demands.
Reformer
The reason why the Transformer is set to 512 instead of a larger value is that during the computation of attention, it needs to calculate (Multi-head attention does not reduce the computation), which is one of the reasons why the Transformer does not perform well in handling long-distance dependencies. On the other hand, the memory consumption of multi-layer Transformers (from a few layers requiring GBs to models with thousands of layers requiring TBs) also limits the application of Transformers.
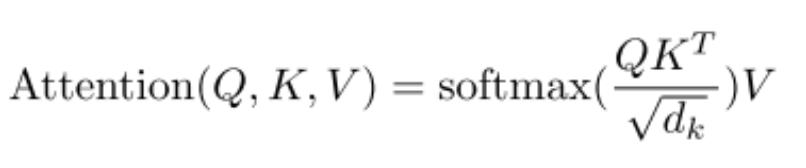
In the original Transformer, the computation of attention requires calculating, with a complexity of, where L is the sequence length. So why is this calculation necessary? It is to find the similarities between Q and K. By applying the idea of Locality-Sensitive Hashing (similar to bucket sorting), we can group similar vectors together and only compute the dot products between vectors within the same class. Thus, through LSH, we reduce the computational complexity to.
The diagram below illustrates the process of LSH attention, where LSH is first used to bucket each segment, grouping the similar parts into the same bucket. We then parallelize the computation of the dot products within each bucket.
The authors also considered that there is a certain probability that similar vectors will be placed in different buckets, so multiple rounds of hashing are used to reduce this probability.
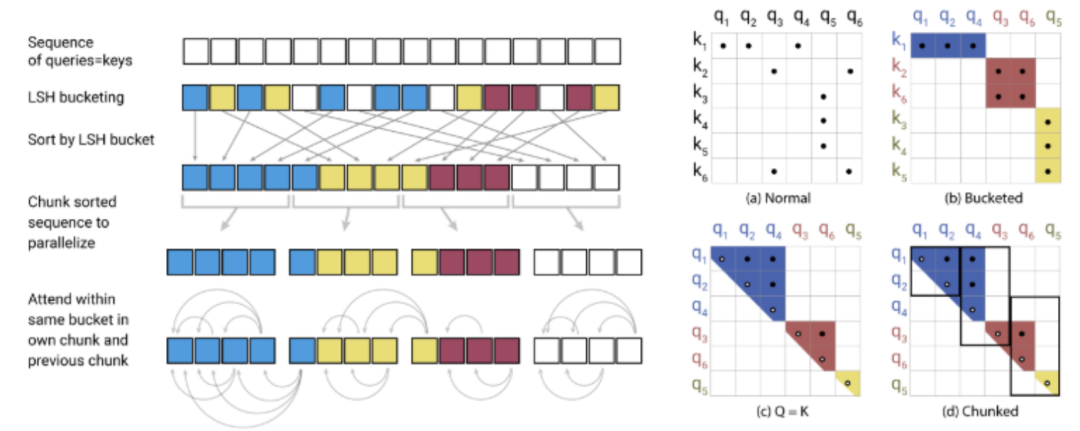 Figure 12: The Reformer model preemptively uses hashing to filter, similar to bucket sorting, avoiding the computation of QK
Figure 12: The Reformer model preemptively uses hashing to filter, similar to bucket sorting, avoiding the computation of QK
LSH addresses the speed issue, but there remains the problem of memory consumption. A single-layer network typically requires GBs of memory, but training a multi-layer model necessitates saving the activation values and hidden variables of each layer for use during backpropagation. This greatly increases memory usage.
Here, the authors borrowed the idea from RevNet, no longer retaining the inputs of the intermediate residual connections but instead applying a “reversible layer” approach, as illustrated in the diagram below, (a) for forward propagation and (b) for backpropagation.
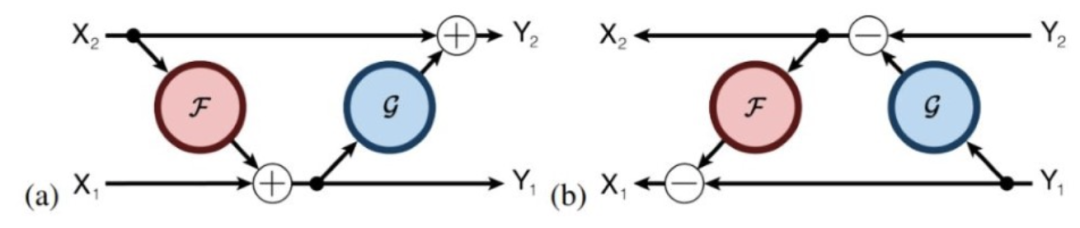
Figure 13: In Reformer, the inputs of each layer can be computed from their outputs during backpropagation
The reversible layer has two sets of activations for each layer. One follows the standard process and updates step by step to the next layer, while the other only captures changes to the first layer. Therefore, to run the network backward, we only need to subtract the activations applied to each layer.
This means that there is no need to cache any activations for backpropagation. Similar to using gradient checkpoints, although some redundant computations are still necessary, since each layer’s input can easily be constructed from its output, memory usage no longer increases with the number of layers in the network.
In summary, the Reformer reduces both the computational load of attention and the memory usage of the model, laying the foundation for the practical implementation of large pre-trained models in the future.
Conclusion
This article mainly introduces the Transformer model and some variants that improve upon its shortcomings, summarizing their design ideas and advantages and disadvantages. In the future, pre-trained models based on Transformers and their improved versions will undoubtedly achieve greater breakthroughs in the field of natural language processing.
References
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Dehghani M, Gouws S, Vinyals O, et al. Universal transformers[J]. arXiv preprint arXiv:1807.03819, 2018.
[3] Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
[4] Kitaev N, Kaiser Ł, Levskaya A. Reformer: The Efficient Transformer[J]. arXiv preprint arXiv:2001.04451, 2020.
[5] Vig J. A multiscale visualization of attention in the transformer model[J]. arXiv preprint arXiv:1906.05714, 2019.
[6] Clark K, Khandelwal U, Levy O, et al. What does bert look at? an analysis of bert’s attention[J]. arXiv preprint arXiv:1906.04341, 2019.
Warehouse address sharing:
Reply "code" in the backend of the machine learning algorithms and natural language processing public account to obtain 195 papers from NAACL + 295 papers from ACL 2019 with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Big news! The machine learning algorithms and natural language processing group chat has officially been established! There are abundant resources in the group, and everyone is welcome to join and learn!
Extra bonus resources! Deep learning and neural networks by Qiu Xipeng, official Chinese tutorial for PyTorch, data analysis using Python, machine learning study notes, official documentation in Chinese for pandas, effective java (Chinese version), and 20 other bonus resources.
How to obtain: After entering the group, click on the group announcement to receive the download link. Please modify your remarks when adding, such as [School/Company + Name + Direction]. For example - HIT + Zhang San + Dialogue System. Please avoid adding if you are a micro-business owner. Thank you!
Recommended reading:
Summary and thoughts on common normalization methods: BN, LN, IN, GN
LSTM that everyone can understand
Comprehensive analysis of Python "partial function" usage