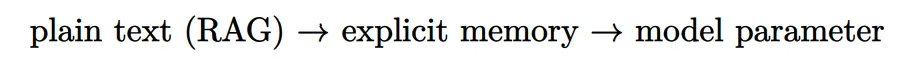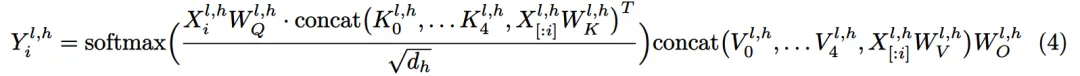Reported by Machine Heart
Editor: Chen Chen
A 2.4B Memory3 outperforms larger LLM and RAG models.

According to a message from the WeChat public account of Machine Heart: In recent years, large language models (LLMs) have gained unprecedented attention due to their extraordinary performance. However, the training and inference costs of LLMs are high, and various optimization methods have been attempted to reduce these costs.
Professor E Wei Nan is a University of Science and Technology of China 781 alumnus. This article is based on research from institutions such as Shanghai Algorithm Innovation Research Institute and Peking University, inspired by the hierarchical structure of human brain memory. They aim to reduce costs by equipping LLMs with explicit memory (a cheaper memory format than model parameters and RAG). Conceptually, since most of its knowledge is externalized into explicit memory, LLMs can enjoy reduced parameter size, training costs, and inference costs.
-
Paper link: https://arxiv.org/pdf/2407.01178
-
Paper title:Memory3: Language Modeling with Explicit Memory
As a preliminary proof of concept, the researchers trained a 2.4B LLM from scratch, which achieved better performance than larger LLM and RAG models, and realized a higher decoding speed than RAG. This model is named Memory3 because explicit memory in LLMs is the third form of memory following implicit memory (model parameters) and working memory (context key-value).
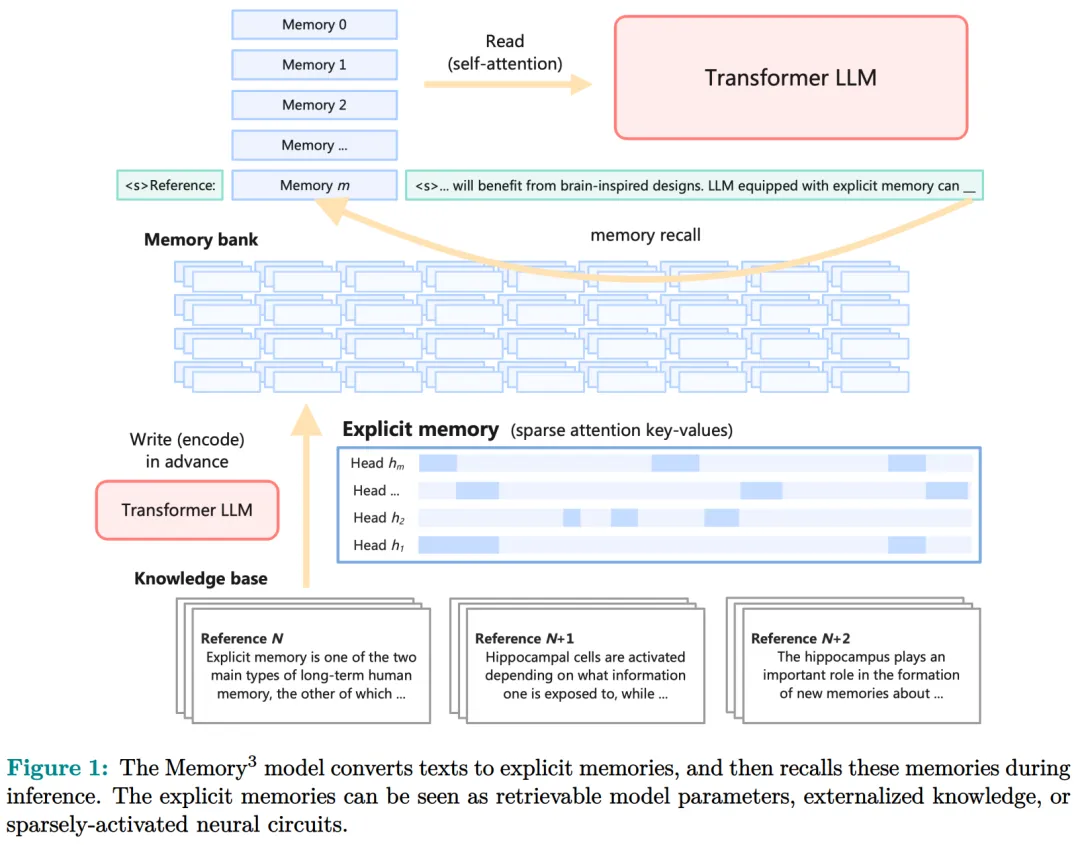
Specifically, this paper introduces a new memory format, namely explicit memory, characterized by relatively low write and read costs. As shown in Figure 1, the model first converts the knowledge base (or any text dataset) into explicit memory, implemented as sparse attention key-value, and then calls these memories during inference and integrates them into the self-attention layer.
The new memory format defines a new memory hierarchy:
Additionally, this paper also introduces a memory circuit theory that supports knowledge externalization and proposes a memory sparsity mechanism that facilitates easy handling of storage and a two-stage pre-training scheme that promotes memory formation.
-
Memory3 utilizes explicit memory during inference, alleviating the burden of model parameters remembering specific knowledge;
-
Explicit memory is encoded from the constructed knowledge base, where the sparse memory format maintains the true storage size;
-
The researchers trained a Memory3 model with 2.4B non-embedding parameters from scratch, which outperformed larger SOTA models. It also exhibited better performance and faster inference speed than RAG;
-
Moreover, Memory3 improves factuality and reduces hallucinations, and is able to adapt quickly to specialized tasks.
The memory circuit theory helps determine which knowledge can be stored as explicit memory and which model architecture is suitable for reading and writing explicit memory.
The researchers treat the input-output relationship as the internal mechanism of the circuit and define knowledge as the input-output relationship and its circuit. By manipulating these circuits, many knowledge pieces can be separated from LLM while keeping its functionality intact.
Memory3: In terms of architecture, the goal of this paper is to design an explicit memory mechanism for Transformer LLMs with relatively low write and read costs. Additionally, this paper aims to limit modifications to the Transformer architecture as much as possible, without adding any new trainable parameters, so that most existing Transformer LLMs can be converted to Memory3 models with minimal fine-tuning. The simple design process is as follows:
Write cost: Before inference, the LLM writes each reference to explicit memory, stored on the drive. The memory is selected from the key-value vectors of the self-attention layer, so the writing process does not involve training. Each reference is processed independently, avoiding the costs of long-context attention.
Read cost: During inference, explicit memory is retrieved from the drive and read by self-attention along with the usual context key-value. Each memory consists of a minimal number of key-values from a few attention heads, significantly reducing additional computation, GPU storage, drive storage, and loading time. This allows LLMs to frequently retrieve many references with limited impact on decoding speed.
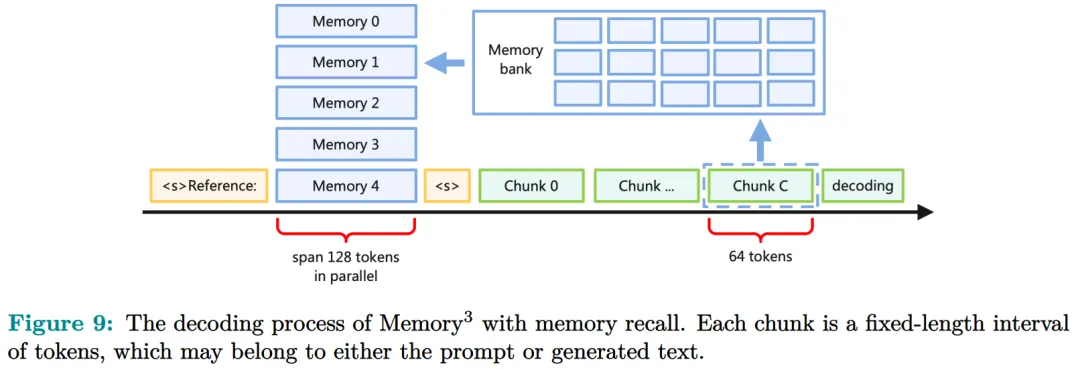
The inference process is illustrated in Figure 9. Whenever the LLM generates 64 tokens, it discards the current memory, using these 64 tokens as query text to retrieve 5 new memories, and continues decoding with these memories. Similarly, when processing prompts, the LLM retrieves 5 memories for every block of 64 tokens. Each block focuses on its own memory, and the memories between different blocks may vary.
Writing and reading memory: During inference, the LLM can directly read the retrieved explicit memories through its self-attention layer by concatenating them with the context key-values (Figure 9). Specifically, for each attention head h at the l-th layer, if it is selected as a memory head, then its output Y^( l,h ) will change:
Additionally, the study employs parallel positional encoding for all explicit memories, meaning all key positions are within the same interval of length 128, as shown in Figure 9.
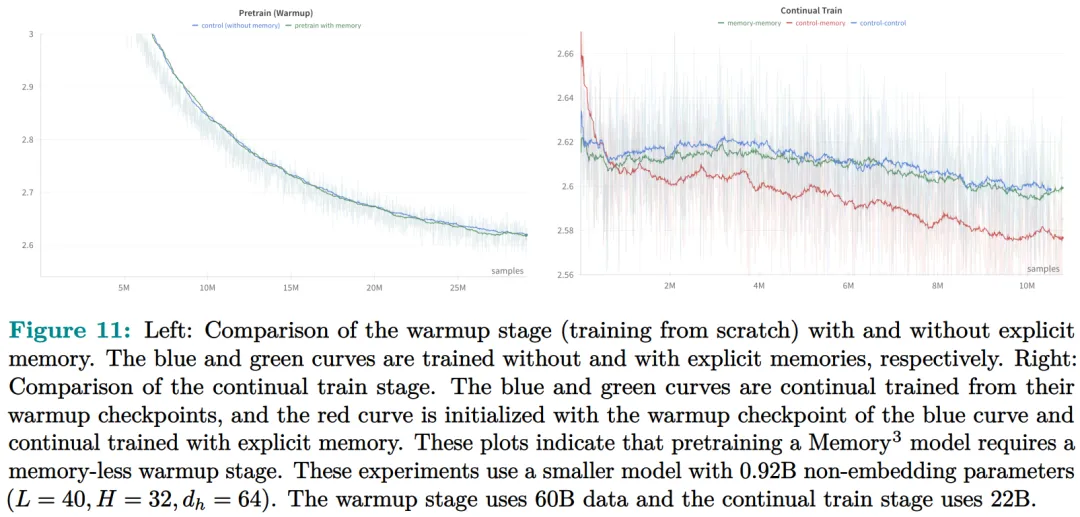
Two-stage pre-training: The pre-training consists of two stages, warm-up and continued training. Only the continued training stage involves explicit memory, while the warm-up stage uses the same format as regular pre-training.
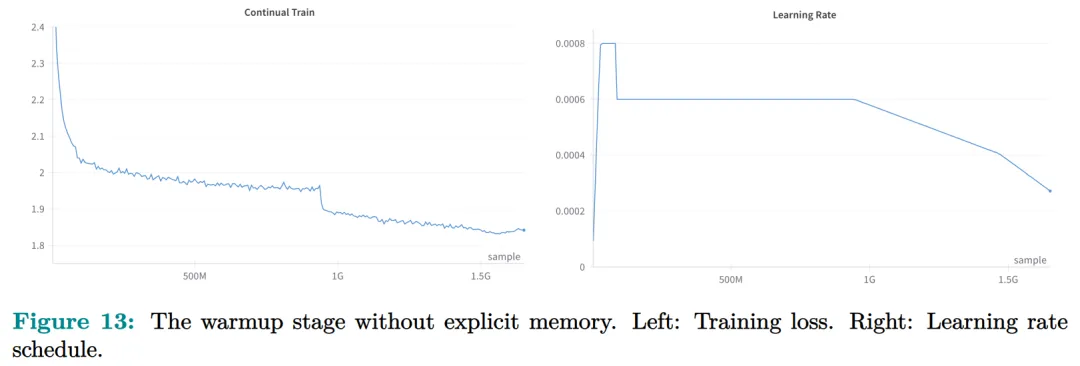
Figure 13 plots the training loss and learning rate schedule for the warm-up stage.
Figure 14 plots the training loss and learning rate schedule for the continued training stage.
The researchers evaluated the general capabilities of the Memory3 model (benchmark tasks), dialogue capabilities, specialized capabilities (legal and medical), and hallucinations. Additionally, they measured the decoding speed of Memory3 and compared it with similar and larger SOTA LLMs and RAG models.
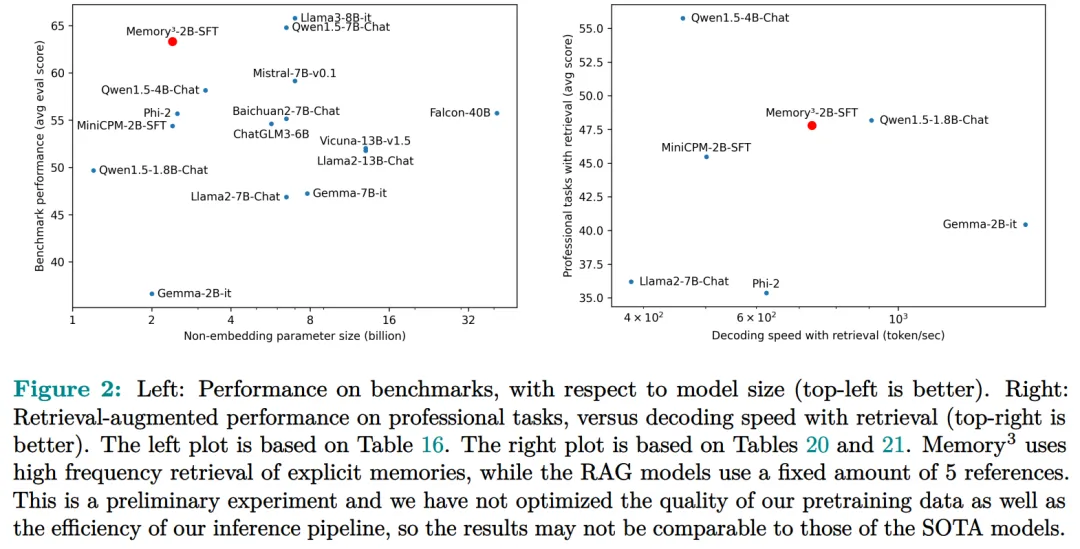
The evaluation results for general capabilities are as follows, indicating that explicit memory improved the average score by 2.51%. In contrast, the score gap between Llama2-7B and 13B is 4.91%. Explicit memory can increase the “effective model size” by 2.51/4.91 ≈ 51.1%.
Next, the authors evaluated the dialogue skills of Memory3, with results listed in Table 18, indicating that the model outperformed Vicuna-7B, Falcon-40B-Instruct, and ChatGLM2-6B with fewer parameters.
Currently, LLMs still face hallucination issues. Conceptually, Memory3 should be less susceptible to hallucinations as its explicit memory directly corresponds to reference texts. To assess hallucinations, the researchers selected two English datasets for evaluation. The results are shown in Table 19, where Memory3 achieved the highest scores on most tasks.
One of the advantages of using explicit memory is that LLMs can easily adapt to new fields and tasks by updating their knowledge base. Just import task-related references into the knowledge base of Memory3, and optionally convert them into explicit memory in a hot-start scenario. The model can then utilize this new knowledge for inference, skipping the more costly and potentially damaging fine-tuning process, and operates faster than RAG. Figure 4 demonstrates this cost reduction, facilitating the rapid deployment of LLMs across various industries.
The following table indicates that Memory3 outperforms most models.
Finally, the researchers evaluated the decoding speed or throughput of Memory3 by the number of tokens generated per second.
For more content, please refer to the original paper.
© THE END
For reprint authorization, please contact this public account
Submissions or inquiries: [email protected]