
Source: DeepHub IMBA
This article is about 2500 words long and suggests a reading time of 9 minutes.
This paper proposes a new scheme that utilizes the multi-head attention layer of the decoder model instead of the traditional feed-forward layer activation.
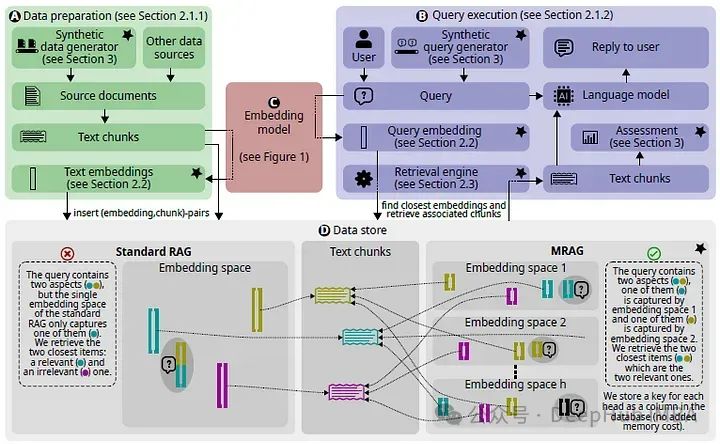
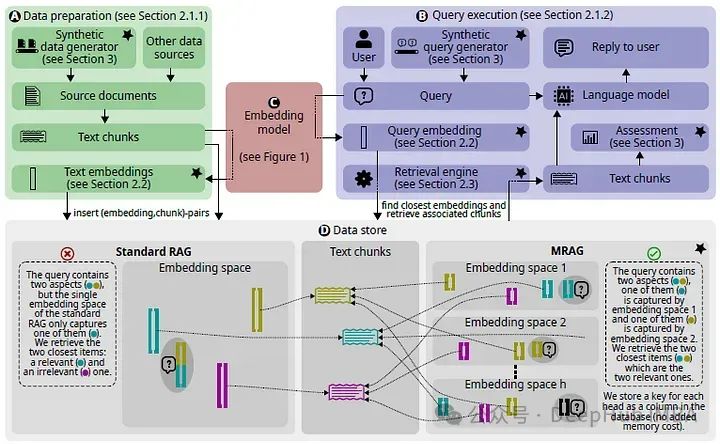
The existing RAG solutions may suffer because the embeddings of the most relevant documents can be far apart in the embedding space, which complicates and renders the retrieval process ineffective. To address this issue, the paper introduces Multi-Head RAG (MRAG), a new scheme that utilizes the activation of the multi-head attention layer of the Transformer instead of the decoder layer to acquire multi-faceted documents.
MRAG
Instead of using a single activation vector generated by the last feed-forward decoder layer for the last token, it utilizes H individual activation vectors generated by the last attention layer for the last token, which are then processed through matrix Wo (a linear layer that combines the results of all attention heads).
It can be formalized as a set of embeddings S = {ek∀k}, where ek = headk(xn), which is the collection of outputs from all attention heads on the last input token xn.
Since the processing of multiple heads does not change the size of the output vector, it maintains the same embedding space as standard RAG. This use of the activation of the multi-head attention part of the decoder block as embeddings helps capture the potential multi-faceted nature of the data without increasing space requirements.
MRAG Processing Flow
1. Data Preparation
For MRAG, each multi-directional embedding consists of h unidirectional embeddings, each pointing to the original text block, resulting in a data store containing h embedding spaces, with each embedding space capturing different aspects of the text.
2. Constructing Multi-Aspect Embeddings
MRAG can utilize any embedding model with multi-head attention to construct embeddings for a given input text. The paper employs two embedding models from the MTEB leaderboard, namely SFR-Embedding-Model and e5-mistral-7b-instruct. Experimental results indicate that embeddings extracted from the last multi-head attention perform best in the experimental environment.
3. Query Execution
Using the selected embedding model, input query embeddings are generated, and then a special multi-aspect retrieval strategy is applied to find the nearest multi-embeddings and their corresponding text blocks in the data store. The retrieved data can be selectively evaluated using new metrics to assess its correspondence to the requirements.
The MRAG retrieval strategy includes three steps:
a) Assigning Importance Scores
During data preparation, importance scores are assigned to all h embedding spaces, capturing scores that may be more or less relevant to the data used for different spaces (and corresponding heads). The algorithm below details the construction of the importance scores:
The score si of a given head hi consists of two parts, ai and bi.
ai is the average of the L2 norms of all embeddings in vector space i; it represents the importance of the given head: the larger the norm, the more attention is given to that attention head.
bi is the average cosine distance between all embeddings in vector space I (or a randomly sampled subset if the pre-computation time is to be reduced). bi measures the “spread” of vector space i: the larger Bi, the greater the average angle between different embeddings in that space.
By taking si as the product of ai·bi, it ensures that heads with high average attention and high average spread are rewarded, while simultaneously penalizing heads with low average attention or low average spread (ai and bi are appropriately scaled).
b) Obtaining the Nearest Text Blocks
During query execution, MRAG first applies traditional RAG retrieval separately to each embedding space, returning a list of c nearest text blocks for each embedding space (a total of h lists). Then, a special voting strategy is used, leveraging the pre-computed importance scores to select the top k blocks from all hc blocks. The constructed list of text blocks from various embedding spaces is merged into a single list of top k blocks, with the algorithm outlined as follows:

Each text block in the list i of vector space i has a specific position in this list, denoted by p. The weight of a block is calculated as si·2−p, where si is the importance score of space i defined earlier. Multiplying by 2 and then subtracting p reduces the significance of less relevant text blocks.
After obtaining the weights, all blocks in all lists are sorted using their weights, and the top k blocks form the final list.
Experimental Metrics
Dataset Construction
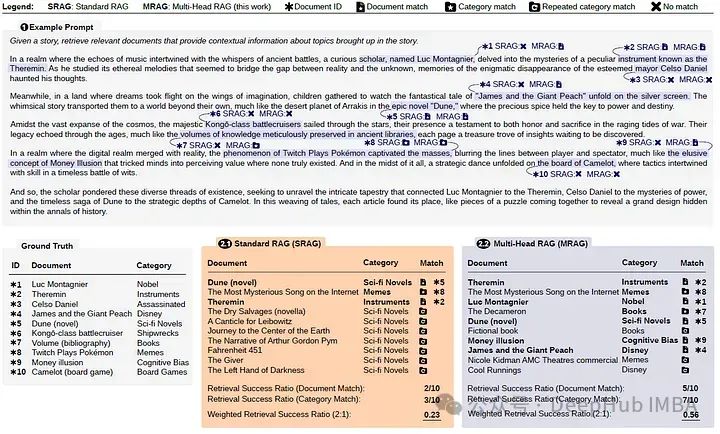
Queries were created by selecting n categories, sampling one document from each selected category (ensuring no duplicates overall), and then using LLM (GPT-3.5 Turbo) to generate a story incorporating these documents. A total of 25 queries were constructed with 1, 5, 10, 15, and 20 aspects (totaling 125 queries).
An example query given to the LLM required retrieving 10 documents from 10 different categories, as shown at the top of the following image:
Metric Calculation
For query Q, retrieval strategy S, and n documents from n categories to be retrieved, Qrel represents the ideal set of documents that should be retrieved for Q. Then, S(Q, n) is the actual set of documents retrieved.
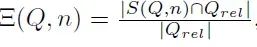
Another metric is defined when the RAG scheme does not retrieve the exact documents needed, but still successfully retrieves other documents from the same category. This metric is called category retrieval success rate. It is the same as the metric mentioned above, but with one difference: S(Q, n) is now the set of all retrieved documents that belong to the ideal required document category.
Finally, these two metrics are combined to obtain a weighted retrieval success rate. By changing w, users can adjust the importance of exact document matching and category matching.
Metric Evaluation
The paper uses two main baselines: standard RAG and Split RAG.
Standard RAG refers to the traditional RAG pipeline, where the activation of the last decoder layer is used as the embedding for each document; Split RAG is a hybrid of standard RAG and MRAG, which splits the activation of the last decoder layer in the same way as MRAG and applies a voting strategy. The purpose of Split RAG is to show that the benefits of MRAG come from using multi-head outputs as embeddings, rather than just using multiple embedding spaces. Fusion RAG is also considered as an optional mechanism that can be utilized to further enhance MRAG, but at the cost of additional token query.
The box plot below shows the retrieval success rate between MRAG and standard RAG across more than 25 queries, each of which includes 10 different aspects.
The results above indicate that MRAG consistently outperforms standard RAG (for exact document matching, the average retrieval success rate increases by > 10%). Additionally, the improvement in retrieval performance in terms of category matching is even more significant (average retrieval success rate improvement > 25%). For the specific number of documents retrieved, the histogram of MRAG shows a better distribution of retrieval success rates (across all 25 queries).
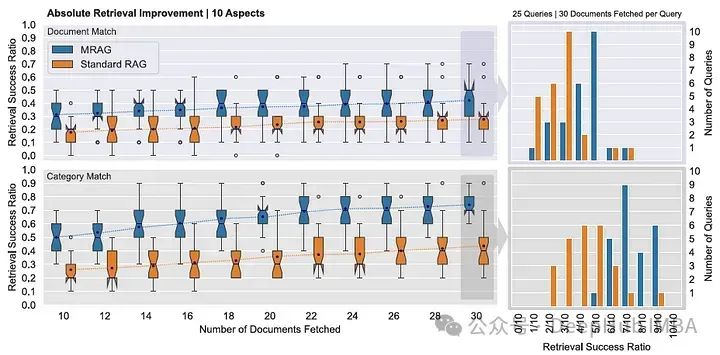
The following figure shows how MRAG’s weighted performance improves relative to standard RAG when we change the number of aspects appearing in the query.
For both models, MRAG’s average performance is consistently 10-20% higher than standard RAG, and the table below shows the retrieval success rate for 25 queries with a single aspect (exact document matching).

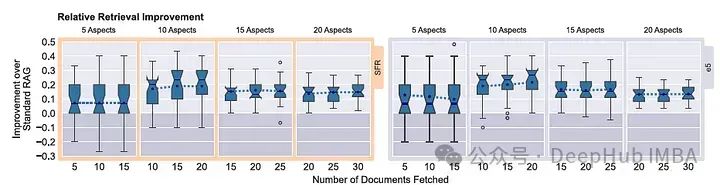
Combining MRAG with Fusion RAG, using LLM (additional token cost) for more accurate retrieval RAG schemes.
Fusion RAG uses LLM to create a fixed number of questions about RAG queries. Each question is applied separately using the embedding model of standard RAG.
The figure below shows the relative retrieval improvement of MRAG with the SFR embedding model compared to standard RAG (blue graph), as well as the relative retrieval improvement of Fusion MRAG compared to Fusion RAG and MRAG (red graph).
Both Fusion RAG and Fusion MRAG outperform standard RAG, with average precision improvements of 10 – 30%.
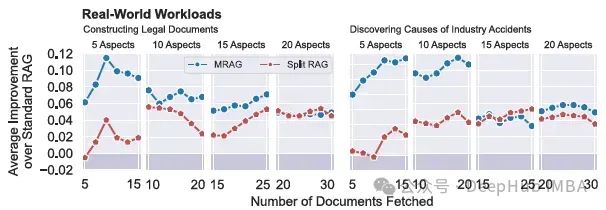
The paper also presents two practical use cases from an internal industry data analysis project, the synthesis of legal documents and the analysis of industrial accident causes. The figure below shows the average improvement in retrieval success rates of MRAG and Split RAG compared to standard RAG in the two practical tasks of constructing legal documents (left) and discovering the causes of industrial accidents (right).
Conclusion
The paper proposes a new scheme that utilizes the multi-head attention layer of the decoder model instead of the traditional feed-forward layer activation—Multi-Head RAG (MRAG). Through a comprehensive evaluation methodology, including specific metrics, synthetic datasets, and practical use cases, the effectiveness of MRAG has been demonstrated.
MRAG shows significant improvements in the relevance of retrieved documents, achieving a performance increase of 20% compared to the traditional RAG baseline, and it does not require additional LLM queries, multiple model instances, or increased storage.
Paper: https://arxiv.org/abs/2406.05085
Code: https://github.com/spcl/MRAG
