Source: Deephub Imba
This article has a total of 2700 words, recommended reading time is 5 minutes.
This article will give you an understanding of the overall architecture of the Transformer.
For many years, deep learning has been continuously evolving. Deep learning practice emphasizes the use of a large number of parameters to extract useful information about the datasets we are working with. By having a large number of parameters, we can classify/detect certain things more easily, as we have more identifiable data.
A significant milestone in deep learning so far, particularly in the field of natural language processing, is the introduction of language models, which greatly improve the accuracy and efficiency of various NLP tasks.
The seq2seq model is a model based on the encoder-decoder mechanism that takes an input sequence and returns an output sequence as a result. For example, in an image captioning task, the input is a given image, and the output is a reasonable description of that image. In this case, the seq2seq model takes the pixel vector of the image (sequence) as input and returns the description (sequence) word by word as output.
Some important DL algorithms that facilitate the training of such models include RNN, LSTM, and GRU. However, over time, the use of these algorithms has gradually diminished because their complexity and some drawbacks severely affect performance as the size of the dataset increases. Important drawbacks include long training times, the vanishing gradient problem (losing information about old data when further training the model on large datasets), and the complexity of the algorithms.
Attention Is All You Need
One of the explosive concepts that replaced all the above algorithms in language model training is the Transformer architecture based on multi-head attention. The Transformer architecture was first introduced by Google in the 2017 paper “Attention Is All You Need”. Its popularity is mainly due to its architecture introducing parallelization. The Transformer utilizes powerful TPUs and parallel training, thereby reducing training time.
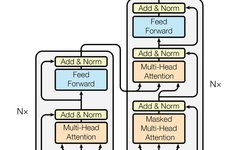
The Transformer architecture looks something like this in its infancy.
Just kidding, below is the most widely circulated visualization of the Transformer architecture.
Even abstracting many details, the entire architecture still looks very large. Each layer in this diagram still hides many detailed things. In this article, we will introduce each layer and its role in the overall architecture.
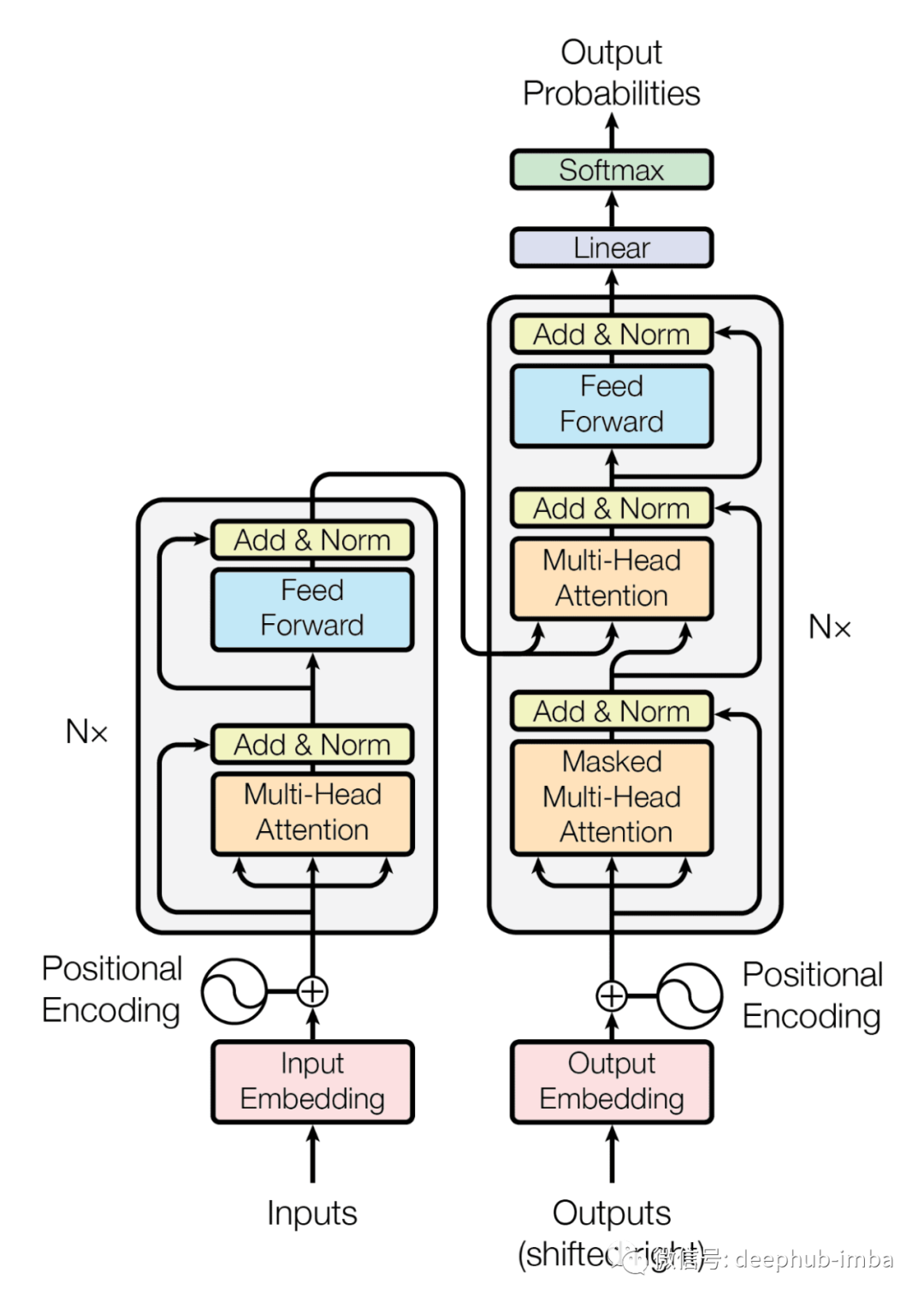
The Transformer is an encoder-decoder model for seq2seq tasks, with input on the left and output on the right. The attention mechanism used internally has become the primary algorithm for language models.
Now we will start to detail the role of each layer. We will use the language translation task example with the simple sentence “I am a student” and its French translation “Je suis étudiant”.
Embedding Layer
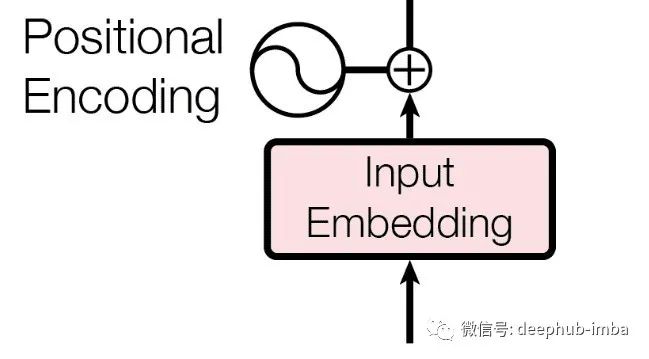
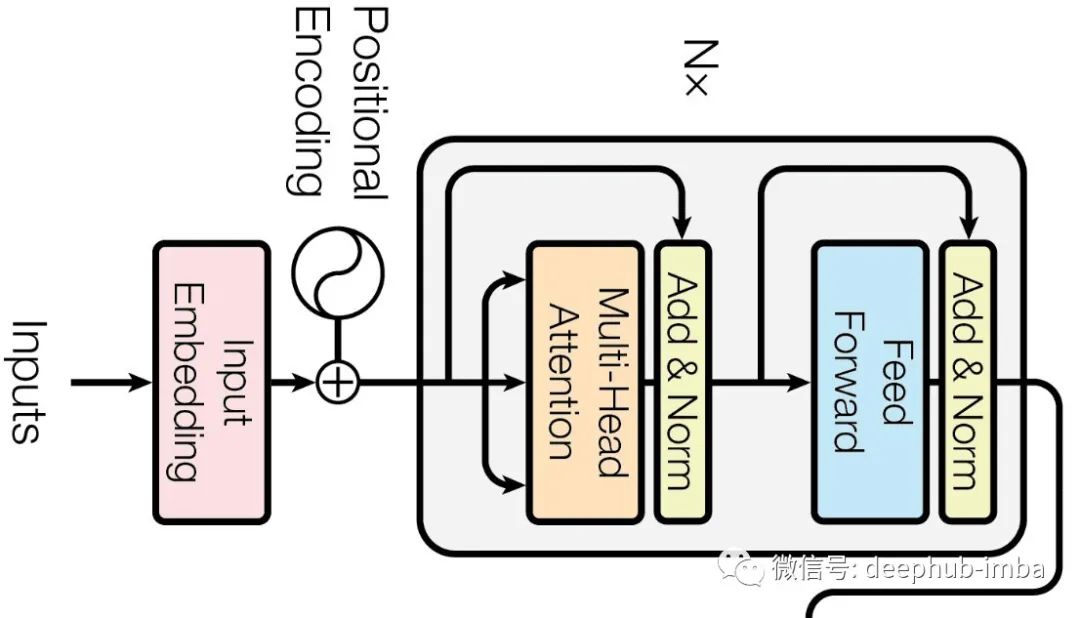
The input embedding is the first step of the Transformer encoder and decoder. Machines cannot understand words in any language; they can only recognize numbers. Therefore, through this layer, we obtain embeddings for each word in the input/output, which can be easily obtained using methods like GloVe. For this embedding value, we add positional information of the word in the sentence (based on different values appearing in odd or even positions) to provide contextual information.
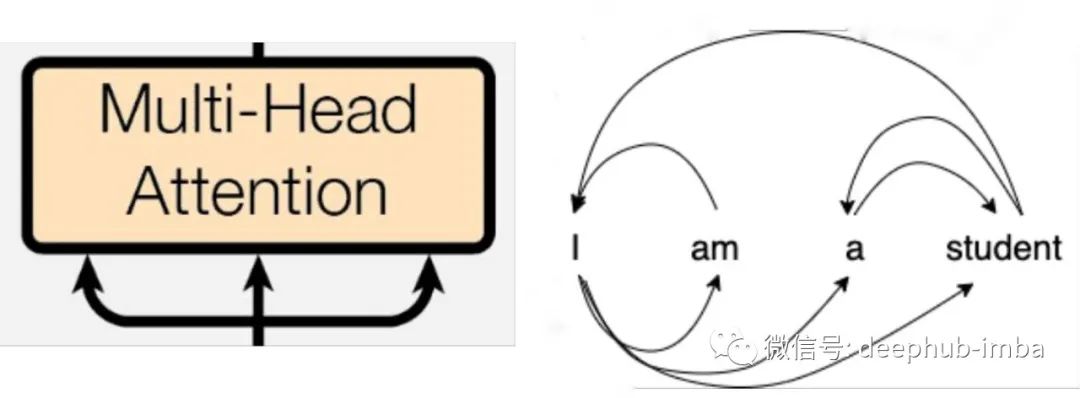
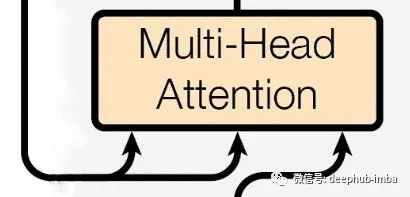
Multi-Head Attention
The multi-head attention layer consists of multiple self-attention layers combined together. The main purpose of the attention layer is to gather information about the relevance of each word in the sentence to other words, thereby obtaining its meaning in the sentence. The above image describes how each word in our sentence depends on other words to provide meaning. However, making the machine understand this dependency and relevance is not so easy.
In our attention layer, we take three input vectors: Query (Q), Key (K), and Value (V). Simply put: Query is like what you search for in a browser, and the browser returns a set of pages to match, which are the Keys, while we get the actual results we need, which are the Values. For the given word (Q) in the sentence, we obtain its relevance and dependency (V) to other words (K). This self-attention process uses different weight matrices of Q, K, and V for multiple hormonal activations. Hence, it is the multi-head attention layer, resulting in multiple attention matrices.
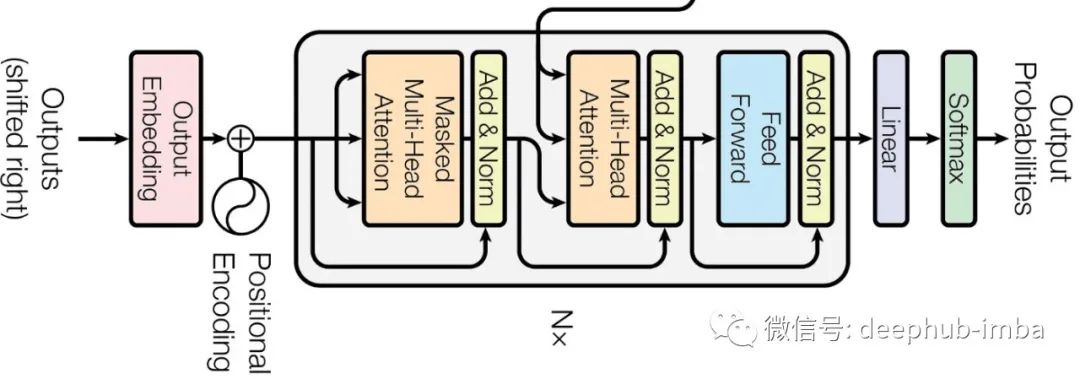
In the architecture, we can see that there are two more attention layers in the decoder.
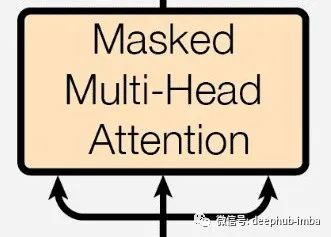
Masked Multi-Head Attention
This is the first attention layer on the decoder side. But why is it masked attention?
In the case of output, if the current word can access all the words after it, it will not learn anything. It will directly continue and suggest outputting this word. However, by masking, we can hide the words after the current word, giving it space to predict what word makes sense so far for the given word and sentence. It already has the embedding and positional information of the current word, so we use all the words seen before with Q, K, and V vectors to make it meaningful and find the most likely next word.
Encoder-Decoder Attention
The next multi-head attention layer on the decoder side takes two inputs (K, V) from the encoder side and another (Q) from the previous attention layer of the decoder, allowing it to access attention values from both input and output. Based on the current attention information from both input and output, it interacts between the two languages and learns the relationship between each word in the input sentence and the output sentence.
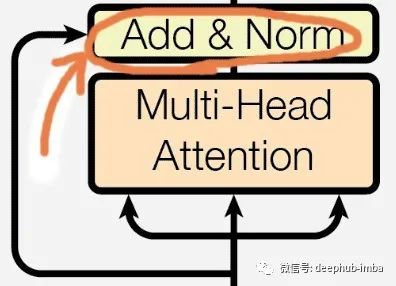
Residual Layer
These attention layers will return a set of attention matrices, which will be merged with the actual input, and layer/batch normalization will be performed. This normalization helps to smooth the loss, making it easier to optimize with a larger learning rate.
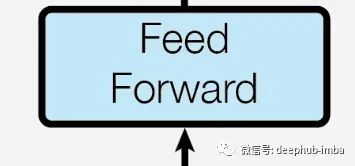
Feed Forward Layer
In the encoder block, the feedforward network is a simple module that takes the average attention values and transforms them into a format that is easier for the next layer to handle. It can either be another encoder layer at the top or passed to the encoder-decoder attention layer on the decoder side.
In the decoder block, we also have another feedforward network that performs the same function and passes the transformed attention values to the next decoder layer or linear layer at the top.
A major feature of the Transformer occurs at this layer; unlike traditional RNNs, where each word can independently pass through the neural network based on its attention values, this layer is parallelized. We can pass all words in the input sentence simultaneously, allowing the encoder to process all words in parallel and provide encoder outputs.
Output
After all processing is completed on the decoder side, the data is sent to the output processing layer with a linear layer and softmax layer. The linear layer is used to flatten the attention values from the neural network, and then softmax is applied to find the probabilities of all words, from which we obtain the most likely word. The model essentially predicts the next possible word as the probability of output from the decoder layer.
Overall Summary
Now let’s quickly go through the entire process.
Each word in the input sentence is passed in parallel. Word embeddings are taken, and positional information is added to provide context. Then there is a multi-head attention layer that learns the relevance to other words, producing multiple attention vectors. These vectors are then averaged and a normalization layer is applied to simplify optimization. These vectors are passed to the feedforward network, which converts the values into a dimension readable by the next encoder or encoder-decoder attention layer.
First, there is a similar preprocessing step of word embedding and adding context. Then through a masked attention layer, it can learn the attention between the current word of the output sentence and all previously seen words, without allowing upcoming words. It is then normalized through a residual connection and normalization layer, with the output from the encoder layer used as Key and Value vectors to the next attention layer, where the Value (V) of the attention used by the next decoder layer is taken as Query (Q). The interaction between input and output languages occurs here, allowing the algorithm to better understand language translation.
Finally, another feedforward network passes the transformed output to a linear layer, flattening the attention values, and then through the softmax layer to obtain the probabilities of all words in the output language for the next occurrence. The word with the highest probability will become the output.
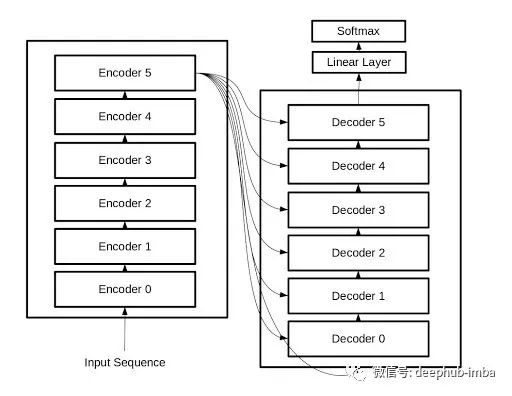
Stacking of Encoders and Decoders
Stacking encoders and decoders is also effective as it can better learn tasks and improve the algorithm’s predictive ability. In the actual paper, Google stacked 6 encoders and decoders. However, care must be taken to ensure that it does not overfit and make the training process expensive.
Final Summary
Since Google launched Transformers, it has been revolutionary in the field of NLP. It has been used to develop various language models, including the acclaimed BERT, GPT2, and GPT3, outperforming previous models in all language tasks. Understanding the architecture will certainly give you an edge in the game.