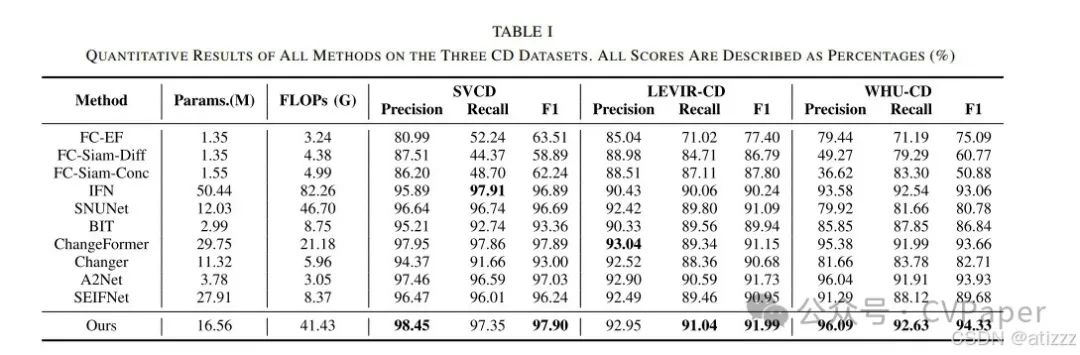
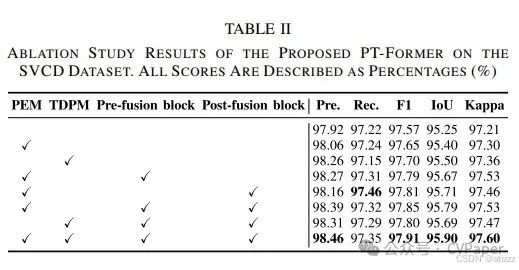
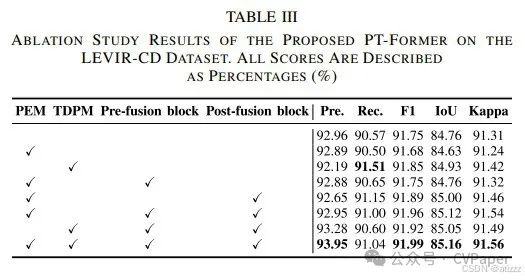
With the development of deep learning, remote sensing (RS) image change detection (CD) methods have made significant progress. However, many convolutional neural network (CNN)-based methods are limited in capturing long-range dependencies due to the constraints of receptive fields. Transformers, relying on self-attention mechanisms, effectively model global information and are widely used in CD tasks. Nevertheless, transformer-based CD methods still face issues such as false changes and incomplete edges, which arise from the lack of spatial and temporal correlations in dual-temporal RS images. To address this issue, the authors propose a Position-Temporal Awareness Transformer (PT-Former) that models spatial and temporal relationships in dual-temporal images. Specifically, a twin network connected to a Position Awareness Embedding Module (PEM) serves as a feature encoder to extract features of change regions. Then, a Temporal Difference Awareness Module (TDPM) is designed to capture cross-temporal shifts and enhance the ability to perceive differences during cross-temporal interactions. Meanwhile, a fusion block aggregates contextual information of ground objects and reconstructs spatial relationships under the guidance of dual-temporal features. Experimental results validate the superiority of PT-Former on three benchmark datasets, including the Seasonal Variation Change Detection (SVCD) dataset, Learning Visual and RS Laboratory Building Change Detection (LEVIR-CD) dataset, and WHU-CD dataset, confirming the potential of PT-Former in RS image CD tasks.
Part 1 Methodology
In this section, we first introduce the overall structure of the model. PT-Former mainly consists of four modules: Transformer, PEM, TDPM, and fusion blocks. We will detail these in the following sections. Additionally, we will provide the model’s loss function.
Overview
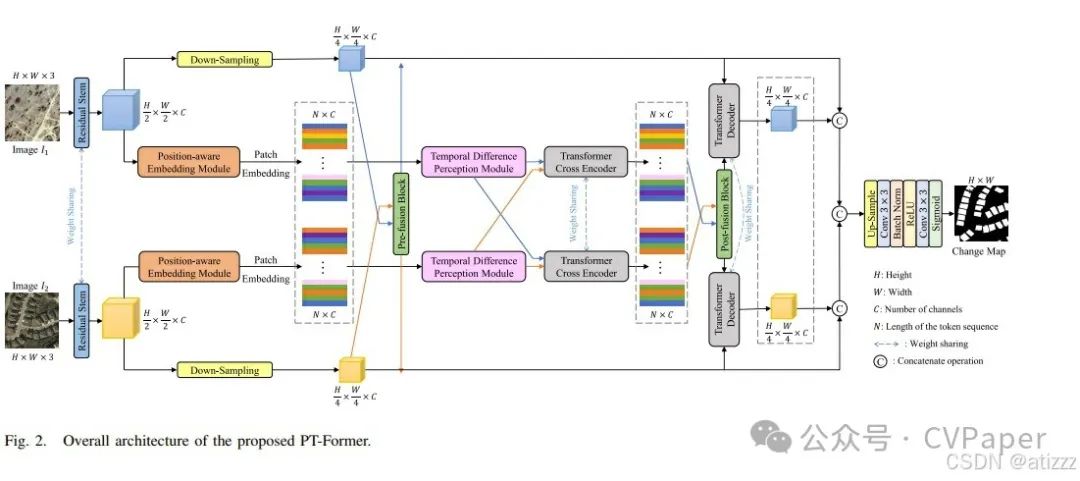
The overall structure of PT-Former is shown in Figure 2. PT-Former takes three-channel dual-temporal RS images as input and outputs a two-channel change prediction map. The dual-temporal RS images input to PT-Former are progressively fed into a dual-branch residual stem with shared weights. In the proposed PT-Former, a modified ResNet-18[24] is used for feature extraction. After reducing spatial resolution and semantic extraction, the feature maps are input to PEM to generate position embeddings, which are then flattened and embedded features through PEM. To capture cross-temporal shifts and enhance the ability to perceive differences during cross-temporal interactions, the dual-temporal features are input to TDPM. Features continue through a transformer cross-encoder with cross-attention, and the features are reshaped. Meanwhile, feature maps from the residual stem are downsampled and fused by the front fusion block. Next, the features extracted from the transformer encoder are aggregated by the back fusion block. Then, the fused features are input to the transformer decoder. Furthermore, to enhance the features of change regions, the features extracted from the transformer decoder and the back fusion block are concatenated. Finally, to infer the change map of the observed scene, a classifier head is introduced to generate the change map.
Transformer Block
Revisiting Self-Attention in Transformers: In transformer-based vision tasks, the size of the feature map F is H×W×C, which is typically flattened to a token T of size N×C as input to the transformer block, where H represents the height of the feature map, W represents the width of the feature map, C represents the number of channels in the feature map or tokens, and N=HW represents the length of the token sequence. In the transformer block, the token T is projected into query Q, key K, and value V embeddings. The self-attention of the transformer is computed as follows:
Where d is the scaling factor.
Transformer with Cross-Attention: To enhance the interaction between dual-temporal features, we introduce a transformer cross-encoder with cross-attention. Specifically, we receive dual-temporal tokens T1 and T2 as input and project them into Q1, K1, V1 and Q2, K2, V2. We perform cross-attention on the dual-temporal embeddings. The cross-attention computation is as follows:
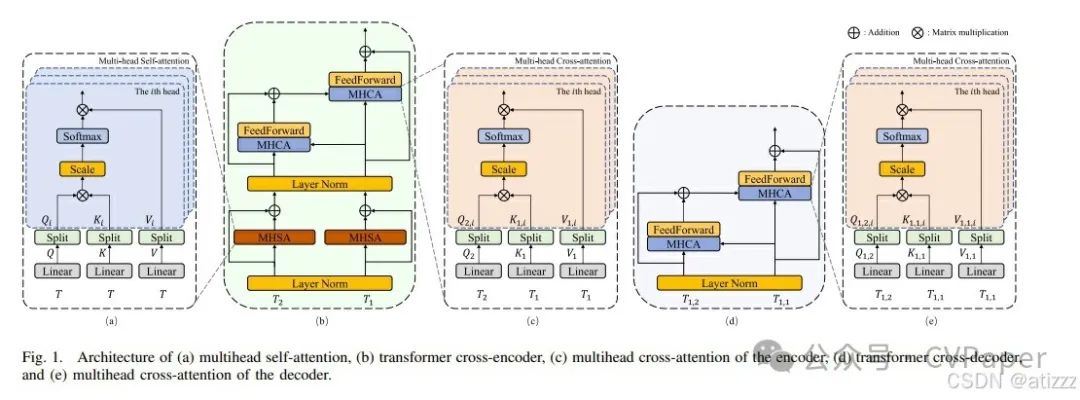
Based on cross-attention, we further extract change information from the dual-temporal tokens T1 and T2 using the transformer cross-encoder. Figure 1(b) shows the architecture of the transformer cross-encoder for token T1. The transformer cross-encoder consists of two multi-head self-attention and two multi-head cross-attention blocks. Thus, the process in Figure 1(b) can be represented as follows:Where LN(·) is layer normalization, MHSA(·) is multi-head self-attention, MHCA(·) is multi-head cross-attention, and FF(·) is the feed-forward layer. In PT-Former, the multi-head mechanisms described in Figures 1(a) and (c) aim to leverage representations from different subspaces. Using multiple heads allows for more effective exploration of attention patterns between query, key, and value components. To simplify computational complexity, the projected features are divided into N parts along the feature dimension; N represents the number of heads in Figures 1(a) and (c). Finally, multi-head self-attention MHSA(·) and multi-head cross-attention MHCA(·) are represented as follows:\text{shead}_i = \text{Self-Attention}(Q, K, V)\text{chead}_i = \text{Cross-Attention}(Q_2, K_1, V_1)
$$The processing of T2 follows the same procedure as shown in Figure 1(b). To convey change information from the fusion block, a transformer decoder with cross-attention is constructed. Figure 1(d) shows the architecture of the transformer decoder for tokens from the fusion block. For the pre-temporal image, tokens T1,1 and T1,2 come from two fusion blocks, respectively. The size of key K1,1 and value V1,1 is N×C, obtained through a linear projection from T1,1. Then, the query Q1,2 of size N×C is obtained from T1,2. The process of the transformer cross-decoder is represented as:In the transformer cross-decoder, the projected features are divided into R parts along the horizontal dimension to reduce complexity. Figure 1(e) shows the multi-head cross-attention of the decoder; R is the number of heads. Multi-head cross-attention MHCA(·) is represented as:Similarly, T2 is obtained through the transformer cross-decoder to refine change information in the post-temporal image. Finally, we obtain enhanced change features at a fine scale, which are then concatenated with other features.
Position Awareness Embedding Module
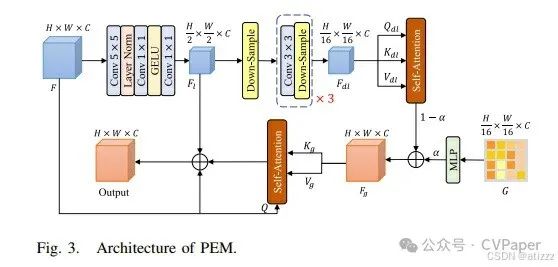
Currently, many transformer-based methods exist to capture long-range dependencies. However, these methods do not fully utilize the capabilities of transformers as they rely on spatial attention mechanisms to capture spatial information. Furthermore, for CD tasks, the positional relationships between features are extremely important; for instance, when detecting changes in buildings in the Learning Visual and RS Laboratory Building Change Detection (LEVIR-CD) dataset, some pixels at the edges of buildings are most likely to be missed. By introducing position embeddings, the positional information of edge pixels makes them easier to detect. To this end, the PEM is designed to learn global change-related information and fine-grained local context in dual-temporal feature maps. Generally, regular transformer tokens are 1-D and provide limited positional information. In contrast, our position embeddings are 2-D, thus containing richer positional information. This extension allows for more precise change localization, thereby enhancing the model’s ability to perceive spatial changes. Figure 3 shows the architecture; to enhance the ability to perceive spatial changes, we extract local and global positional information separately and then fuse these two parts. First, we use convolutional blocks to extract local positional information in PEM, as convolution performs better than window self-attention in extracting local positional information. The convolution block is represented as follows:Where F is the input feature map of size H×W×C, DW is the depthwise convolution with a kernel size of 5, PW1() and PW2() are pointwise convolutions with a kernel size of 1, and Fl is the output with local positional information. To reduce the complexity of extracting global positional information, the local positional information F is downsampled and aggregated into global positional information. The downsampling process is repeated three times until the size of the feature map reaches the expected size of (H/16)×(W/16)×C. Compared to a one-step downsampling method, the stepwise downsampling method can reduce the loss of semantic information and retain more useful information. The entire downsampling process is represented as follows:Where PW() represents convolution with a kernel size of 3, and DS() represents the downsampling operation. Global positional information Fg is aggregated through self-attention, and we use learnable positional tokens to enrich the global positional information Fg. Before fusion, we apply MLP to the learnable positional tokens. The process is represented as follows:Where Qdl, Kdl, and Vdl are produced through linear projection from Fdl. α∈[0,1] is a pre-defined weight. SA() represents self-attention. MLP() represents the MLP layer.Global positional information is broadcasted to the input feature map through self-attention. Finally, the output feature map contains both local and global positional information:Where Q is produced through linear projection from the input feature map, and Kg and Vg are produced through linear projection from Fg.
Temporal Difference Awareness Module
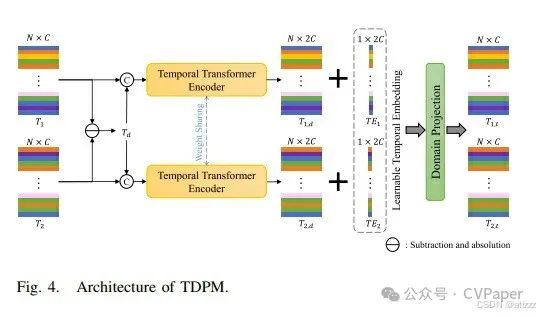
Another issue with dual-temporal image CD is false changes, primarily caused by temporal-related factors such as different acquisition times, lighting conditions, and seasonal variations. For example, significant visual and feature differences exist in the same building taken on cloudy and sunny days, which are defined in this paper as cross-temporal shifts. The cross-temporal shifts between pre-temporal and post-temporal images in the entire dataset are often the same. To address this issue, we aim to capture these cross-temporal shifts and enhance the temporal discriminative ability during feature interactions by integrating learnable temporal embeddings into pre-temporal and post-temporal features, ultimately eliminating cross-temporal shifts. Figure 4 shows the architecture. Through the patch embedding in Figure 2, dual-temporal features are embedded and flattened into tokens T1 and T2, shaped as N×C. In TDPM, T1 and T2 are first subtracted to obtain the absolute operation of the cross-feature difference token Td. Then, Td is concatenated with T1 and T2 to obtain the difference fusion features. To extract temporal information from the features, the difference fusion features are input into the temporal transformer encoder to obtain features T1,d and T2,d:Where TTE() represents the temporal transformer encoder. To reduce false changes caused by cross-temporal feature shifts, we define learnable temporal embeddings TE1 and TE2. TE1 and TE2 have sizes of 1×2C. We add the corresponding temporal embeddings TE1 and TE2 to T1,d and T2,d, eliminating the impact of cross-temporal shifts on features T1,d and T2,d. Finally, the temporal-aware features T1,t and T2,t are obtained through linear projection:Where DP() represents domain projection. T1,t and T2,t have sizes of N×C.
Fusion Block
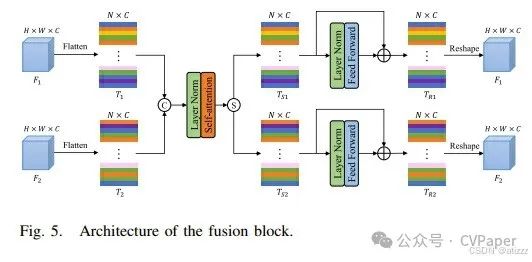
The fusion of dual-temporal features plays a crucial role in CD, forming complete change information under the guidance of dual-temporal features. Moreover, to integrate contextual information of ground objects and reconstruct spatial relationships of ground objects, fusion blocks are designed to fuse dual-temporal features at multiple stages, as shown in Figure 5 (front fusion block and back fusion block). First, the dual-temporal features F1 and F2 of size H×W×C are flattened into tokens T1 and T2 of size N×C, where N=HW. Then, T1 and T2 are concatenated, and layer normalization is applied. To capture the relational changes between dual-temporal tokens, self-attention is introduced to extract global contextual information. The process can be written as follows:Where Flatten() represents the flattening operation. Next, the fused features TS are split into dual-temporal tokens TS1 and TS2. Then, layer normalization and feed-forward layers are applied to TS1 and TS2, introducing a residual structure to simplify the model learning process:Where S() represents the splitting operation. The feed-forward layer consists of two linear layers with Gaussian Error Linear Unit (GELU) activation functions. Finally, the dual-temporal features F1 and F2 are reshaped through TR1 and TR2.
Loss Function
A common problem encountered in RS CD is the class distribution imbalance between false positive pixels. This imbalance often hinders effective optimization and may cause the network to get stuck in local minima of the loss function. To tackle this challenge and learn from complex scenarios, we recommend adopting a hybrid loss function that combines binary cross-entropy (BCE) loss with Dice loss. The formula for the hybrid loss function is as follows:Where λ is the coefficient defined in the hybrid loss function. To explain the concepts of BCE loss and Dice loss, we consider the predicted change map (\hat{Y}) and the reference map Y as sets of pixels, represented as (\hat{Y} = {\hat{y}_i, i = 1, 2, …, N}) and Y = ({y_i, i = 1, 2, …, N}). Here, (\hat{y}) represents the probability of change for the i-th pixel, while (y_i) represents the reference value for the i-th pixel. In this context, a value of 0 indicates an unchanged pixel, while a value of 1 indicates a changed pixel. The total number of pixels in the change map is represented by N. The combined objective function of these two loss functions can be expressed as:
Part 2 Experimental Results
StatementThis article is a sharing of insights from a research paper. Due to limitations in knowledge and ability, the understanding of the original text may have deviations, and the final content is subject to the original paper. The information in this article is intended for dissemination and academic exchange, and its content is the responsibility of the author, not representing the views of this account. If there are any issues regarding content, copyright, or others, please contact us in a timely manner, and we will respond and handle them as soon as possible.
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply with "Chinese Tutorial for Extension Module" in the backend of "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial covering over twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply with "Python Vision Practical Project" in the backend of "Beginner's Guide to Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to facilitate rapid learning of computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply with "OpenCV Practical Project 20 Lectures" in the backend of "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV for advancing OpenCV learning.
Group Chat
Welcome to join the reader group of the public account to exchange ideas with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, with the note: "Nickname + School/Company + Research Direction", e.g., "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be approved. After successful addition, invitations to relevant WeChat groups will be sent based on research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~