1 Introduction to Algorithms
2 Algorithm Implementation
3 Applications
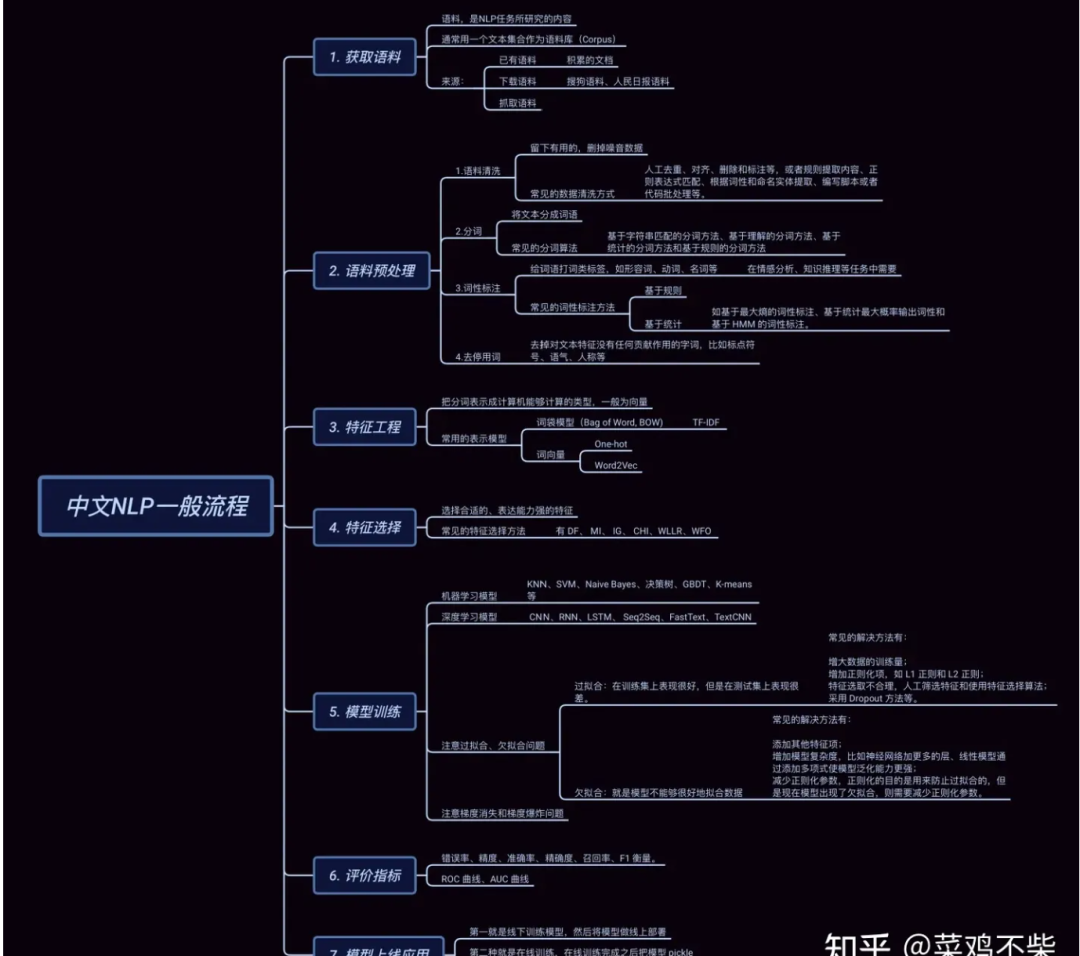
Through natural language processing technology, various applications such as machine translation, question-answering systems, sentiment analysis, and text summarization can be realized. With the development of deep learning technology, artificial neural networks and other machine learning methods have made significant progress in the field of natural language processing. Future development directions include deeper semantic understanding, better dialogue systems, broader cross-language processing, and more powerful transfer learning techniques.
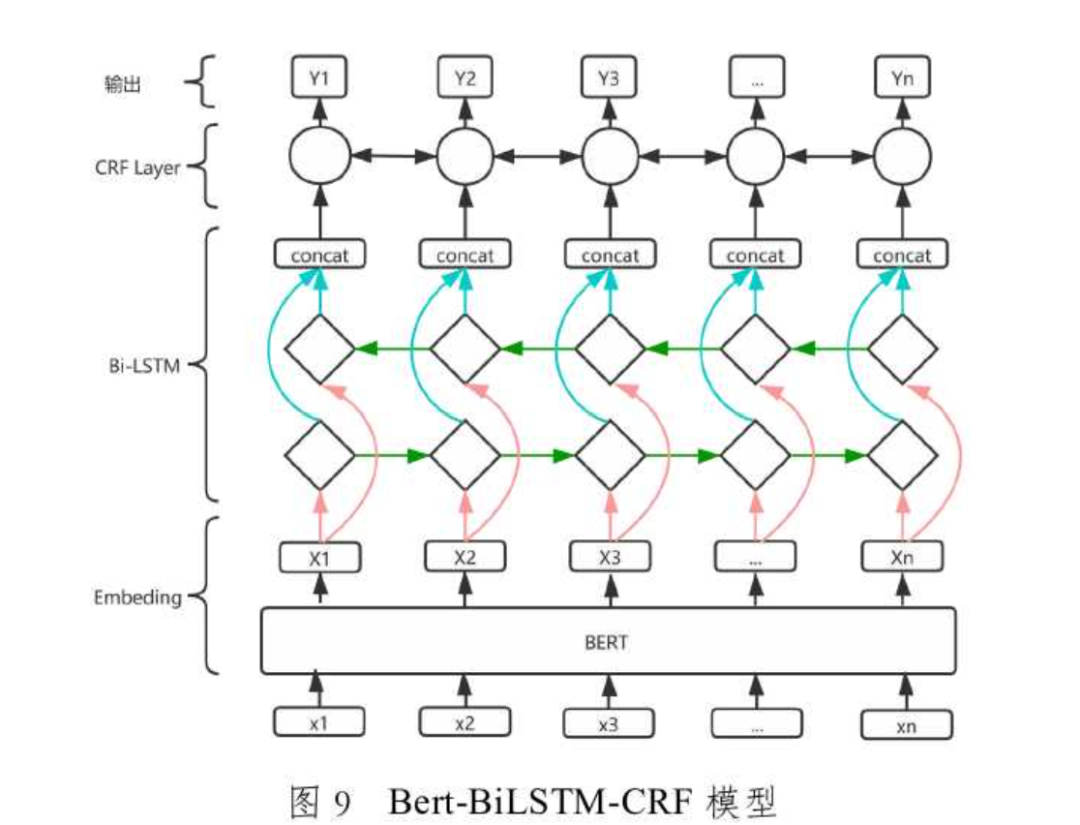
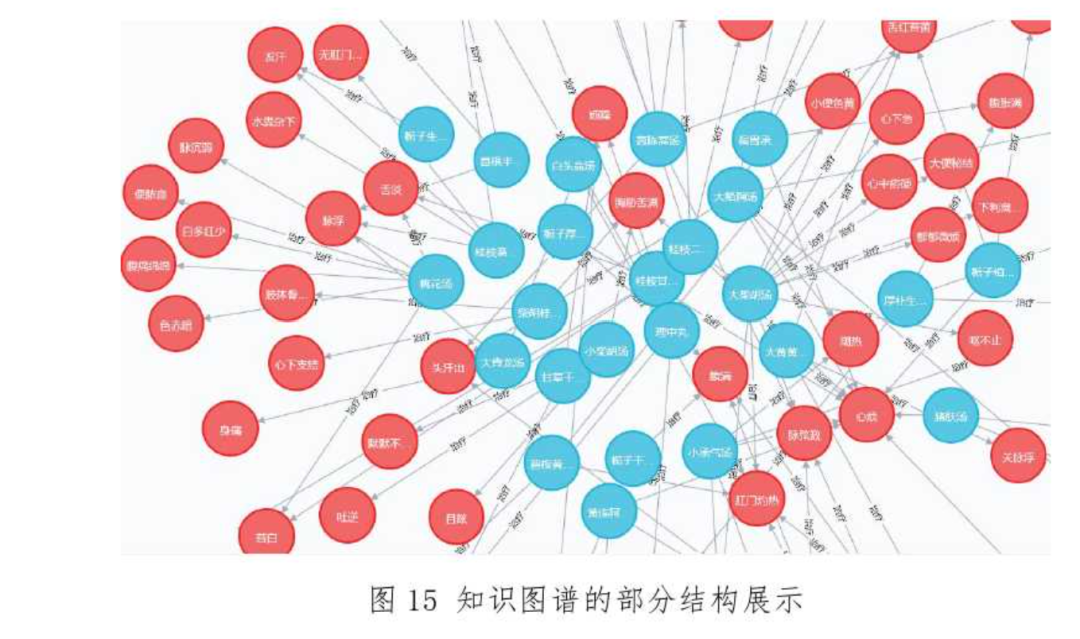
In the field of traditional Chinese medicine (TCM), the application of natural language processing is primarily reflected in named entity recognition, relationship extraction, and clustering analysis, which can be used for mining ancient TCM texts, constructing TCM knowledge graphs, and conducting text clustering analysis. For example, in the study of “Shang Han Lun,” researchers utilized natural language processing methods for information extraction and knowledge presentation. This not only organized the content of “Shang Han Lun” but also provided reference methods for converting ancient TCM texts into structured clinical data. Researchers annotated “Shang Han Lun” according to the BIO annotation rules and identified entities within the text using various neural network models, analyzing from both entity types and model performance, ultimately concluding that Bert-Bi LSTM-CRF is the best model for entity recognition in “Shang Han Lun.” After completing named entity recognition, relationships between entities were extracted using rule-based methods. The construction of knowledge graphs was achieved through the neo4j database, realizing the goal of knowledge visualization in “Shang Han Lun.” The Naive Bayes algorithm was used to calculate the weights between prescriptions and symptoms, which were then inserted as attributes into the relationships between prescriptions and symptoms, further refining the construction of the knowledge graph.
4 Conclusion
Currently, the application of natural language processing technology in TCM is still in its early stages, but it serves as an effective tool in the study of TCM texts. When utilizing natural language processing technology for research on TCM texts, two aspects can be focused on: first, the construction of word vectors for TCM texts; second, the extraction of entity relationships in TCM texts.
At present, there are many models for constructing word vectors, but most of them use corpora from Wikipedia or Baidu Encyclopedia, which do not fully match the characteristics of TCM texts. Therefore, combining the corpus with models to build TCM-specific word vectors can be explored. In the application of natural language processing, any application relies on the extraction of entity relationships in TCM texts. Therefore, researching a model with high accuracy and high transferability for entity relationships in TCM texts is of great significance for the intelligent development of TCM.
References:
[1] Zhihu Column. “What is Natural Language Processing? This Article is Enough!” Retrieved on October 24, 2023. https://zhuanlan.zhihu.com/p/634689142.
[2] Qu Qianqian. Research on “Shang Han Lun” Based on Natural Language Processing [D]. Anhui University of Traditional Chinese Medicine, 2022. DOI:10.26922/d.cnki.ganzc.2021.000192.

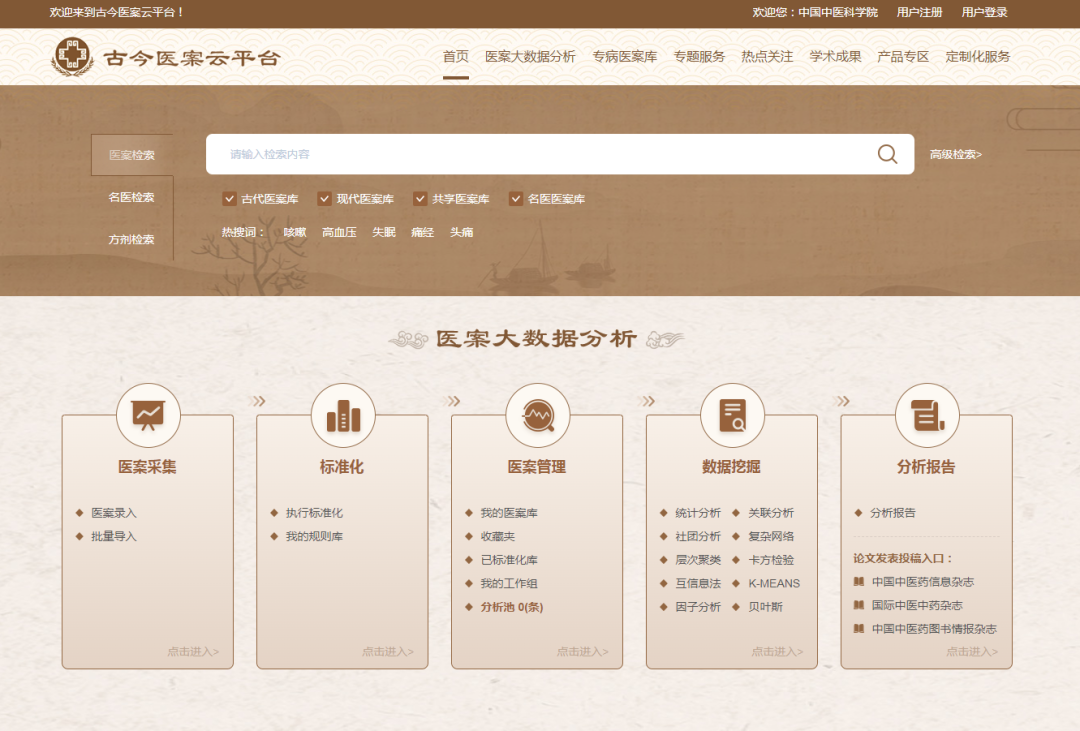
Ancient and Modern Medical Case Cloud Platform
Providing over 500,000 ancient and modern medical case retrieval services
Supports manual, voice, OCR, and batch structured entry of medical cases
Designed with nine analytical modules, close to clinical practical needs
Supports collaborative analysis of massive medical cases and personal cases on the platform
EDC TCM Research Case Collection System
Supports multi-center, online random grouping, and data entry
SDV, audit trail, SMS reminders, data statistics
Analysis and other functions
Supports customized form design
Users can log in at: https://www.yiankb.com/edc
Free trial!
Institute of Chinese Medical Sciences, Chinese Academy of Traditional Chinese Medicine
Big Health Intelligent R&D Center
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com