
Author: Pratik Bhavsar
Translation: ronghuaiyang
Frequently asked questions in NLP interviews.
Practicing NLP is one thing, cracking interviews is another. Interviews for NLP positions are very different from general data science roles. In just a few years, these questions have completely changed due to transfer learning and new language models. From my personal experience, NLP interviews have become increasingly challenging over time as we have made more progress.
Earlier, it was all about SGD, naive-bayes, and LSTM, but now it’s more about LAMB, transformers, and BERT.
This article is a small summary of some questions I encountered during interviews, hoping to help with some important aspects of current NLP interviews. After the transformer architecture, I focused more on what is happening in NLP, which is also the main focus of my interview questions.
These questions are crucial for evaluating NLP engineers; if you are not asked any of them, you might be interviewing an outdated NLP team with a narrower scope of complex work.
What is perplexity? What is its significance in NLP?
Perplexity is a way of expressing the degree of confusion a model has in its predictions. The higher the entropy = the more confusion. Perplexity is used to evaluate language models in NLP. A good language model assigns higher probabilities to correct predictions.
What are the issues with ReLu?
-
Exploding gradients (solved by gradient clipping) -
Dead ReLu – no learning occurs when activation is 0 (solved by using parametric ReLu) -
The mean and variance of activation values are not 0 and 1. (partially solved by subtracting about 0.5 from the activation. There’s a better explanation in fastai’s videos)
What is the difference between using SVD to learn latent features and using deep networks to obtain embedding vectors?
SVD uses linear combinations of inputs, while neural networks use nonlinear combinations.
What information is stored in the hidden and cell states of LSTM?
The hidden state stores all information up to the current time step, while the cell state stores specific information that may be needed in future time steps.
Number of parameters in an LSTM model with bias
4(𝑚h+h²+h) where 𝑚 is the size of the input vector, h is the size of the output vector, hidden is the same.
Note that in mh m>>h. Therefore, an important point is to use a small vocabulary.
Complexity of LSTM
Sequence length * hidden²
Time complexity of transformers
Sequence length² * hidden
When the hidden size is greater than the sequence length (which is usually the case), transformers are faster than LSTM.
Why is self-attention so powerful?
“In terms of computational complexity, when the sequence length n is less than the representation dimension d, self-attention layers are faster than recurrent layers, which is often the case in practice, while also allowing the use of state-of-the-art models for sentence representation in machine translation, such as word-piece and byte-pair representations.” — Attention is all you need

What are the limitations of the Adam optimizer?
While training with Adam helps achieve fast convergence, the generalization performance of the resulting model is often not as good as that obtained with momentum training using SGD. Another issue is that even though Adam has an adaptive learning rate, its performance can improve when using a good learning rate schedule. Especially in the early stages of training, using a lower learning rate to avoid divergence is beneficial. This is because the model’s weights are random at the beginning, so the gradients obtained are not very reliable. If the learning rate is too high, it may cause the model to take too large steps without settling on appropriate weights. Once the model overcomes these initial stability issues, learning speed can be increased to accelerate convergence. This process is called learning rate warming, one version of which is described in the paper “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”.
What is the difference between AdamW and Adam?
AdamW uses L2 regularization on weights, which helps small weights generalize better.
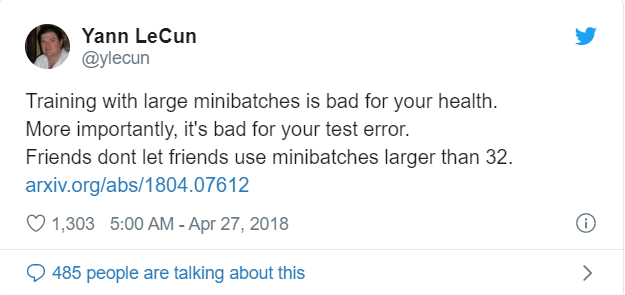
Can using a large batch size train the model faster?
Yes!
In a tweet from April 2018, Yann suggested not to use large batch sizes.
Good News!
This was previously impossible, but now with new optimizers like LARS and LAMB, it is possible. ALBERT was trained using LAMB with a batch size of 4096.
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes: https://arxiv.org/abs/1904.00962
Do you prefer feature extraction or fine-tuning? How do you decide? Will you use BERT as a feature extractor or fine-tune it?
This is a subjective question; you can read more to understand.
Transfer Learning in NLP: https://medium.com/modern-nlp/transfer-learning-in-nlp-f5035cc3f62f
Can you give an example of a learning rate scheduling strategy?
Explain Leslie Smith’s cycle strategy.
Should we perform cross-validation in deep learning?
No.
As the sample size increases, the variance of cross-folds decreases. Since we only perform deep learning when we have thousands of samples, cross-validation is not very meaningful.
In multi-task learning, what is the difference between soft and hard parameter sharing?
In hard sharing, we train all tasks at once and update weights based on all losses. In soft sharing, we train one task at a time.
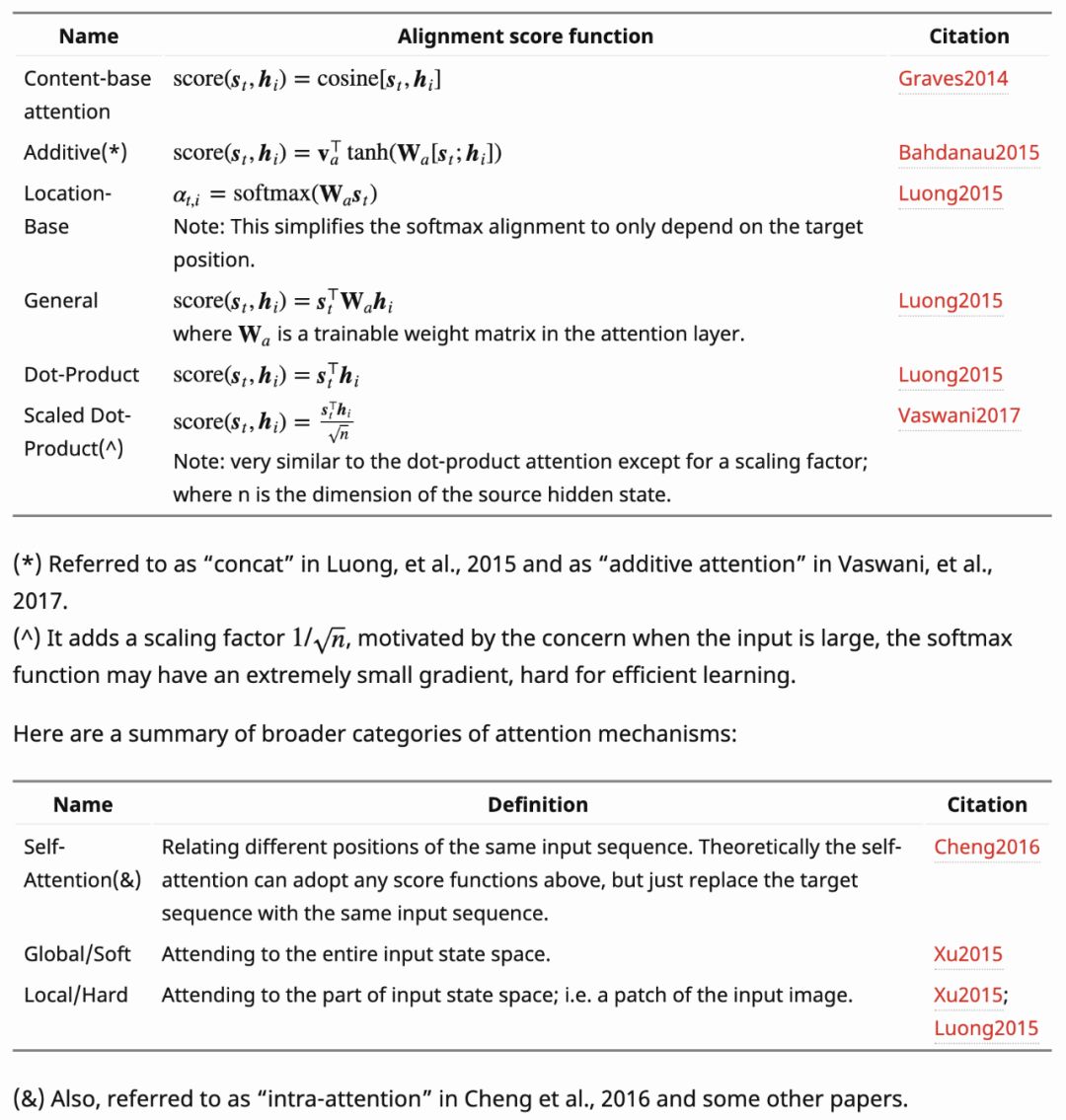
What are the different types of attention mechanisms?
What is the difference between BatchNorm and LayerNorm?
BatchNorm – calculates the mean and variance for each layer for each mini-batch
LayerNorm – calculates the mean and variance for each sample in each layer independently
Why do transformer blocks use LayerNorm instead of BatchNorm?
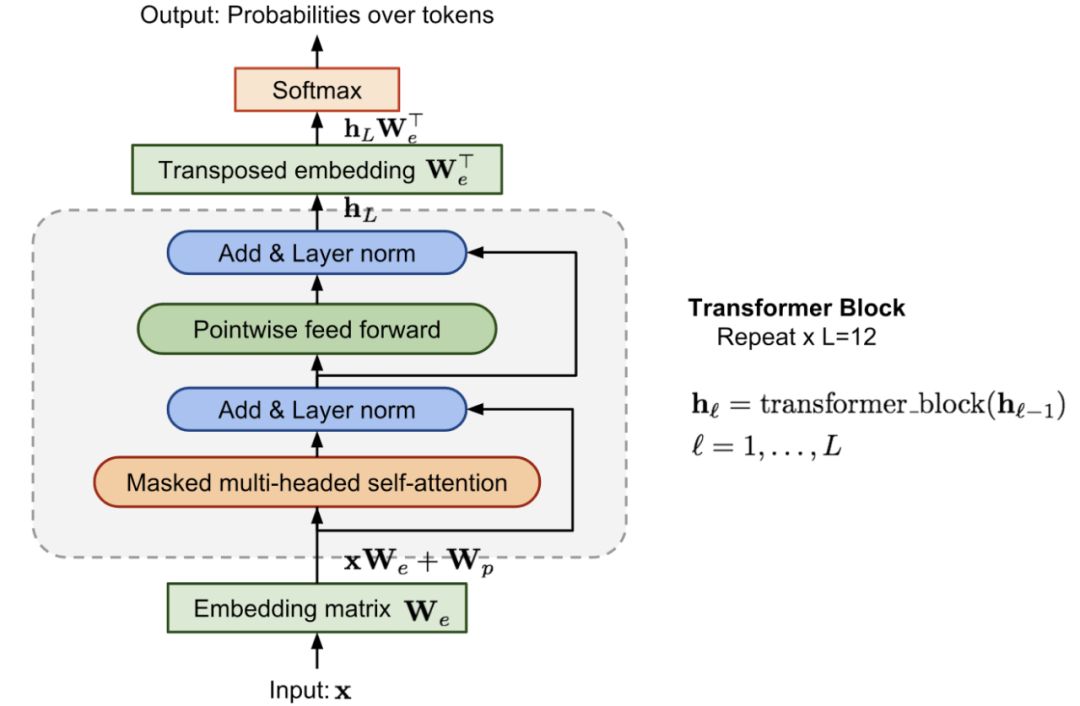
From the perspective of the advantages of LayerNorm, it is robust to batch sizes and works better at the sample level rather than the batch level.
If you know your training data has errors, what would you change in your deep learning code?
We can perform label smoothing, where the smoothing value is based on percentage error. If any particular class has known errors, we can also use class weights to correct the loss.
How do you choose a text encoder for a task? What is your favorite text encoder? Why?
This is a subjective question; you can read more to understand.
Variety Of Encoders In NLP: https://medium.com/modern-nlp/on-variety-of-encoding-text-8b7623969d1e
What techniques were used in ULMFiT? (not a very good question, but can check awareness)
-
Fine-tuning the language model with task text -
Weight dropout -
Independent learning rates for each layer -
Progressive unfreezing of layers -
Triangular learning rate strategy
A follow-up question could explain how they help.
Why does the transformer perform better than LSTM?
https://medium.com/saarthi-ai/transformers-attention-based-seq2seq-machine-translation-a28940aaa4fe
Interesting question: Which layer is used most in transformers?
Dropout 😂
Tricky question: Tell me a language model that does not use dropout
ALBERT v2: This illustrates that many assumptions we take for granted are not necessarily correct. The regularization effect of parameter sharing in ALBERT is very strong, and dropout is not needed. (ALBERT v1 has dropouts.)
What are the differences between GPT and GPT-2?
-
Layer normalization is placed in each sub-block, similar to the “building block” of residual units (not the original “bottleneck”, which had batch normalization before the weight layer). -
An additional layer normalization is added after the last self-attention block. -
Modification of initialization based on model depth. -
Residual layer weights are initially scaled by 1/√n, where n is the number of residual layers. -
Using a larger vocabulary and context.
What are the differences between GPT and BERT?
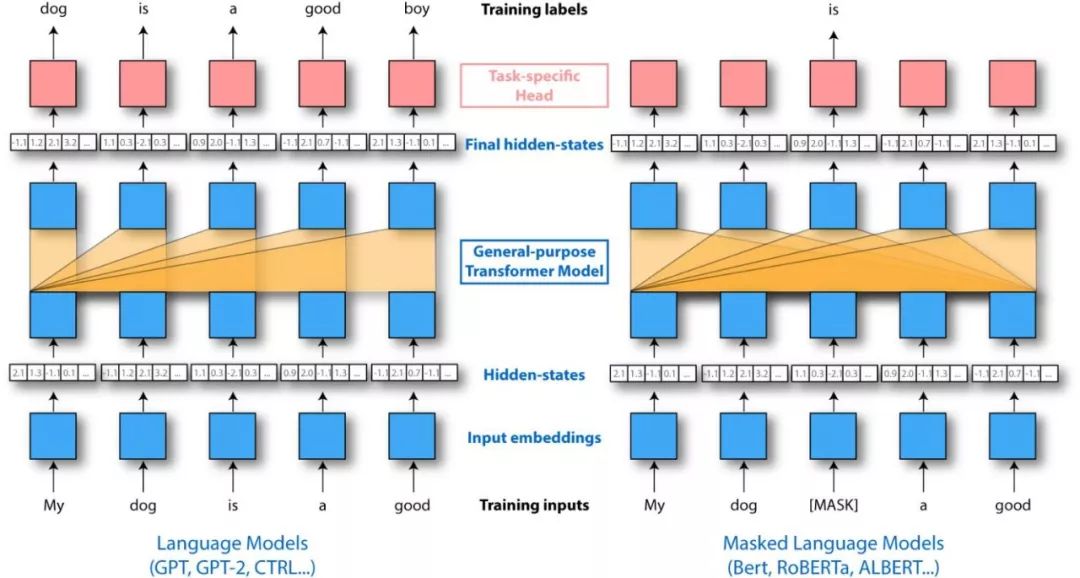
-
GPT is not bidirectional and has no concept of masking -
BERT incorporates a next sentence prediction task during training, so it also has segment embeddings
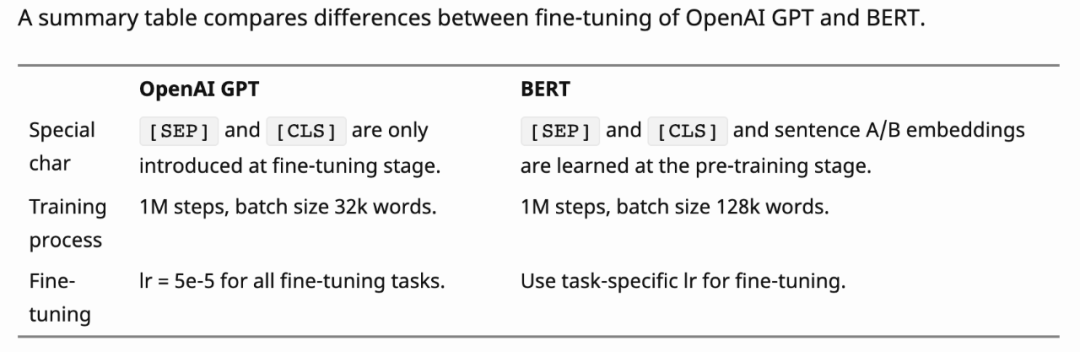
What are the differences between BERT and ALBERT v2?
-
Embedding matrix decomposition (helps reduce the number of parameters) -
No dropout -
Parameter sharing (helps reduce the number of parameters and provides regularization)
How does parameter sharing in ALBERT affect training and inference time?
No effect. Parameter sharing only reduces the number of parameters.
How to reduce the inference time of a trained neural network model?
-
Serve on GPU/TPU/FPGA -
16-bit quantization, deploy on GPUs that support fp16 -
Pruning to reduce parameters -
Knowledge distillation (for smaller transformer models or simpler neural networks) -
Hierarchical softmax -
You can also cache results; here’s an explanation.
Productionizing NLP Models: https://medium.com/modern-nlp/productionizing-nlp-models-9a2b8a0c7d14
Given this chart, would you choose a transformer model or an LSTM language model?
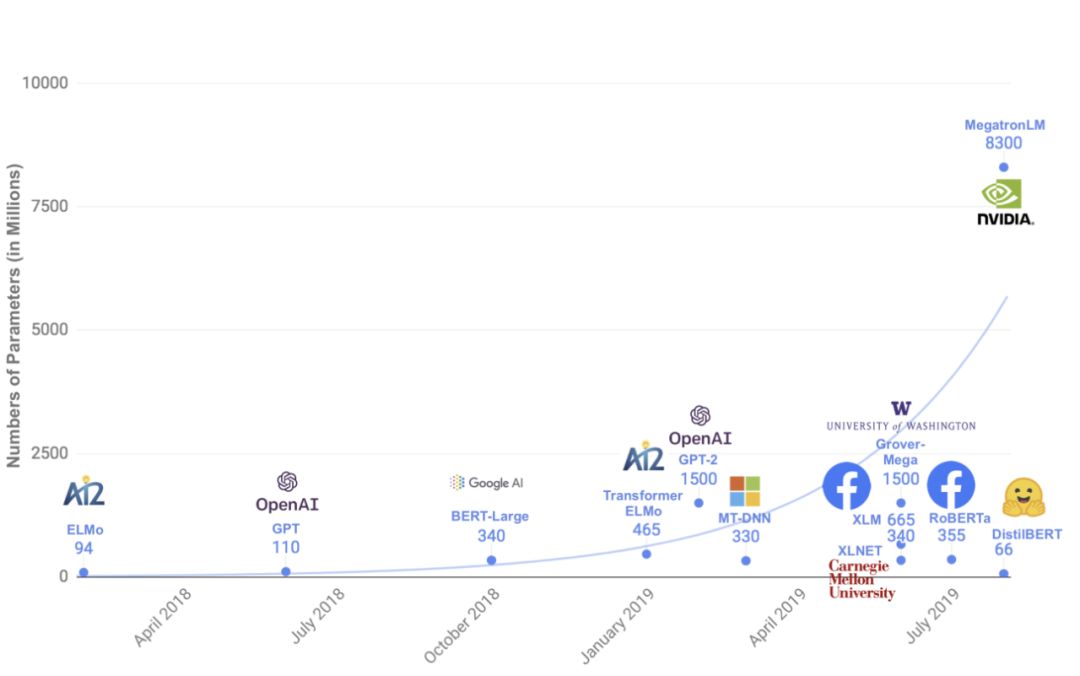
Would you combine BPE with classical models?
Of course! BPE is an intelligent token generator that helps us achieve a smaller vocabulary, which can help us find models with fewer parameters.
How to build an arxiv paper search engine? (Someone asked me – how to build a plagiarism detector?)
Use TF-IDF similarity to get the top k results, then use
-
Semantic encoding + cosine similarity -
A ranking model
On Semantic Search: https://medium.com/modern-nlp/semantic-search-fuck-yeah-e371c0f639d
How to build a sentiment classifier?
This is a brain teaser. Interviewees can say all sorts of things, like using transfer learning and the latest models, but they need to mention having a neutral class; otherwise, they can achieve good accuracy and f1 score, but the model will classify everything as positive or negative. In fact, many news articles are neutral, so the training needs to set up this category. Interviewees should also discuss how they would create a dataset and their training strategy, such as choosing a language model, fine-tuning the language model, and using various datasets for multi-task learning.
Recommended Reading:
The difference and relationship between fully connected graph convolutional networks (GCN) and self-attention
Complete Guide to Graph Convolutional Networks (GCN) for Beginners
Paper Review [ACL18] Self-Attentive Constituency Parsing
